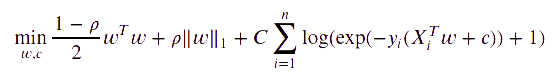Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
OpenDocCN
sklearn-doc-zh
提交
3fde811a
S
sklearn-doc-zh
项目概览
OpenDocCN
/
sklearn-doc-zh
通知
3
Star
3
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
S
sklearn-doc-zh
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
3fde811a
编写于
6月 04, 2019
作者:
L
loopyme
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
调整公式
上级
f7a602d7
变更
2
隐藏空白更改
内联
并排
Showing
2 changed file
with
7 addition
and
19 deletion
+7
-19
docs/2.md
docs/2.md
+7
-19
docs/img/021new1.jpg
docs/img/021new1.jpg
+0
-0
未找到文件。
docs/2.md
浏览文件 @
3fde811a
<script
type=
"text/x-mathjax-config"
>
MathJax.Hub.Config({
tex2jax: {
inlineMath: [ ['$','$'], ['
\\
(','
\\
)'] ],
processEscapes: true
}
});
</script>
<script
type=
"text/javascript"
async
src=
"//cdn.mathjax.org/mathjax/latest/MathJax.js?config=TeX-MML-AM_CHTML"
>
</script>
# 1.1\. 广义线性模型
校验者:
...
...
@@ -453,7 +441,7 @@ logistic 回归,虽然名字里有 “回归” 二字,但实际上是解决
scikit-learn 中 logistic 回归在
[
`LogisticRegression`
](
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html#sklearn.linear_model.LogisticRegression
)
类中实现了二分类(binary)、一对多分类(one-vs-rest)及多项式 logistic 回归,并带有可选的 L1 和 L2 正则化。
作为优化问题,带
$l_2$
罚项的二分类 logistic 回归要最小化以下代价函数(cost function):
作为优化问题,带
L2
罚项的二分类 logistic 回归要最小化以下代价函数(cost function):

...
...
@@ -461,19 +449,19 @@ scikit-learn 中 logistic 回归在 [`LogisticRegression`](https://scikit-learn.

Elastic-Net正则化是L1 和 L2的组合,来使
以
下代价函数最小:
Elastic-Net正则化是L1 和 L2的组合,来使
如
下代价函数最小:
$$
\m
in_{w, c}
\f
rac{1 -
\r
ho}{2}w^T w +
\r
ho
\|
w
\|
_1 + C \sum_
{i=1}^n
\l
og(
\e
xp(- y_i (X_i^T w + c)) + 1) $$

其中
$
\r
ho$控制正则化$l_1$与正则化$l_2$
的强度(对应于
`l1_ratio`
参数)。
其中
ρ控制正则化L1与正则化L2
的强度(对应于
`l1_ratio`
参数)。
注意,在这个表示法中,假定目标
$y_i$在测试时属于集合
\[
-1,1
\]
。我们还可以发现Elastic-Net在$
\r
ho=1$时与$l_1$罚项等价,在$
\r
ho=0$时与$l_2$
罚项等价
注意,在这个表示法中,假定目标
y_i在测试时属于集合
\[
-1,1
\]
。我们还可以发现Elastic-Net在ρ=1时与L1罚项等价,在ρ=0时与L2
罚项等价
在
[
`LogisticRegression`
](
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html#sklearn.linear_model.LogisticRegression
)
类中实现了这些优化算法:
`liblinear`
,
`newton-cg`
,
`lbfgs`
,
`sag`
和
`saga`
。
`liblinear`
应用了坐标下降算法(Coordinate Descent, CD),并基于 scikit-learn 内附的高性能 C++ 库
[
LIBLINEAR library
](
http://www.csie.ntu.edu.tw/~cjlin/liblinear/
)
实现。不过 CD 算法训练的模型不是真正意义上的多分类模型,而是基于 “one-vs-rest” 思想分解了这个优化问题,为每个类别都训练了一个二元分类器。因为实现在底层使用该求解器的
[
`LogisticRegression`
](
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html#sklearn.linear_model.LogisticRegression
)
实例对象表面上看是一个多元分类器。
[
`sklearn.svm.l1_min_c`
](
https://scikit-learn.org/stable/modules/generated/sklearn.svm.l1_min_c.html#sklearn.svm.l1_min_c
)
可以计算使用
$l_1$
时 C 的下界,以避免模型为空(即全部特征分量的权重为零)。
`liblinear`
应用了坐标下降算法(Coordinate Descent, CD),并基于 scikit-learn 内附的高性能 C++ 库
[
LIBLINEAR library
](
http://www.csie.ntu.edu.tw/~cjlin/liblinear/
)
实现。不过 CD 算法训练的模型不是真正意义上的多分类模型,而是基于 “one-vs-rest” 思想分解了这个优化问题,为每个类别都训练了一个二元分类器。因为实现在底层使用该求解器的
[
`LogisticRegression`
](
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html#sklearn.linear_model.LogisticRegression
)
实例对象表面上看是一个多元分类器。
[
`sklearn.svm.l1_min_c`
](
https://scikit-learn.org/stable/modules/generated/sklearn.svm.l1_min_c.html#sklearn.svm.l1_min_c
)
可以计算使用
L1
时 C 的下界,以避免模型为空(即全部特征分量的权重为零)。
`lbfgs`
,
`sag`
和
`newton-cg`
求解器只支持
$l_2$
罚项,对某些高维数据收敛更快。这些求解器的参数
`multi_class`
设为
`multinomial`
即可训练一个真正的多项式 logistic 回归 [5] ,其预测的概率比默认的 “
`one-vs-rest`
” 设定更为准确。
`lbfgs`
,
`sag`
和
`newton-cg`
求解器只支持
L2
罚项,对某些高维数据收敛更快。这些求解器的参数
`multi_class`
设为
`multinomial`
即可训练一个真正的多项式 logistic 回归 [5] ,其预测的概率比默认的 “
`one-vs-rest`
” 设定更为准确。
`sag`
求解器基于平均随机梯度下降算法(Stochastic Average Gradient descent) [6]。在大数据集上的表现更快,大数据集指样本量大且特征数多。
...
...
docs/img/021new1.jpg
0 → 100644
浏览文件 @
3fde811a
11.6 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}