Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
OpenDocCN
sklearn-doc-zh
提交
57e1fa86
S
sklearn-doc-zh
项目概览
OpenDocCN
/
sklearn-doc-zh
通知
3
Star
3
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
S
sklearn-doc-zh
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
未验证
提交
57e1fa86
编写于
10月 09, 2019
作者:
L
loopyme
提交者:
GitHub
10月 09, 2019
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
[校验] 1.1 广义线性模型 (0.21.3) (#382)
- 校正了两个表达式 - 做了一些格式调整
上级
a13beaee
变更
3
隐藏空白更改
内联
并排
Showing
3 changed file
with
7 addition
and
9 deletion
+7
-9
docs/0.21.3/2.md
docs/0.21.3/2.md
+7
-9
docs/0.21.3/img/1_1_1.gif
docs/0.21.3/img/1_1_1.gif
+0
-0
docs/0.21.3/img/1_1_2.gif
docs/0.21.3/img/1_1_2.gif
+0
-0
未找到文件。
docs/0.21.3/2.md
浏览文件 @
57e1fa86
...
@@ -47,7 +47,7 @@ array([ 0.5, 0.5])
...
@@ -47,7 +47,7 @@ array([ 0.5, 0.5])
### 1.1.1.1. 普通最小二乘法的复杂度
### 1.1.1.1. 普通最小二乘法的复杂度
该方法使用 X 的奇异值分解来计算最小二乘解。如果 X 是一个
size 为 (n_samples, n_features) 的矩阵,设 !
[
n_samples \geq n_features
](
img/1_1_1.gif
)
,则该方法的复杂度为 !
[
O(n_samples n_fearures^2)
](
img/1_1_2.gif
)
该方法使用 X 的奇异值分解来计算最小二乘解。如果 X 是一个
形状为
`(n_samples, n_features)`
的矩阵,设$$n_{samples}
\g
eq n_{features}$$, 则该方法的复杂度为$$O(n_{samples} n_{fearures}^2)$$
## 1.1.2. 岭回归
## 1.1.2. 岭回归
...
@@ -298,9 +298,7 @@ Lars 算法提供了一个几乎无代价的沿着正则化参数的系数的完
...
@@ -298,9 +298,7 @@ Lars 算法提供了一个几乎无代价的沿着正则化参数的系数的完
## 1.1.9. 正交匹配追踪法(OMP)
## 1.1.9. 正交匹配追踪法(OMP)
> [`OrthogonalMatchingPursuit`](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.OrthogonalMatchingPursuit.html#sklearn.linear_model.OrthogonalMatchingPursuit) (正交匹配追踪法)和 [`orthogonal_mp`](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.orthogonal_mp.html#sklearn.linear_model.orthogonal_mp)
[
`OrthogonalMatchingPursuit`
](
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.OrthogonalMatchingPursuit.html#sklearn.linear_model.OrthogonalMatchingPursuit
)
(
正交匹配追踪法
)
和
[
`orthogonal_mp`
](
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.orthogonal_mp.html#sklearn.linear_model.orthogonal_mp
)
使用了 OMP 算法近似拟合了一个带限制的线性模型,该限制影响于模型的非 0 系数(例:L0 范数)。
使用了 OMP 算法近似拟合了一个带限制的线性模型,该限制影响于模型的非 0 系数(例:L0 范数)。
就像最小角回归一样,作为一个前向特征选择方法,正交匹配追踪法可以近似一个固定非 0 元素的最优向量解:
就像最小角回归一样,作为一个前向特征选择方法,正交匹配追踪法可以近似一个固定非 0 元素的最优向量解:
...
@@ -351,7 +349,7 @@ Alpha 在这里也是作为一个变量,通过数据中估计得到。
...
@@ -351,7 +349,7 @@ Alpha 在这里也是作为一个变量,通过数据中估计得到。
### 1.1.10.1. 贝叶斯岭回归
### 1.1.10.1. 贝叶斯岭回归
>
[`BayesianRidge`](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.BayesianRidge.html#sklearn.linear_model.BayesianRidge) 利用概率模型估算了上述的回归问题,其先验参数  是由以下球面高斯公式得出的:
[
`BayesianRidge`
](
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.BayesianRidge.html#sklearn.linear_model.BayesianRidge
)
利用概率模型估算了上述的回归问题,其先验参数 !
[
w
](
img/8a58e8df6a985a3273e39bac7dd72b1f.jpg
)
是由以下球面高斯公式得出的:


...
@@ -408,7 +406,7 @@ array([ 0.49999993, 0.49999993])
...
@@ -408,7 +406,7 @@ array([ 0.49999993, 0.49999993])
### 1.1.10.2. 主动相关决策理论 - ARD
### 1.1.10.2. 主动相关决策理论 - ARD
>
[`ARDRegression`](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.ARDRegression.html#sklearn.linear_model.ARDRegression) (主动相关决策理论)和 [`Bayesian Ridge Regression`](https://scikit-learn.org/stable/modules/linear_model.html#id13) 非常相似,但是会导致一个更加稀疏的权重w[[1]](https://scikit-learn.org/stable/modules/linear_model.html#id18)[[2]](https://scikit-learn.org/stable/modules/linear_model.html#id19) 。
[
`ARDRegression`
](
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.ARDRegression.html#sklearn.linear_model.ARDRegression
)
(主动相关决策理论)和
[
`Bayesian Ridge Regression`
](
https://scikit-learn.org/stable/modules/linear_model.html#id13
)
非常相似,但是会导致一个更加稀疏的权重w
[
[1]
](
https://scikit-learn.org/stable/modules/linear_model.html#id18
)[
[2
]
](https://scikit-learn.org/stable/modules/linear_model.html#id19) 。
[
`ARDRegression`
](
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.ARDRegression.html#sklearn.linear_model.ARDRegression
)
提出了一个不同的 !
[
w
](
img/8a58e8df6a985a3273e39bac7dd72b1f.jpg
)
的先验假设。具体来说,就是弱化了高斯分布为球形的假设。
[
`ARDRegression`
](
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.ARDRegression.html#sklearn.linear_model.ARDRegression
)
提出了一个不同的 !
[
w
](
img/8a58e8df6a985a3273e39bac7dd72b1f.jpg
)
的先验假设。具体来说,就是弱化了高斯分布为球形的假设。
...
@@ -443,7 +441,7 @@ logistic 回归,虽然名字里有 “回归” 二字,但实际上是解决
...
@@ -443,7 +441,7 @@ logistic 回归,虽然名字里有 “回归” 二字,但实际上是解决
scikit-learn 中 logistic 回归在
[
`LogisticRegression`
](
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html#sklearn.linear_model.LogisticRegression
)
类中实现了二分类(binary)、一对多分类(one-vs-rest)及多项式 logistic 回归,并带有可选的 L1 和 L2 正则化。
scikit-learn 中 logistic 回归在
[
`LogisticRegression`
](
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html#sklearn.linear_model.LogisticRegression
)
类中实现了二分类(binary)、一对多分类(one-vs-rest)及多项式 logistic 回归,并带有可选的 L1 和 L2 正则化。
注意,scikit-learn的逻辑回归在默认情况下使用L2正则化,这样的方式在机器学习领域是常见的,在统计分析领域是不常见的。正则化的另一优势是提升数值稳定性。scikit-learn通过将C设置为很大的值实现无正则化。
>
注意,scikit-learn的逻辑回归在默认情况下使用L2正则化,这样的方式在机器学习领域是常见的,在统计分析领域是不常见的。正则化的另一优势是提升数值稳定性。scikit-learn通过将C设置为很大的值实现无正则化。
作为优化问题,带 L2罚项的二分类 logistic 回归要最小化以下代价函数(cost function):
作为优化问题,带 L2罚项的二分类 logistic 回归要最小化以下代价函数(cost function):
...
@@ -499,7 +497,7 @@ Elastic-Net正则化是L1 和 L2的组合,来使如下代价函数最小:
...
@@ -499,7 +497,7 @@ Elastic-Net正则化是L1 和 L2的组合,来使如下代价函数最小:
>* [newgroups20上的多类稀疏Logistic回归](https://scikit-learn.org/stable/auto_examples/linear_model/plot_sparse_logistic_regression_20newsgroups.html)
>* [newgroups20上的多类稀疏Logistic回归](https://scikit-learn.org/stable/auto_examples/linear_model/plot_sparse_logistic_regression_20newsgroups.html)
>* [使用多项式Logistic回归和L1进行MNIST数据集的分类](https://scikit-learn.org/stable/auto_examples/linear_model/plot_sparse_logistic_regression_mnist.html)
>* [使用多项式Logistic回归和L1进行MNIST数据集的分类](https://scikit-learn.org/stable/auto_examples/linear_model/plot_sparse_logistic_regression_mnist.html)
>
与 `liblinear` 的区别:
>
**与 `liblinear` 的区别:**
>
>
>当 `fit_intercept=False` 拟合得到的 `coef_` 或者待预测的数据为零时,用 `solver=liblinear` 的 [`LogisticRegression`](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html#sklearn.linear_model.LogisticRegression) 或 `LinearSVC` 与直接使用外部 liblinear 库预测得分会有差异。这是因为, 对于 `decision_function` 为零的样本, [`LogisticRegression`](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html#sklearn.linear_model.LogisticRegression) 和 `LinearSVC` 将预测为负类,而 liblinear 预测为正类。 注意,设定了 `fit_intercept=False` ,又有很多样本使得 `decision_function` 为零的模型,很可能会欠拟合,其表现往往比较差。建议您设置 `fit_intercept=True` 并增大 `intercept_scaling` 。
>当 `fit_intercept=False` 拟合得到的 `coef_` 或者待预测的数据为零时,用 `solver=liblinear` 的 [`LogisticRegression`](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html#sklearn.linear_model.LogisticRegression) 或 `LinearSVC` 与直接使用外部 liblinear 库预测得分会有差异。这是因为, 对于 `decision_function` 为零的样本, [`LogisticRegression`](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html#sklearn.linear_model.LogisticRegression) 和 `LinearSVC` 将预测为负类,而 liblinear 预测为正类。 注意,设定了 `fit_intercept=False` ,又有很多样本使得 `decision_function` 为零的模型,很可能会欠拟合,其表现往往比较差。建议您设置 `fit_intercept=True` 并增大 `intercept_scaling` 。
...
@@ -790,4 +788,4 @@ array([0, 1, 1, 0])
...
@@ -790,4 +788,4 @@ array([0, 1, 1, 0])
1.0
1.0
```
```
{% endraw %}
{% endraw %}
\ No newline at end of file
docs/0.21.3/img/1_1_1.gif
已删除
100644 → 0
浏览文件 @
a13beaee
774 字节
docs/0.21.3/img/1_1_2.gif
已删除
100644 → 0
浏览文件 @
a13beaee
640 字节
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
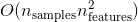
{kind=link}
