Merge branch 'develop' of https://github.com/PaddlePaddle/Paddle into infer_prog
Showing
adversarial/README.md
已删除
100644 → 0
adversarial/fluid_mnist.py
已删除
100644 → 0
cmake/external/boost.cmake
0 → 100644
doc/api/v1/index_cn.rst
已删除
100644 → 0
doc/api/v1/index_en.rst
已删除
100644 → 0
doc/design/csp.md
0 → 100644
doc/design/fluid_compiler.md
0 → 100644
doc/howto/dev/new_op_kernel_en.md
0 → 100644
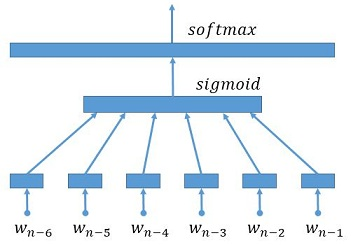
66.9 KB
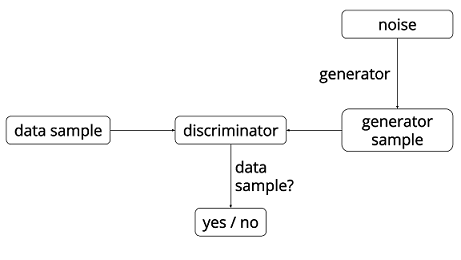
17.4 KB
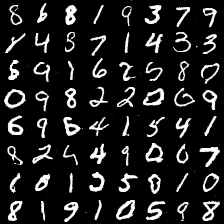
28.0 KB
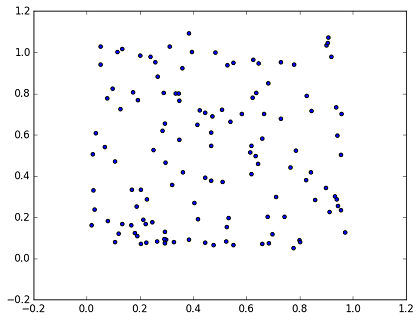
24.3 KB
21.9 KB
此差异已折叠。
35.0 KB
53.0 KB
43.0 KB
57.7 KB
29.6 KB
48.3 KB
45.3 KB

55.8 KB

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/ctc_align_op.cc
0 → 100644
此差异已折叠。
paddle/operators/ctc_align_op.cu
0 → 100644
此差异已折叠。
paddle/operators/ctc_align_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/im2sequence_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/math/sampler.cc
0 → 100644
此差异已折叠。
paddle/operators/math/sampler.h
0 → 100644
此差异已折叠。
paddle/operators/prior_box_op.cc
0 → 100644
此差异已折叠。
paddle/operators/prior_box_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
python/paddle/v2/dataset/wmt16.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。