
更新了部分文档和代码
Showing
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
文件已移动
{kind=link}
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
{kind=link}
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
Day91-100/项目部署上线指南.md
0 → 100644
此差异已折叠。
{kind=link}
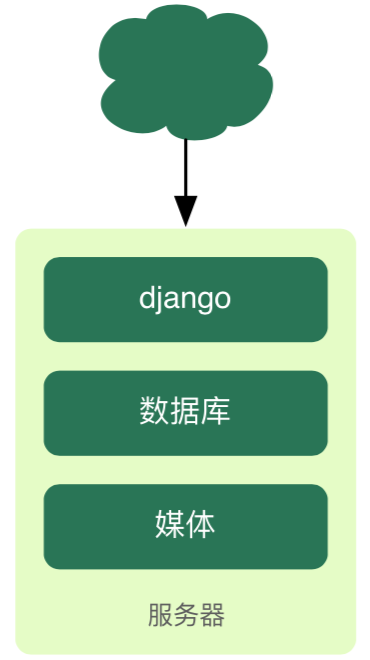
35.2 KB
{kind=link}
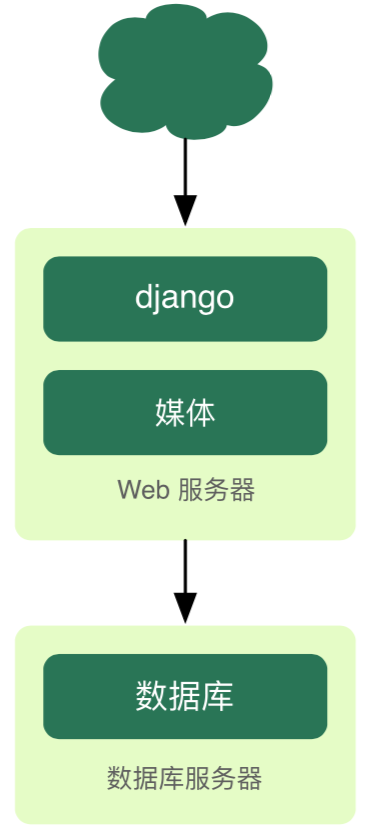
47.5 KB
{kind=link}
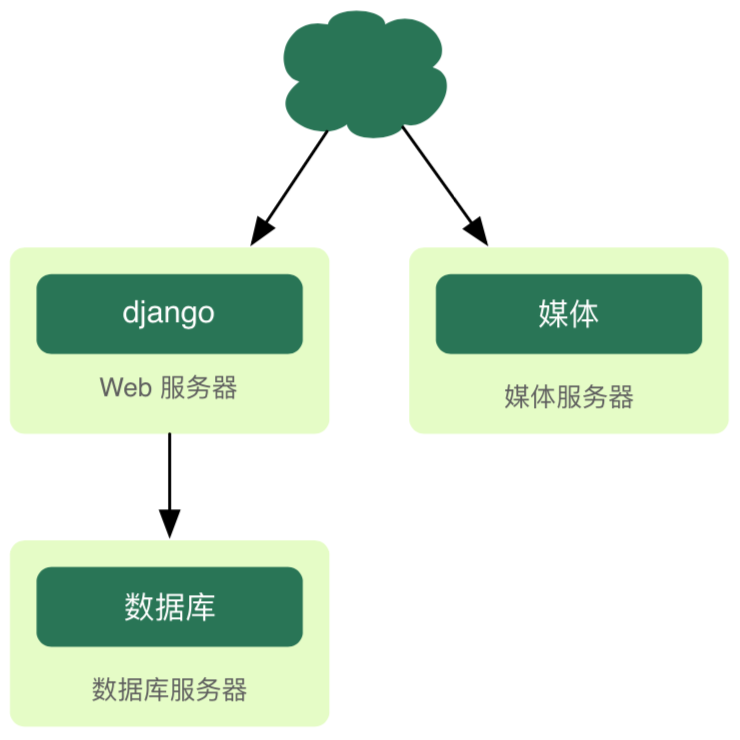
63.2 KB
{kind=link}
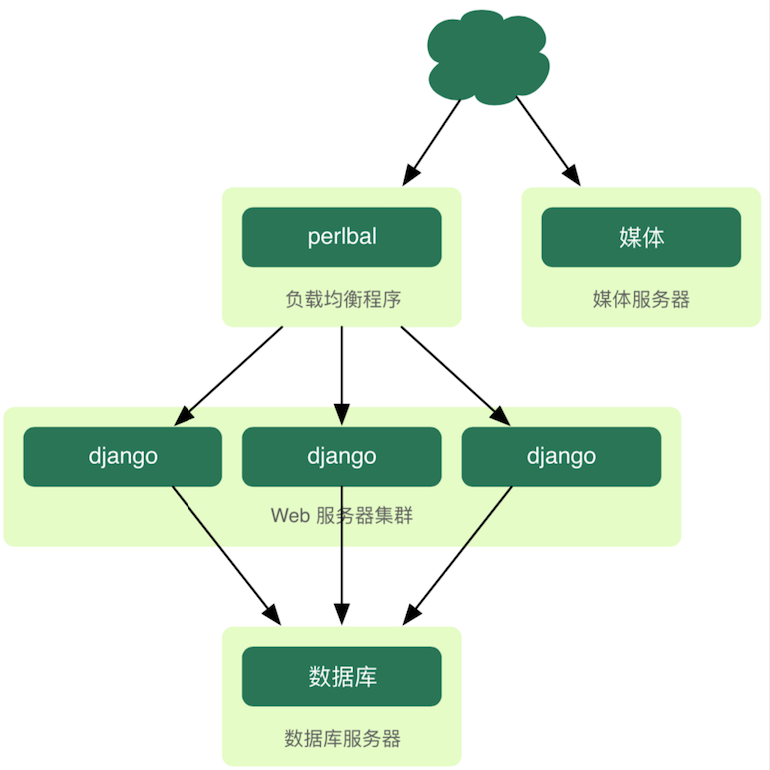
110.0 KB
{kind=link}
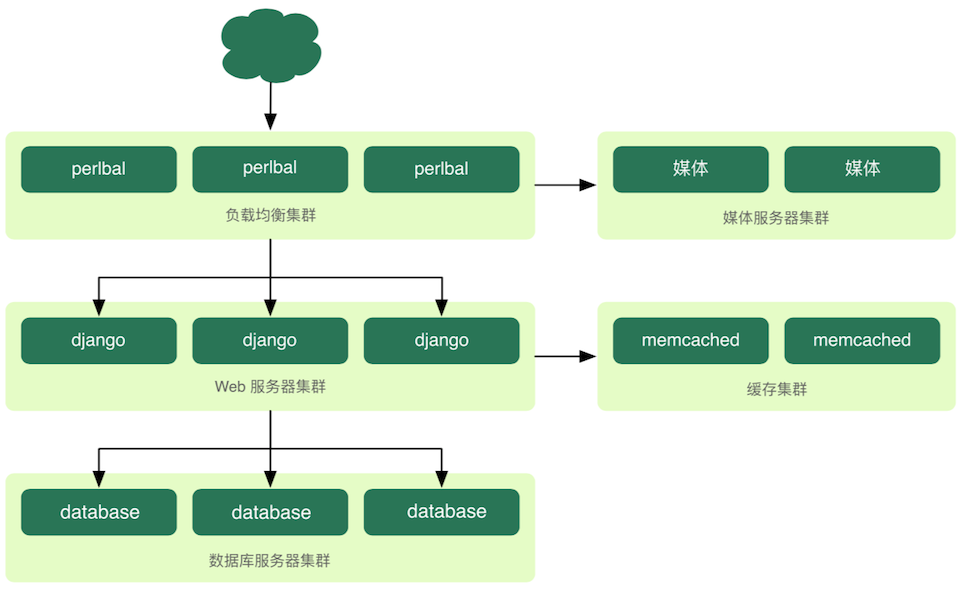
112.8 KB
{kind=link}
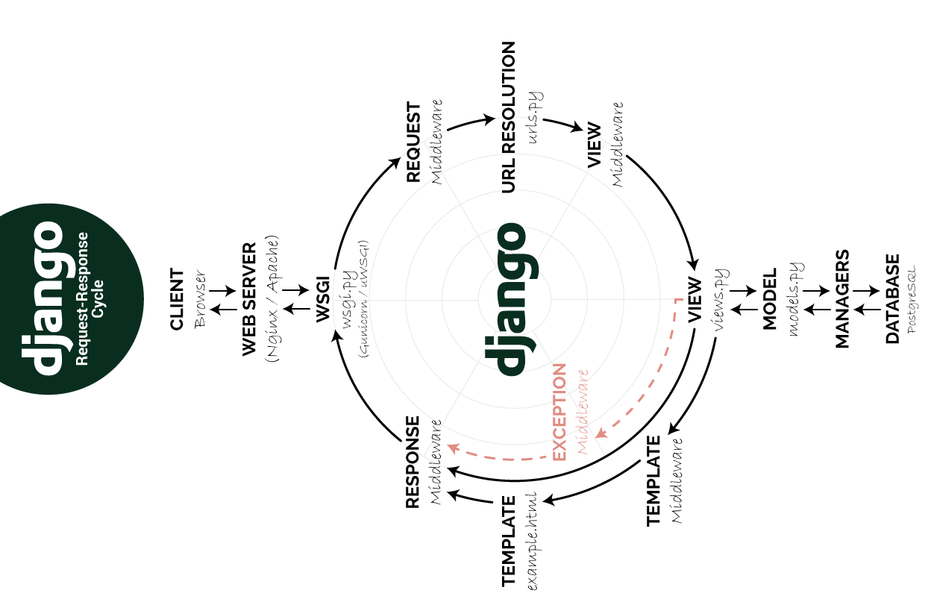
158.1 KB
res/hadoop_ecosystem.png
已删除
100644 → 0
{kind=link}
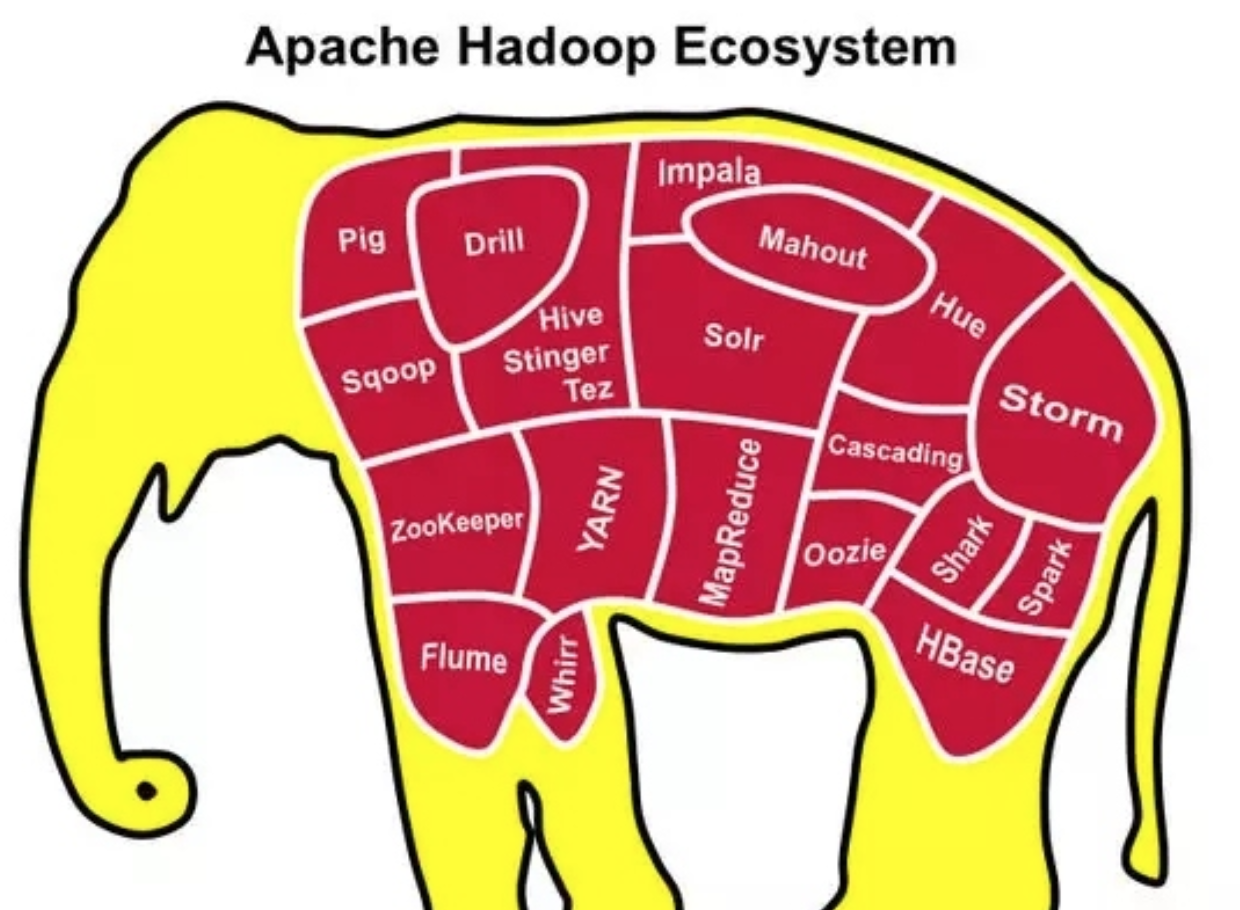
1.0 MB