merge with new change
Showing
{kind=link}
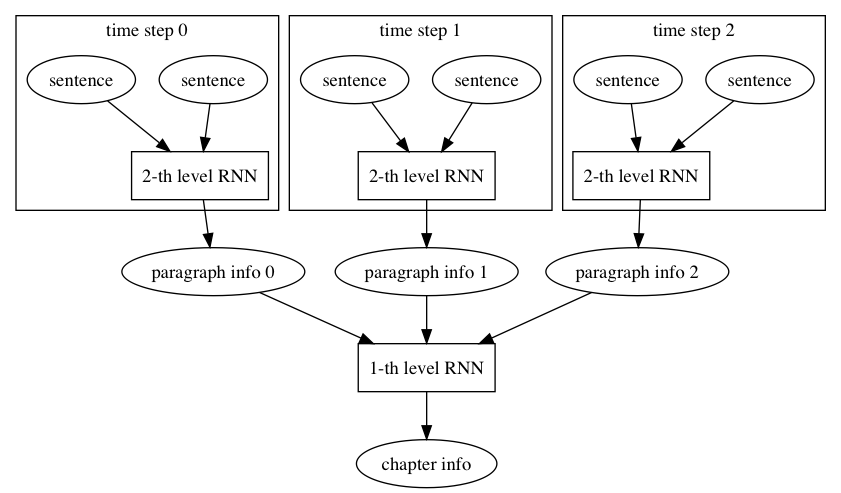
51.4 KB
doc/design/ops/images/rnn.dot
0 → 100644
doc/design/ops/images/rnn.jpg
0 → 100644
{kind=link}
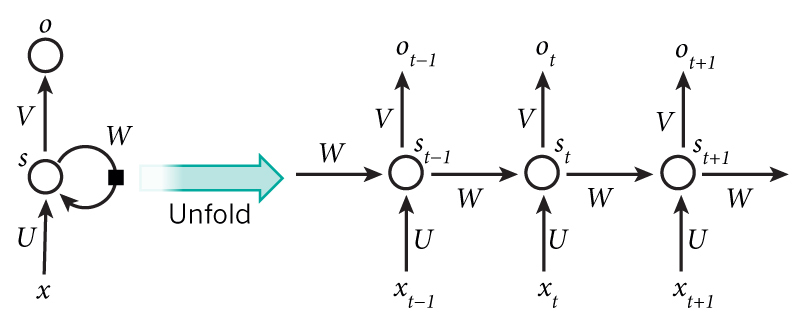
43.3 KB
doc/design/ops/images/rnn.png
0 → 100644
{kind=link}
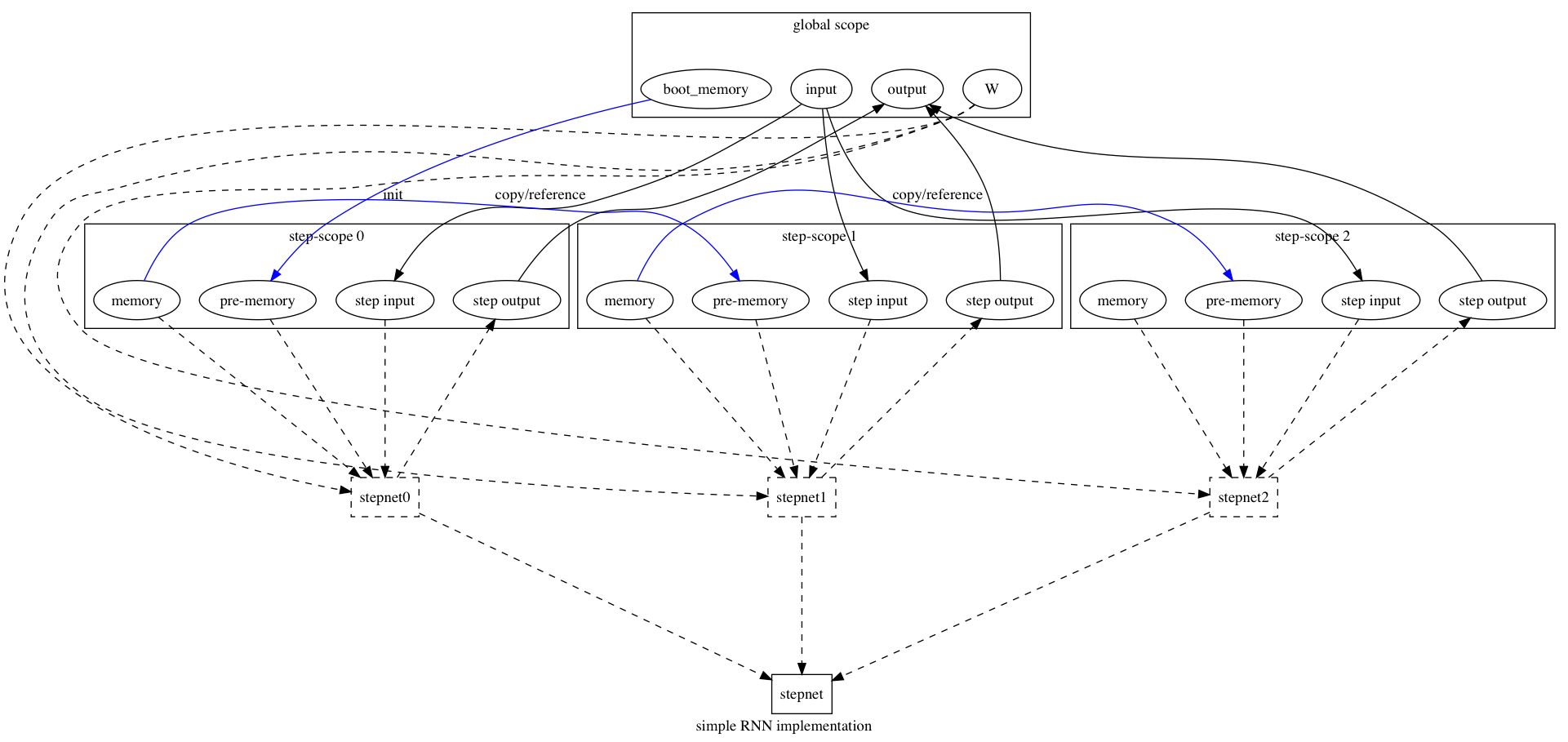
180.8 KB
{kind=link}
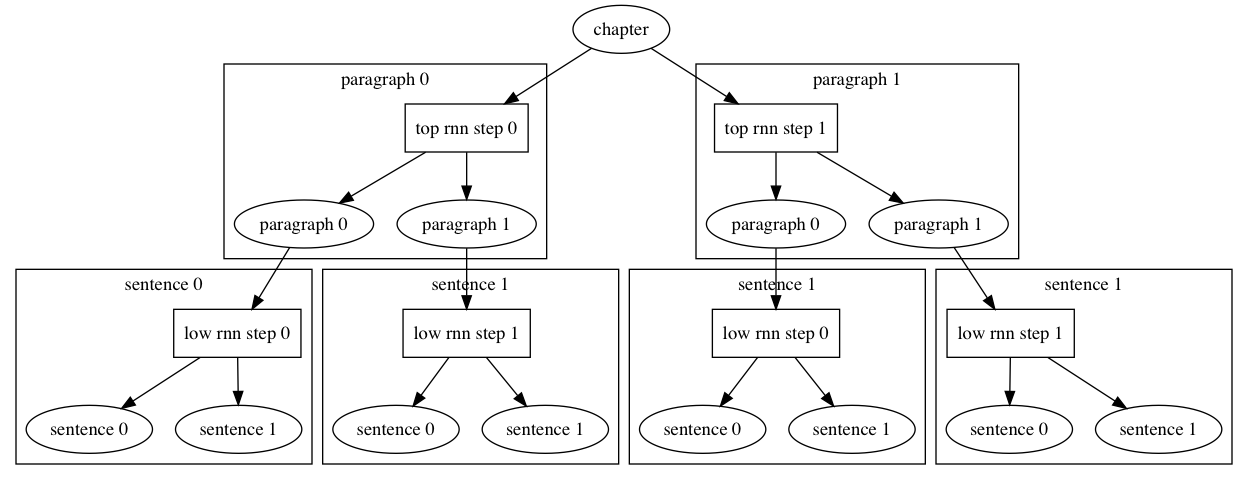
67.3 KB
doc/design/ops/rnn.md
0 → 100644
paddle/operators/accuracy_op.cc
0 → 100644
paddle/operators/accuracy_op.cu
0 → 100644
paddle/operators/accuracy_op.h
0 → 100644
paddle/operators/concat_op.cu
已删除
100644 → 0
文件已移动
文件已移动