Merge branch 'develop' of https://github.com/PaddlePaddle/Paddle into dist_train_benchmark_vgg16
Showing
cmake/external/boost.cmake
0 → 100644
doc/api/v2/fluid/gen_doc.py
0 → 100644
doc/api/v2/fluid/gen_doc.sh
0 → 100755
doc/design/csp.md
0 → 100644
{kind=link}
{kind=link}
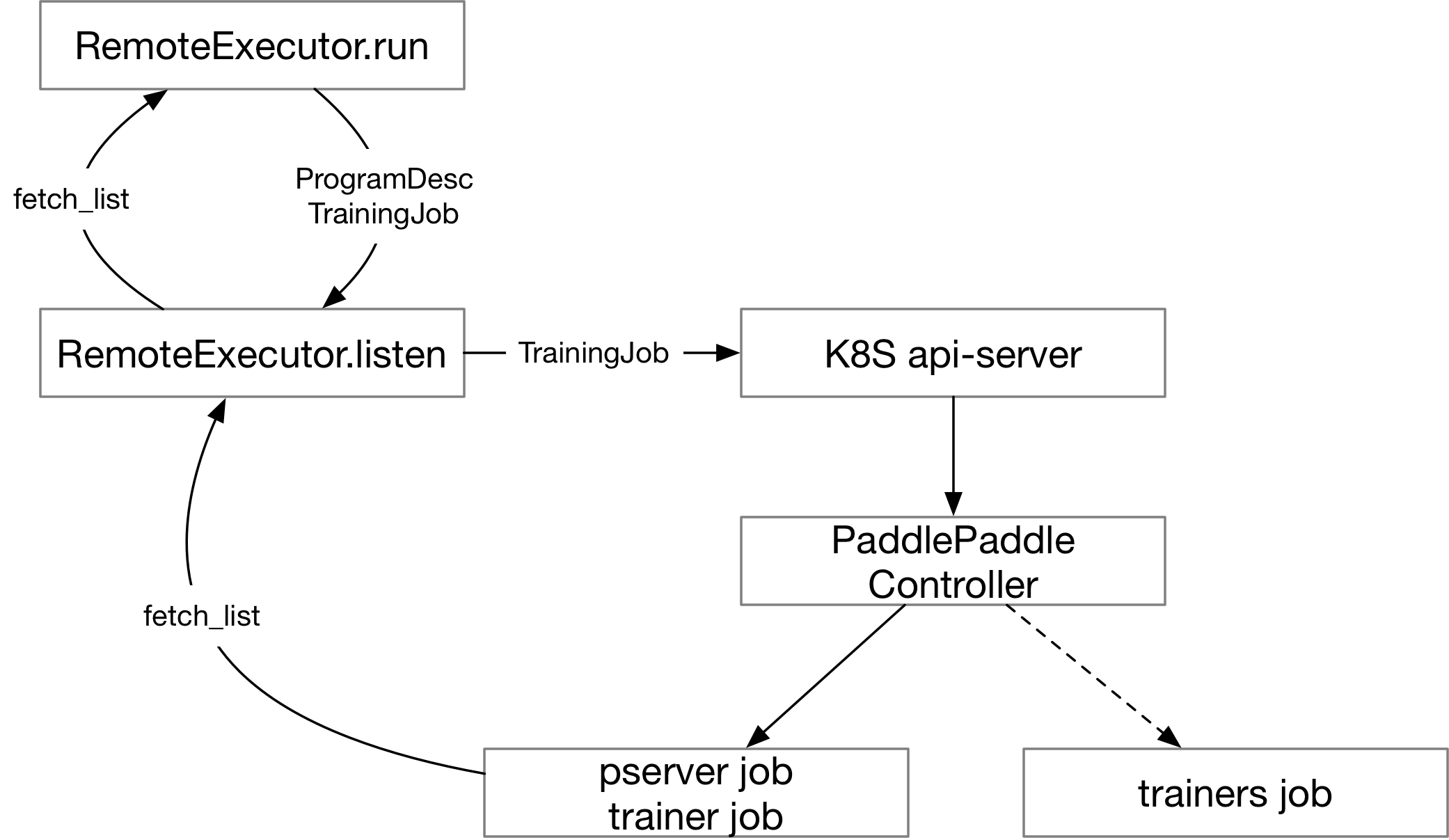
| W: | H:
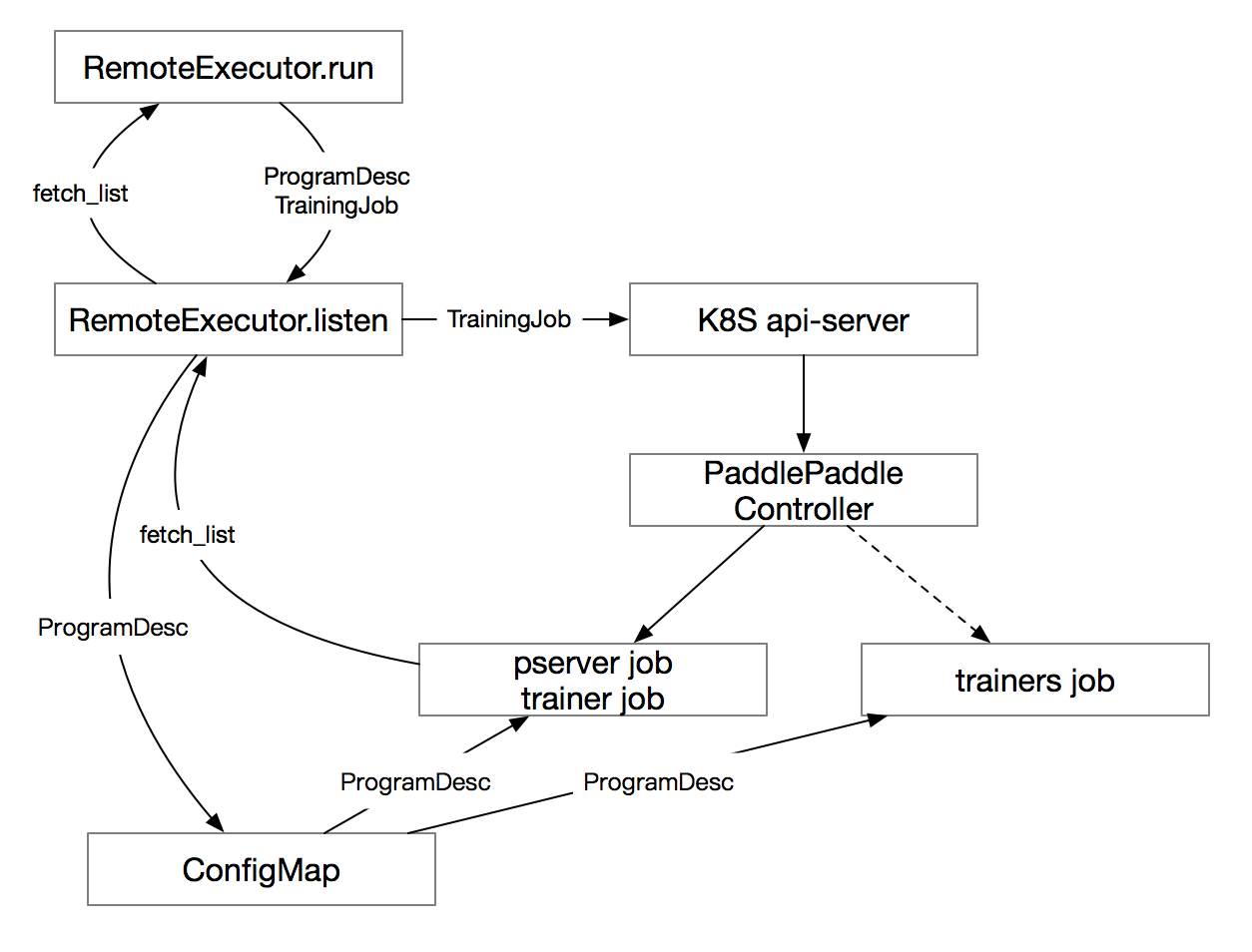
| W: | H:
{kind=link}

463.6 KB
paddle/framework/channel_test.cc
0 → 100644
paddle/framework/mixed_vector.h
0 → 100644
paddle/inference/example.cc
已删除
100644 → 0
paddle/inference/inference.cc
已删除
100644 → 0
paddle/inference/io.cc
0 → 100644
paddle/inference/io.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/im2sequence_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/layer_norm_op.cc
0 → 100644
此差异已折叠。
paddle/operators/layer_norm_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/operators/lstmp_op.cc
0 → 100644
此差异已折叠。
paddle/operators/lstmp_op.cu
0 → 100644
此差异已折叠。
paddle/operators/lstmp_op.h
0 → 100644
此差异已折叠。
paddle/operators/one_hot_op.cc
0 → 100644
此差异已折叠。
paddle/operators/one_hot_op.cu
0 → 100644
此差异已折叠。
paddle/operators/one_hot_op.h
0 → 100644
此差异已折叠。
paddle/operators/prior_box_op.cc
0 → 100644
此差异已折叠。
paddle/operators/prior_box_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。