Merge pull request #3747 from helinwang/dist_op
Design doc: operator based parameter server.
Showing
doc/design/ops/dist_train.md
0 → 100644
文件已添加
doc/design/ops/src/dist-graph.png
0 → 100644
{kind=link}
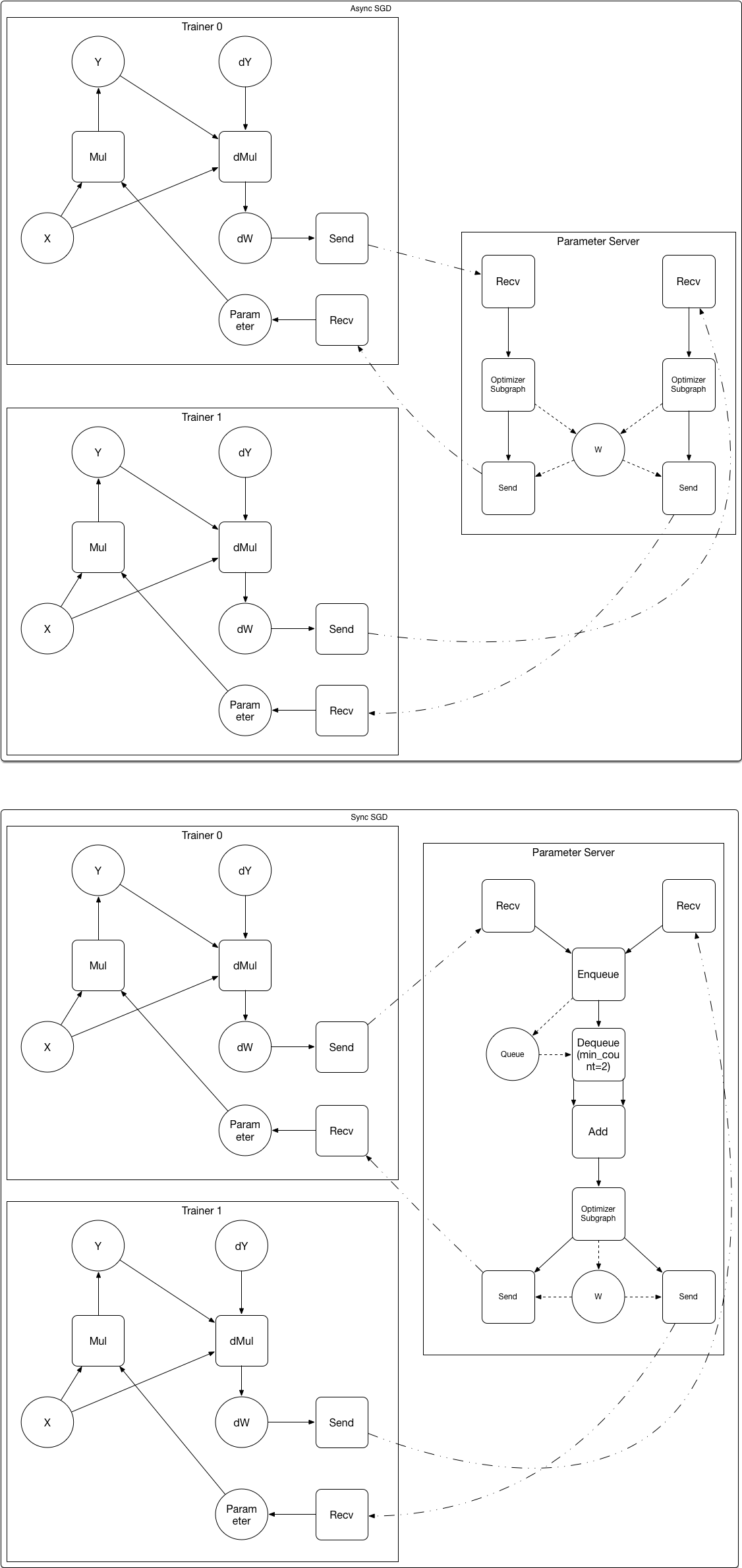
222.2 KB
文件已添加
{kind=link}
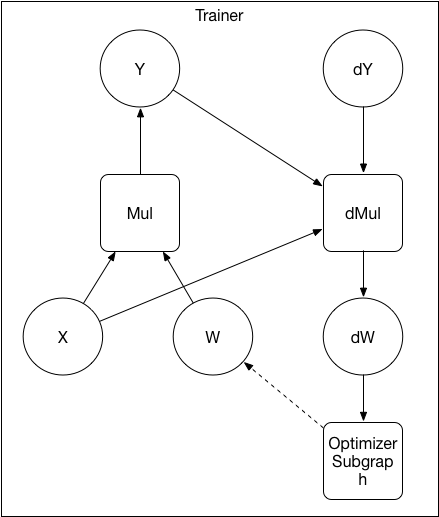
27.9 KB