Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
OpenDocCN
think-comp-2e-zh
提交
aec28d0e
T
think-comp-2e-zh
项目概览
OpenDocCN
/
think-comp-2e-zh
大约 1 年 前同步成功
通知
0
Star
16
Fork
7
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
T
think-comp-2e-zh
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
体验新版 GitCode,发现更多精彩内容 >>
提交
aec28d0e
编写于
4月 14, 2018
作者:
W
wizardforcel
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
12.
上级
9686e7e4
变更
3
隐藏空白更改
内联
并排
Showing
3 changed file
with
67 addition
and
0 deletion
+67
-0
12.md
12.md
+67
-0
img/12-1.png
img/12-1.png
+0
-0
img/12-2.png
img/12-2.png
+0
-0
未找到文件。
12.md
浏览文件 @
aec28d0e
...
...
@@ -256,3 +256,70 @@ def step(self):
我的模拟包含生存差异,就像第?章那样,但不包括繁殖差异。 你可以在本章的笔记本上看到细节。 作为练习之一,您将有机会探索繁殖差异的效果。
## 12.7 结果
假设我们从三个智能体开始:一个总是合作,一个总是背叛,另一个执行 TFT 策略。 如果我们在这个种群中运行
`Tournament.melee`
,合作者每轮获得 1.5 分,TFT 智能体获得 1.9 分,而背叛者获得 3.33 分。 这个结果表明,“总是背叛”应该很快成为主导策略。
但是“总是缺陷”包含着自我破坏的种子,如果更好的策略被驱使而灭绝,那么背叛者就没有人可以利用,他们的适应性下降,并且容易受到合作者的入侵。
根据这一分析,预测系统的行为不容易:它会找到一个稳定的平衡点,还是在基因型景观的各个位置之间振荡? 让我们运行模拟来发现它!
我以 100 个始终背叛的相同智能体开始,并运行 5000 个步骤的模拟:
```
py
tour
=
Tournament
()
agents
=
make_identical_agents
(
100
,
list
(
'DDDDDDD'
))
sim
=
PDSimulation
(
tour
,
agents
)
```

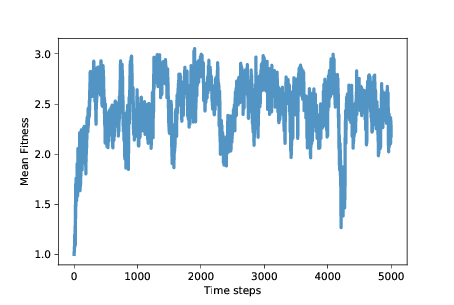
图 12.1:平均适应性(囚徒困境的每个回合的所得点数)
图?展示了随时间变化的平均适应性(使用第?章的
`MeanFitness`
仪器)。最初平均适应性是 1,因为当背叛者面对对方时,他们每轮只能得到 1 分。
经过大约 500 个时间步,平均适应性增加到近 3,这是合作者面对彼此时得到的。但是,正如我们所怀疑的那样,这种情况不稳定。在接下来的 500 个步骤中,平均适应性下降到 2 以下,回到 3,并继续振荡。
模拟的其余部分变化很大,但除了一次大的下降之外,平均适应性通常在 2 到 3 之间,长期平均值接近 2.5。
而且这还不错!它不是一个合作的乌托邦,每轮平均得 3 分,但距离始终背叛的乌托邦还很远。这比我们所期待的,自利智能体的自然选择要好得多。
为了深入了解这种适应性水平,我们来看看更多的仪器。
`Niceness`
在每个时间步骤之后测量智能体的基因型的合作比例:
```
py
class
Niceness
(
Instrument
):
def
update
(
self
,
sim
):
responses
=
np
.
array
([
agent
.
values
for
agent
in
sim
.
agents
])
metric
=
np
.
mean
(
responses
==
'C'
)
self
.
metrics
.
append
(
metric
)
```

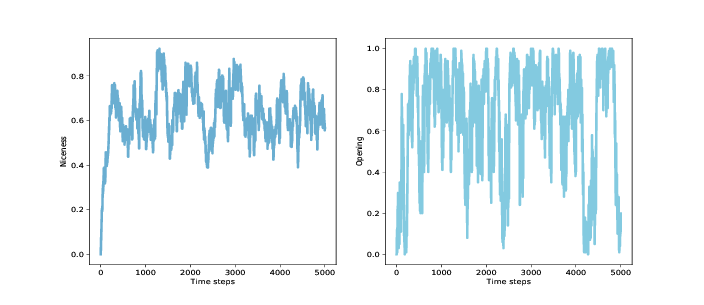
图 12.2:种群中所有基因组的平均友善度(左)和第一轮合作的种群比例(右)
图?(左图)展示结果:平均友善度从 0 迅速上升到 0.75,然后在 0.4 到 0.85 之间波动,长期平均值接近 0.65。 同样,这相当好!
具体看开始的移动,我们可以追踪第一轮合作的智能体的比例。 这是这个仪器:
```
py
class
Retaliating
(
Instrument
):
def
update
(
self
,
sim
):
after_d
=
np
.
array
([
agent
.
values
[
2
::
2
]
for
agent
in
sim
.
agents
])
after_c
=
np
.
array
([
agent
.
values
[
1
::
2
]
for
agent
in
sim
.
agents
])
metric
=
np
.
mean
(
after_d
==
'D'
)
-
np
.
mean
(
after_c
==
'D'
)
self
.
metrics
.
append
(
metric
)
```
报复行为将所有基因组中的元素数量,其中对手背叛后智能体也背叛(元素 2, 4 和 6),与其中的元素数量,其中对手合作后智能体背叛相比较。正如您现在的预期,结果差异很大(您可以在笔记本中看到图形)。平均而言,这些分数之间的差异小于 0.1,所以如果智能体在对手合作后,30% 的时间中背叛,他们可能会在背叛后的 40% 时间中背叛。
这个结果为这个断言提供了较弱的支持,即成功的策略会报复。也许所有智能体甚至很多智能体都没有必要进行报复;如果整个种群中至少存在一定的报复倾向,那么这可能足以阻止高度报复策略的普及。
为了衡量宽恕,我再次定义了一个工具,来查看在前两轮之后,智能体是否更有可能在 D-C 之后进行合作,与 C-D 相比。在我的模拟中,没有证据表明这种特殊的宽恕。另一方面,这些模拟中的策略在某种意义上是必然的宽容,因为它们只考虑前两轮的历史。
img/12-1.png
0 → 100644
浏览文件 @
aec28d0e
9.3 KB
img/12-2.png
0 → 100644
浏览文件 @
aec28d0e
14.7 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}