更新至0.21
Showing
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/img/bayes01.png
0 → 100644
{kind=link}
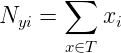
881 字节
docs/img/bayes02.png
0 → 100644
{kind=link}
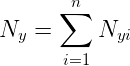
951 字节
docs/img/bayse03.png
0 → 100644
{kind=link}
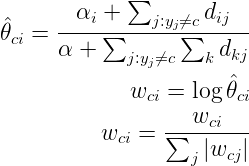
3.0 KB
docs/img/bayse04.png
0 → 100644
{kind=link}
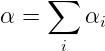
691 字节
docs/img/bayse05.png
0 → 100644
{kind=link}
1.2 KB
docs/img/iris.jpg
0 → 100644
{kind=link}
111.0 KB
{kind=link}
34.9 KB