Merge pull request #350 from apachecn/0.21.x
用户指南更新至0.21.x
Showing
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/40.md
0 → 100644
此差异已折叠。
docs/41.md
0 → 100644
此差异已折叠。
docs/42.md
0 → 100644
此差异已折叠。
docs/47.md
0 → 100644
此差异已折叠。
此差异已折叠。
docs/56.md
已删除
100644 → 0
此差异已折叠。
docs/57.md
已删除
100644 → 0
此差异已折叠。
docs/59.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
docs/60.md
已删除
100644 → 0
docs/65.md
已删除
100644 → 0
此差异已折叠。
docs/66.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/img/021new1.jpg
0 → 100644
{kind=link}
11.6 KB
docs/img/3-5-001.png
0 → 100644
{kind=link}
1.0 KB
docs/img/bayes01.png
0 → 100644
{kind=link}
881 字节
docs/img/bayes02.png
0 → 100644
{kind=link}
951 字节
docs/img/bayse03.png
0 → 100644
{kind=link}
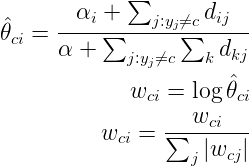
3.0 KB
docs/img/bayse04.png
0 → 100644
{kind=link}
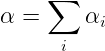
691 字节
docs/img/bayse05.png
0 → 100644
{kind=link}
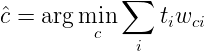
1.2 KB
docs/img/cluster01.png
0 → 100644
{kind=link}
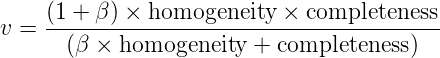
2.7 KB
{kind=link}
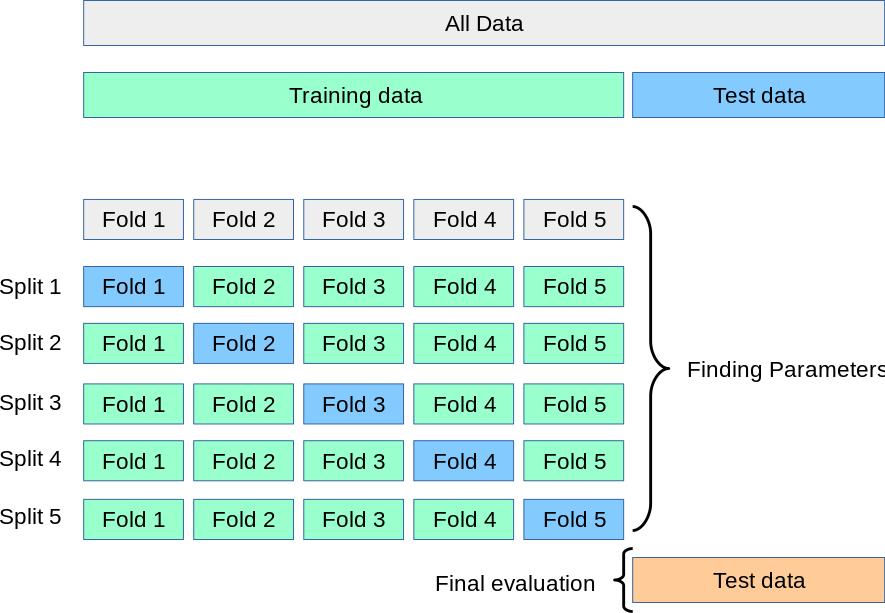
44.1 KB
docs/img/grid_search_workflow.png
0 → 100644
{kind=link}
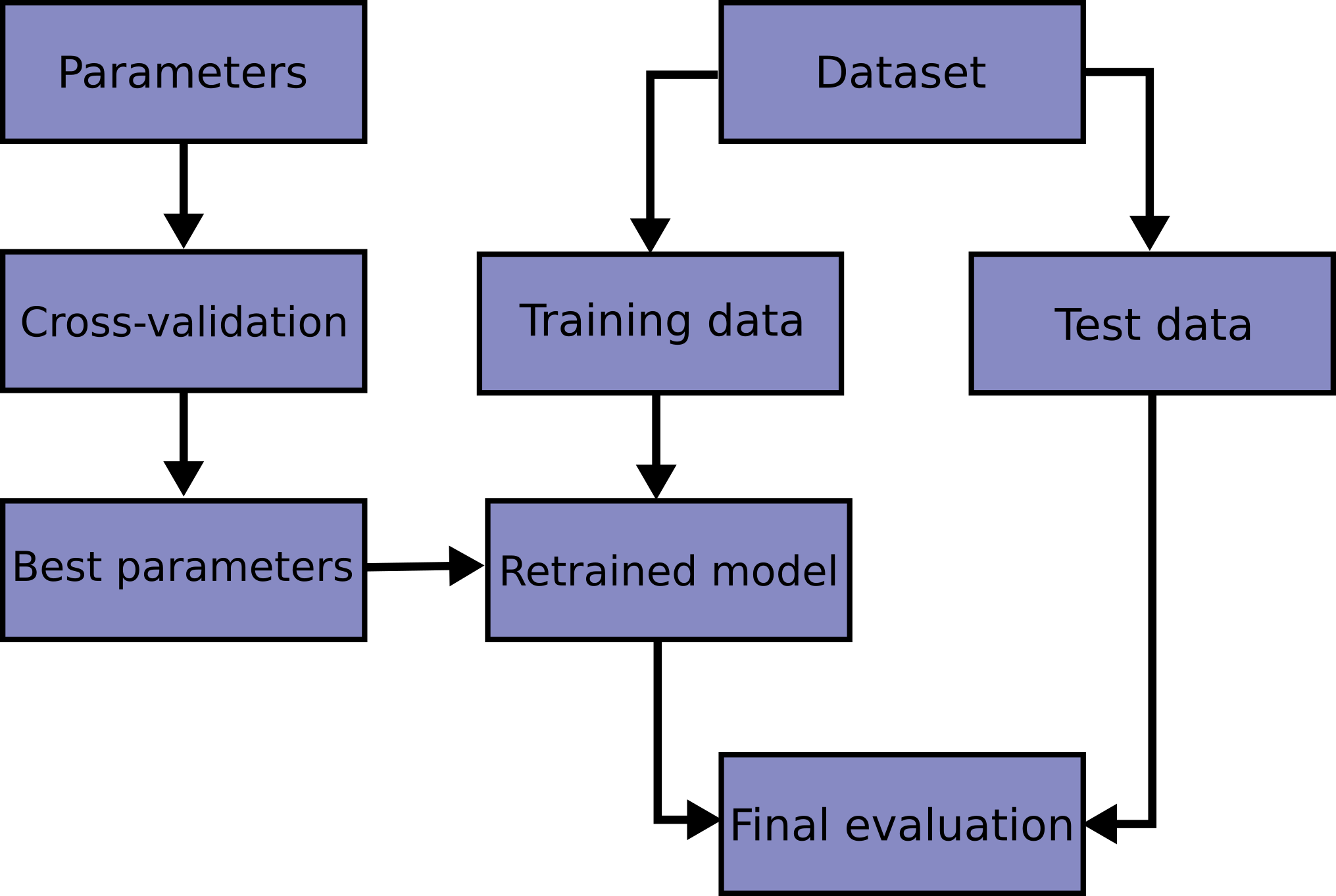
98.1 KB
docs/img/iris.jpg
0 → 100644
{kind=link}

111.0 KB
docs/img/knn01.png
0 → 100644
{kind=link}
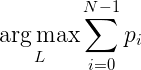
1.2 KB
docs/img/knn02.png
0 → 100644
{kind=link}
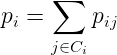
907 字节
docs/img/knn03.png
0 → 100644
{kind=link}
2.7 KB
docs/img/knn04.png
0 → 100644
{kind=link}
1.5 KB
docs/img/knn05.png
0 → 100644
{kind=link}
534 字节
docs/img/preprocessing001.png
0 → 100644
{kind=link}

6.0 KB
docs/img/preprocessing002.png
0 → 100644
{kind=link}
2.2 KB
docs/img/projection001.png
0 → 100644
{kind=link}
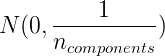
1023 字节
docs/img/projection002.png
0 → 100644
{kind=link}
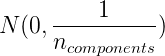
1023 字节
docs/img/score001.png
0 → 100644
{kind=link}
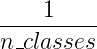
645 字节
docs/img/score002.png
0 → 100644
{kind=link}
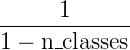
671 字节
docs/img/score003.png
0 → 100644
{kind=link}
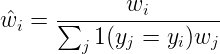
1.1 KB
docs/img/score004.png
0 → 100644
{kind=link}
此差异已折叠。
docs/img/score005.png
0 → 100644
{kind=link}
此差异已折叠。
docs/img/score006.png
0 → 100644
{kind=link}
此差异已折叠。
docs/img/score007.png
0 → 100644
{kind=link}
此差异已折叠。
docs/img/score008.png
0 → 100644
{kind=link}
此差异已折叠。
docs/img/score009.png
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。