@@ -54,17 +54,18 @@ The life cycle of a single task is illustrated below:
...
@@ -54,17 +54,18 @@ The life cycle of a single task is illustrated below:
<imgsrc="src/paddle-task-states.png"/>
<imgsrc="src/paddle-task-states.png"/>
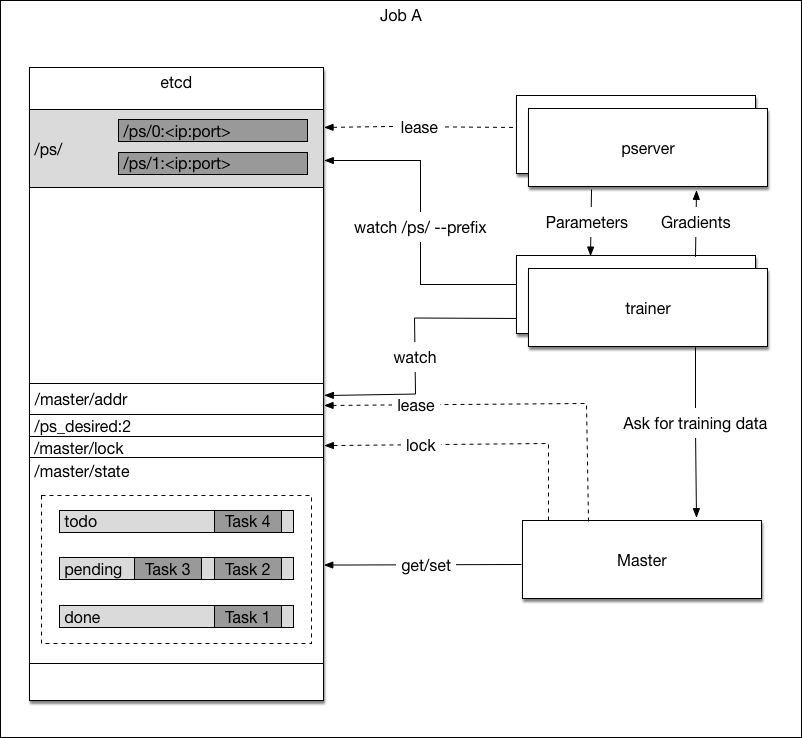
1. When a new pass of training starts, all tasks will be placed in the todo queue.
1. When a new pass of training starts, all tasks will be placed in the todo queue.
1.The master server will dispatch few tasks to each trainer at a time, puts them in the pending queue and waits for completion.
1.Upon trainer requests for new task, the master server will dispatch a task from todo queue to it, put the task in the pending queue and wait for completion.
1. The trainer will work on its tasks and tell the master server once a task is completed. The master server will dispatch a new task to that trainer.
1. The trainer will work on its task and tell the master server once the task is completed and ask for new task. The master server will dispatch a new task to that trainer.
1. If a task timeout. the master server will move it back to the todo queue. The timeout count will increase by one. If the timeout count is above a threshold, the task is likely to cause a trainer to crash, so it will be discarded.
1. If a task fails for any reason in trainer, or takes longer than a specific period of time, the master server will move the task back to the todo queue. The timeout count for that task will increase by one. If the timeout count is above a threshold, the task is likely to cause a trainer to crash, then it will be discarded.
1. The master server will move completed task to the done queue. When the todo queue is empty, the master server will start a new pass by moving all tasks in the done queue to todo queue and reset the timeout counter of all tasks to zero.
1. The master server will move completed task to the done queue. When the todo queue is empty, the master server will start a new pass by moving all tasks in the done queue to todo queue and reset the timeout counter of all tasks to zero.
### Trainer Process
### Trainer Process
The trainer process will:
The trainer process will:
- Receive tasks from the master.
- Request tasks from the master.
- Work on the tasks: calculate and upload gradient to parameter servers, and update local model by downloading new parameters from parameter servers.
- Work on the tasks
- Upload gradient to parameter servers, and update local model by downloading new parameters from parameter servers.
### Parameter Server Process
### Parameter Server Process
...
@@ -119,8 +120,8 @@ When the master is started by the Kubernetes, it executes the following steps at
...
@@ -119,8 +120,8 @@ When the master is started by the Kubernetes, it executes the following steps at
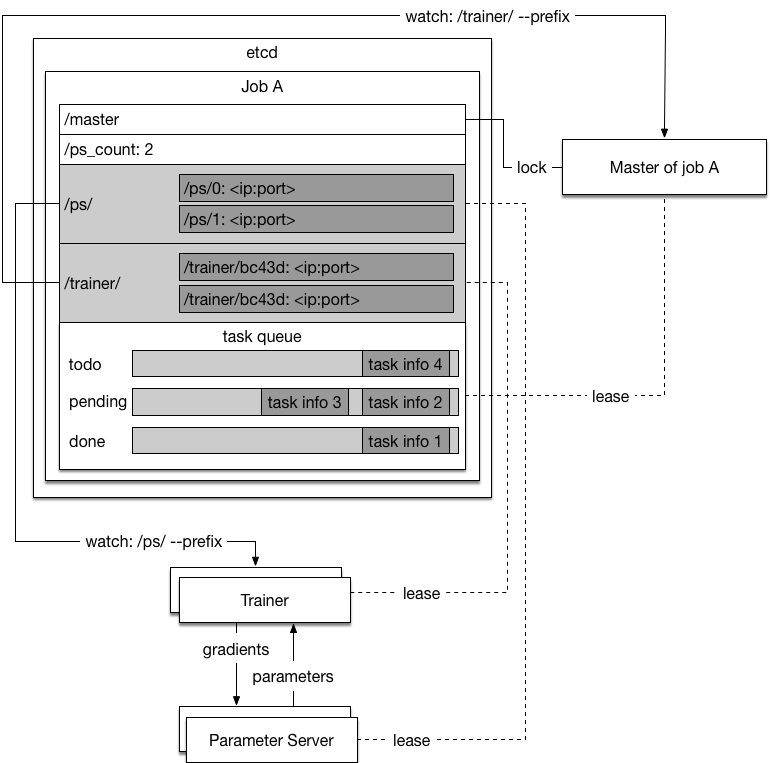
1. Grabs a unique *master* lock in etcd, which prevents concurrent master instantiations.
1. Grabs a unique *master* lock in etcd, which prevents concurrent master instantiations.
1. Recovers the task queues from etcd if they already exist, otherwise, the master will create them.
1. Recovers the task queues from etcd if they already exist, otherwise, the master will create them.
1. Watches the trainer prefix keys `/trainer/` on etcd to find the live trainers.
1. Write its ip address to */master/addr* so that trainers can discover it.
1.Starts dispatching the tasks to the trainers, and updates task queue using an etcd transaction to ensure lock is held during the update.
1.Listens to trainers' request of task, dispatch one upon request, and updates task queue using an etcd transaction to ensure lock is held during the update.
When the master server process is dead for any reason, Kubernetes will restart it. It will be online again with all states recovered from etcd in few minutes.
When the master server process is dead for any reason, Kubernetes will restart it. It will be online again with all states recovered from etcd in few minutes.
...
@@ -128,13 +129,11 @@ When the master server process is dead for any reason, Kubernetes will restart i
...
@@ -128,13 +129,11 @@ When the master server process is dead for any reason, Kubernetes will restart i
When the trainer is started by the Kubernetes, it executes the following steps at startup:
When the trainer is started by the Kubernetes, it executes the following steps at startup:
1. Watches the available parameter server prefix keys `/ps/` on etcd and waits until the count of parameter servers reaches the desired count.
1. Watches the available parameter server prefix keys `/ps/` on etcd and waits until the count of parameter servers reaches the desired count*/ps_desired*.
1.Generates a unique ID, and sets key `/trainer/<unique ID>` with its contact address as value. The key will be deleted when the lease expires, so the master will be aware of the trainer being online and offline.
1.Finds and watches */master/addr* to get master's address.
1.Waits for tasks from the master to start training.
1.Requests for tasks from the master to start training.
If trainer's etcd lease expires, it will try set key `/trainer/<unique ID>` again so that the master server can discover the trainer again.
When a trainer fails, Kuberentes would try to restart it. The recovered trainer would fetch tasks from master and go on training.
When a trainer fails, Kuberentes would try to restart it. The recovered trainer would fetch tasks from the TODO queue and go on training.
{kind=link}
{kind=link}