Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
机器未来
Paddle
提交
8393c19c
P
Paddle
项目概览
机器未来
/
Paddle
与 Fork 源项目一致
Fork自
PaddlePaddle / Paddle
通知
1
Star
1
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
1
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
Paddle
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
1
Issue
1
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
8393c19c
编写于
11月 21, 2016
作者:
L
liaogang
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
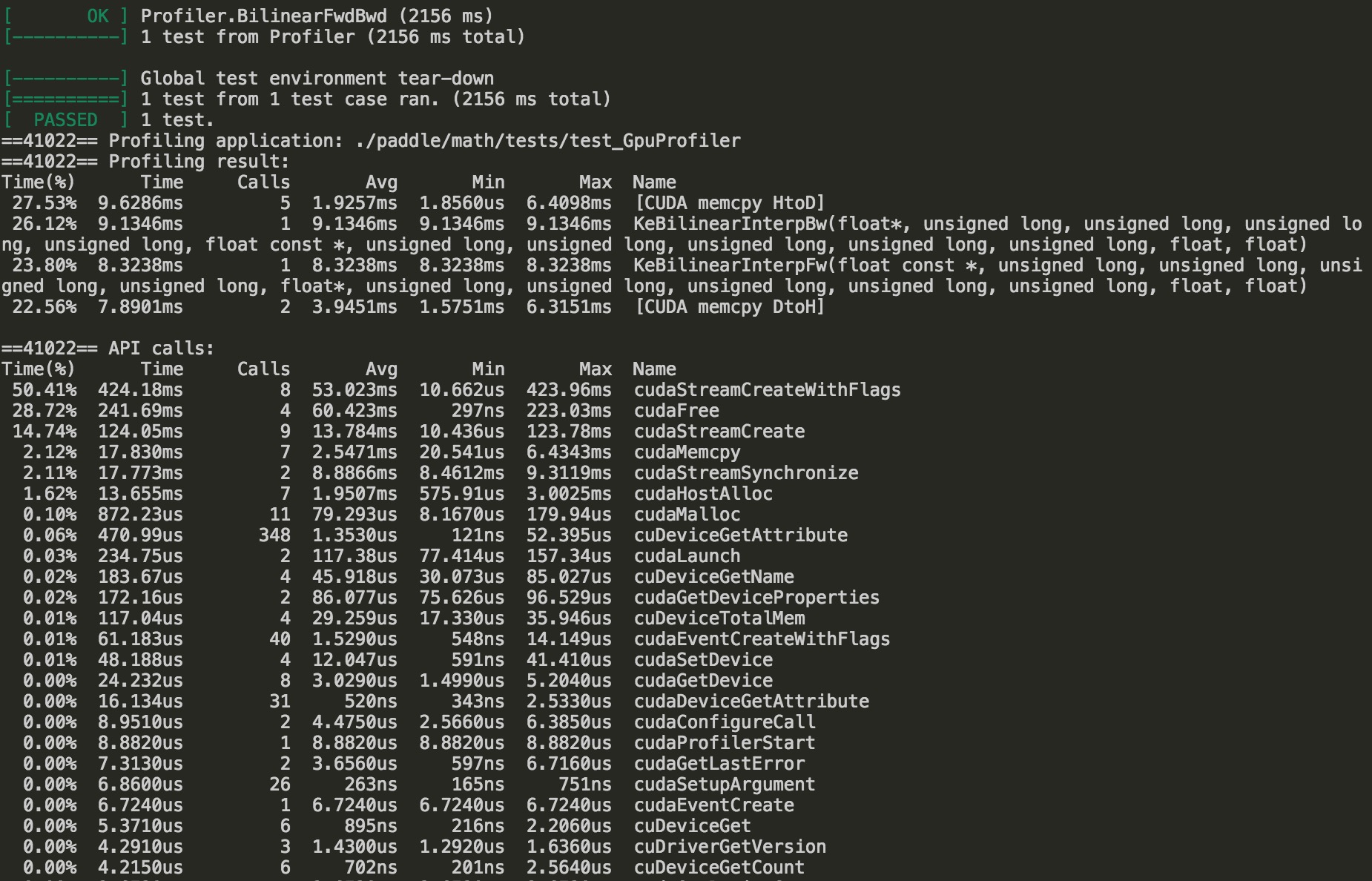
Add recursive mutex and counter for gpu profiler
上级
9670b9a1
变更
5
隐藏空白更改
内联
并排
Showing
5 changed file
with
42 addition
and
15 deletion
+42
-15
doc/optimization/gpu_profiling.rst
doc/optimization/gpu_profiling.rst
+2
-1
doc/optimization/nvprof.png
doc/optimization/nvprof.png
+0
-0
paddle/math/tests/test_GpuProfiler.cpp
paddle/math/tests/test_GpuProfiler.cpp
+16
-8
paddle/utils/Stat.cpp
paddle/utils/Stat.cpp
+18
-0
paddle/utils/Stat.h
paddle/utils/Stat.h
+6
-6
未找到文件。
doc/optimization/gpu_profiling.rst
浏览文件 @
8393c19c
...
...
@@ -24,7 +24,7 @@ Why we need profiling?
======================
Since training deep neural network typically take a very long time to get over, performance is gradually becoming
the most important thing in deep learning field. The first step to improve performance is to understand what parts
are slow.
N
o point in improving performance of a region which doesn’t take much time!
are slow.
There is n
o point in improving performance of a region which doesn’t take much time!
How to do profiling?
...
...
@@ -59,6 +59,7 @@ above profilers.
The above code snippet includes two methods, you can use any of them to profile the regions of interest.
1. :code:`REGISTER_TIMER_INFO` is a built-in timer wrapper which can calculate the time overhead of both cpu functions and cuda kernels.
2. :code:`REGISTER_GPU_PROFILER` is a general purpose wrapper object of :code:`cudaProfilerStart` and :code:`cudaProfilerStop` to avoid
program crashes when CPU version of PaddlePaddle invokes them.
...
...
doc/optimization/nvprof.png
已删除
100644 → 0
浏览文件 @
9670b9a1
476.3 KB
paddle/math/tests/test_GpuProfiler.cpp
浏览文件 @
8393c19c
...
...
@@ -70,10 +70,14 @@ void testBilinearFwdBwd(int numSamples, int imgSizeH, int imgSizeW,
input
->
randomizeUniform
();
inputGpu
->
copyFrom
(
*
input
);
target
->
bilinearForward
(
*
input
,
imgSizeH
,
imgSizeW
,
2
*
imgSizeH
,
2
*
imgSizeW
,
channels
,
ratioH
,
ratioW
);
targetGpu
->
bilinearForward
(
*
inputGpu
,
imgSizeH
,
imgSizeW
,
2
*
imgSizeH
,
2
*
imgSizeW
,
channels
,
ratioH
,
ratioW
);
{
// nvprof: GPU Proflier
REGISTER_GPU_PROFILER
(
"testBilinearFwdBwd"
);
target
->
bilinearForward
(
*
input
,
imgSizeH
,
imgSizeW
,
2
*
imgSizeH
,
2
*
imgSizeW
,
channels
,
ratioH
,
ratioW
);
targetGpu
->
bilinearForward
(
*
inputGpu
,
imgSizeH
,
imgSizeW
,
2
*
imgSizeH
,
2
*
imgSizeW
,
channels
,
ratioH
,
ratioW
);
}
// check
targetCheck
->
copyFrom
(
*
targetGpu
);
...
...
@@ -104,25 +108,29 @@ void testBilinearFwdBwd(int numSamples, int imgSizeH, int imgSizeW,
MatrixCheckErr
(
*
inputGrad
,
*
targetCheckGrad
);
}
TEST
(
Profiler
,
BilinearFwdBwd
)
{
TEST
(
Profiler
,
test
BilinearFwdBwd
)
{
auto
numSamples
=
10
;
auto
channels
=
16
;
auto
imgSize
=
64
;
{
// nvprof: GPU Proflier
REGISTER_GPU_PROFILER
(
"testBilinearFwdBwd"
,
"numSamples = 10, channels = 16, imgSizeX = 64, imgSizeY = 64"
);
REGISTER_GPU_PROFILER
(
"testBilinearFwdBwd"
);
// Paddle built-in timer
REGISTER_TIMER_INFO
(
"testBilinearFwdBwd"
,
"numSamples = 10, channels = 16, imgSizeX = 64, imgSizeY = 64"
);
testBilinearFwdBwd
(
numSamples
,
imgSize
,
imgSize
,
channels
);
}
globalStat
.
print
Status
(
"testBilinearFwdBwd"
);
globalStat
.
print
AllStatus
(
);
}
int
main
(
int
argc
,
char
**
argv
)
{
testing
::
InitGoogleTest
(
&
argc
,
argv
);
initMain
(
argc
,
argv
);
// nvprof: GPU Proflier
REGISTER_GPU_PROFILER
(
"RecursiveProfilingTest"
,
"numSamples = 10, channels = 16, imgSizeX = 64, imgSizeY = 64"
);
return
RUN_ALL_TESTS
();
}
...
...
paddle/utils/Stat.cpp
浏览文件 @
8393c19c
...
...
@@ -203,4 +203,22 @@ StatInfo::~StatInfo() {
}
}
static
unsigned
g_profileCount
=
0
;
static
std
::
recursive_mutex
g_profileMutex
;
GpuProfiler
::
GpuProfiler
(
std
::
string
statName
,
std
::
string
info
)
:
guard_
(
g_profileMutex
)
{
if
(
++
g_profileCount
==
1
)
{
LOG
(
INFO
)
<<
"Enable GPU Profiler Stat: ["
<<
statName
<<
"] "
<<
info
;
hl_profiler_start
();
}
}
GpuProfiler
::~
GpuProfiler
()
{
if
(
--
g_profileCount
==
0
)
{
hl_profiler_end
();
}
}
}
// namespace paddle
paddle/utils/Stat.h
浏览文件 @
8393c19c
...
...
@@ -283,8 +283,10 @@ inline StatSet& registerTimerArg2(uint64_t threshold = -1,
class
GpuProfiler
final
{
public:
GpuProfiler
()
{
hl_profiler_start
();
}
~
GpuProfiler
()
{
hl_profiler_end
();
}
GpuProfiler
(
std
::
string
statName
,
std
::
string
info
);
~
GpuProfiler
();
private:
std
::
lock_guard
<
std
::
recursive_mutex
>
guard_
;
};
#ifdef PADDLE_DISABLE_PROFILER
...
...
@@ -293,10 +295,8 @@ public:
#else
#define REGISTER_GPU_PROFILER(statName, ...) \
LOG(INFO) << "Enable GPU Profiler Stat: [" \
<< statName << "] " << #__VA_ARGS__; \
GpuProfiler __gpuProfiler;
#define REGISTER_GPU_PROFILER(statName, ...) \
GpuProfiler __gpuProfiler(statName, #__VA_ARGS__);
#endif // DISABLE_PROFILER
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}