Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
OpenDocCN
pytorch-doc-zh
提交
d211e92e
P
pytorch-doc-zh
项目概览
OpenDocCN
/
pytorch-doc-zh
通知
122
Star
3932
Fork
992
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
pytorch-doc-zh
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
d211e92e
编写于
9月 17, 2019
作者:
片刻小哥哥
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
新增:PyTorch V1.2 新特性
上级
a6f19eca
变更
5
隐藏空白更改
内联
并排
Showing
5 changed file
with
212 addition
and
6 deletion
+212
-6
README.md
README.md
+28
-6
docs/LatestChanges/2019-08-08.md
docs/LatestChanges/2019-08-08.md
+184
-0
docs/LatestChanges/img/spectrograms.png
docs/LatestChanges/img/spectrograms.png
+0
-0
docs/LatestChanges/img/transformer.png
docs/LatestChanges/img/transformer.png
+0
-0
docs/img/resources.jpg
docs/img/resources.jpg
+0
-0
未找到文件。
README.md
浏览文件 @
d211e92e
...
...
@@ -24,6 +24,16 @@
+
[
ApacheCN 机器学习交流群 629470233
](
http://shang.qq.com/wpa/qunwpa?idkey=30e5f1123a79867570f665aa3a483ca404b1c3f77737bc01ec520ed5f078ddef
)
+
[
ApacheCN 学习资源
](
http://www.apachecn.org/
)
> 版本特性
*
[
PyTorch V1.2 新特性
](
docs/LatestChanges/2019-08-08.md
)
> PyTorch 官方入库
*
中文文档:
<https://pytorch.org/resources>

## 贡献指南
项目当前处于校对阶段,请查看
[
贡献指南
](
CONTRIBUTING.md
)
,并在
[
整体进度
](
https://github.com/apachecn/pytorch-doc-zh/issues/274
)
中领取任务。
...
...
@@ -32,7 +42,12 @@
## 项目看板
> 项目 Pytorch 1.0 看板
> 项目 PyTorch 1.2 看板
*
负责人: 记得更新和优化
*
地址: https://github.com/apachecn/pytorch-doc-zh/projects/2
> 项目 PyTorch 1.0 看板
*
负责人: 记得更新和优化
*
地址: https://github.com/apachecn/pytorch-doc-zh/projects/1
...
...
@@ -41,12 +56,12 @@
格式: GitHub + QQ
> 第
一期 (2018-11-2
7)
> 第
3期 (2019-09-1
7)
*
[
飞龙
](
https://github.com/wizardforcel
)
: 562826179
*
[
片刻
](
https://github.com/jiangzhonglian
)
: 529815144
*
[
咸鱼
](
https://github.com/Watermelon233
)
: 1034616238
*
[
Twinkle
](
https://github.com/kemingzeng
)
: 1097078987
*
[
Alex
](
https://github.com/AlexJakin
)
: 1272296763
*
[
Holly
](
https://github.com/kunwuz
)
: 514397511
> 第2期 (2019-06-10)
...
...
@@ -59,12 +74,19 @@
*
[
sunxia233
](
https://github.com/sunxia233
)
: 871171307
*
[
kunwuz
](
https://github.com/kunwuz
)
: 514397511
> 第一期 (2018-11-27)
*
[
飞龙
](
https://github.com/wizardforcel
)
: 562826179
*
[
片刻
](
https://github.com/jiangzhonglian
)
: 529815144
*
[
咸鱼
](
https://github.com/Watermelon233
)
: 1034616238
*
[
Twinkle
](
https://github.com/kemingzeng
)
: 1097078987
-- 负责人要求: (欢迎一起为
`Pytorch 中文版本`
做贡献)
*
热爱开源,喜欢装逼
*
长期使用
pyt
orch(至少1年)
*
长期使用
PyT
orch(至少1年)
*
能够有时间及时优化页面bug和用户issues
*
由于会不定期和
**Py
t
orch 官方**
进行issues or email 交流,所以更要积极主动
*
由于会不定期和
**Py
T
orch 官方**
进行issues or email 交流,所以更要积极主动
*
试用期: 2个月
*
欢迎联系:
[
片刻
](
https://github.com/jiangzhonglian
)
529815144
...
...
docs/LatestChanges/2019-08-08.md
0 → 100644
浏览文件 @
d211e92e
# 新版本: PyTorch 1.2,torchtext 0.4,torchaudio 0.3 和 torchvision 0.4
> 发布: 2019年8月8日
>
> 原文: [PyTorch](https://pytorch.org/blog/pytorch-1.2-and-domain-api-release/)
>
> 翻译: [ApacheCN](https://pytorch.apachecn.org/docs/LatestChanges/2019-08-08.md)
自PyTorch 1.0发布以来,我们已经看到社区扩展到添加新工具,为PyTorch Hub中可用的越来越多的模型做出贡献,并不断增加研究和生产中的使用。
从核心角度来看,PyTorch不断添加功能以支持研究和生产使用,包括通过
[
TorchScript
](
https://pytorch.org/docs/stable/jit.html
)
连接这两个世界的能力。今天,我们很高兴地宣布我们有四个新版本,包括PyTorch 1.2,torchvision 0.4,torchaudio 0.3和torchtext 0.4。您现在可以在
[
pytorch.org上
](
https://pytorch.org/get-started/locally/
)
开始使用这些版本。
# PyTorch 1.2
使用PyTorch 1.2,开源ML框架在生产使用方面向前迈出了一大步,增加了一个改进的,更加完善的TorchScript环境。这些改进使得更容易发布生产模型,扩展对导出ONNX格式模型的支持,并增强对 Transformers 的模块级支持。除了这些新功能之外,
[
TensorBoard
](
https://pytorch.org/docs/stable/tensorboard.html
)
现在不再具有实验性 - 您只需键入
`from torch.utils.tensorboard import SummaryWriter`
即可开始使用。
## [TORCHSCRIPT 改进](https://pytorch.org/blog/pytorch-1.2-and-domain-api-release/#torchscript-improvements)
自从在PyTorch 1.0中发布以来,TorchScript已经为热切的PyTorch模型提供了生产途径。TorchScript编译器将PyTorch模型转换为静态类型的图形表示,为Python不可用的受限环境中的优化和执行提供了机会。您可以将模型逐步转换为TorchScript,将编译后的代码与Python无缝混合。
PyTorch 1.2显着扩展了TorchScript对PyTorch模型中使用的Python子集的支持,并提供了一种新的,更易于使用的API,用于将模型编译为TorchScript。有关详细信息,请参阅
[
迁移指南
](
https://pytorch.org/docs/master/jit.html#migrating-to-pytorch-1-2-recursive-scripting-api
)
以下是新API的示例用法:
```
py
import
torch
class
MyModule
(
torch
.
nn
.
Module
):
def
__init__
(
self
,
N
,
M
):
super
(
MyModule
,
self
).
__init__
()
self
.
weight
=
torch
.
nn
.
Parameter
(
torch
.
rand
(
N
,
M
))
def
forward
(
self
,
input
):
if
input
.
sum
()
>
0
:
output
=
self
.
weight
.
mv
(
input
)
else
:
output
=
self
.
weight
+
input
return
output
# Compile the model code to a static representation
my_script_module
=
torch
.
jit
.
script
(
MyModule
(
3
,
4
))
# Save the compiled code and model data so it can be loaded elsewhere
my_script_module
.
save
(
"my_script_module.pt"
)
```
要了解更多信息,请参阅我们的
[
TorchScript简介
](
https://pytorch.org/tutorials/beginner/Intro_to_TorchScript.html
)
和
[
在C ++中加载PyTorch模型
](
https://pytorch.org/tutorials/advanced/cpp_export.html
)
教程。
## [扩展了ONNX EXPORT](https://pytorch.org/blog/pytorch-1.2-and-domain-api-release/#expanded-onnx-export)
该
[
ONNX
](
http://onnx.ai/
)
社会继续以开放的成长
[
治理结构
](
https://github.com/onnx/onnx/wiki/Expanded-ONNX-Steering-Committee-Announced!
)
和额外的指导委员会成员,特殊兴趣小组(SIG)和工作组(WGS)。与Microsoft合作,我们增加了对导出ONNX Opset版本7(v1.2),8(v1.3),9(v1.4)和10(v1.5)的全面支持。我们还增强了常量折叠传递,以支持最新版本的ONNX Opset 10。ScriptModule也得到了改进,包括支持多输出,张量工厂和元组作为输入和输出。此外,用户现在可以注册自己的符号来导出自定义操作,并在导出期间指定输入的动态尺寸。以下是所有主要改进的摘要:
*
支持多种Opset,包括在Opset 10中导出丢失,切片,翻转和插值的功能。
*
ScriptModule的改进,包括支持多输出,张量工厂和元组作为输入和输出。
*
支持了十几个额外的PyTorch运营商,包括导出自定义运营商的能力。
*
许多重大修复和测试基础改进。
您可以
[
在这里
](
https://pytorch.org/tutorials/advanced/super_resolution_with_onnxruntime.html
)
试用最新的教程,由@ lara-hdr在Microsoft提供。非常感谢整个Microsoft团队为完成此版本所做的所有努力!
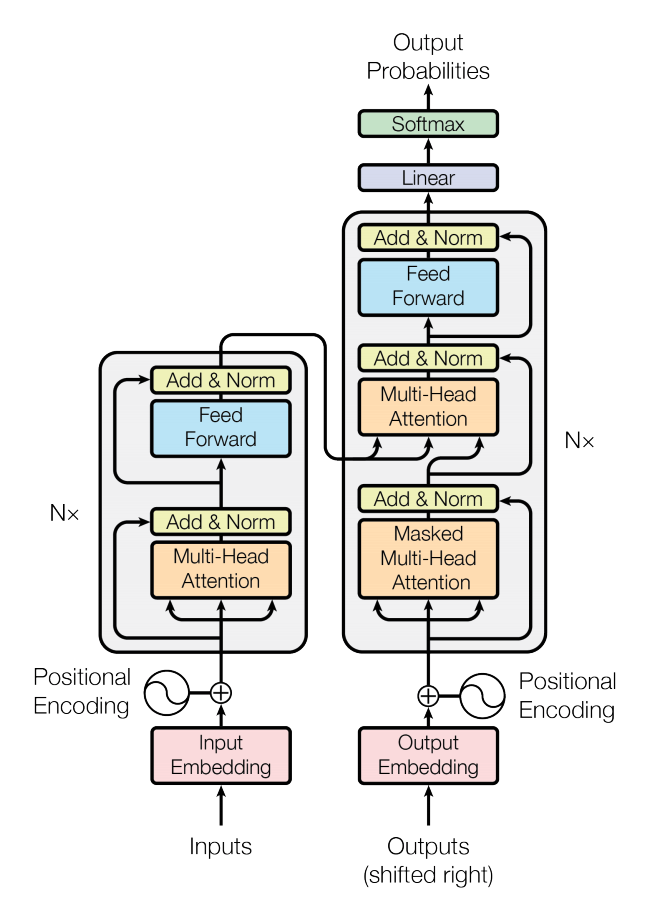
## [NN.TRANSFORMER](https://pytorch.org/blog/pytorch-1.2-and-domain-api-release/#nntransformer)
在PyTorch 1.2中,我们现在包含一个标准的
[
nn.Transformer
](
https://pytorch.org/docs/stable/nn.html?highlight=transformer#torch.nn.Transformer
)
模块,基于“
[
注意就是你所需要的
](
https://arxiv.org/abs/1706.03762
)
” 这篇论文。该
`nn.Transformer`
模块完全依赖于
[
注意机制
](
https://pytorch.org/docs/stable/nn.html?highlight=nn%20multiheadattention#torch.nn.MultiheadAttention
)
来绘制输入和输出之间的全局依赖关系。
`nn.Transformer`
模块的各个组件经过精心设计,可以独立使用。例如,
[
nn.TransformerEncoder
](
https://pytorch.org/docs/stable/nn.html?highlight=nn%20transformerencoder#torch.nn.TransformerEncoder
)
可以单独使用,不需要更大
`nn.Transformer`
。新API包括:
*
`nn.Transformer`
*
`nn.TransformerEncoder`
和
`nn.TransformerEncoderLayer`
*
`nn.TransformerDecoder`
和
`nn.TransformerDecoderLayer`

有关更多信息,请参阅
[
Transformer Layers
](
https://pytorch.org/docs/stable/nn.html#transformer-layers
)
文档。有关完整的PyTorch 1.2发行说明,请参见
[
此处
](
https://github.com/pytorch/pytorch/releases
)
。
# 域API库更新
PyTorch域库(如torchvision,torchtext和torchaudio)提供了对常用数据集,模型和变换的便捷访问,可用于快速创建最先进的基线。此外,它们还提供了常见的抽象,以减少用户可能不得不重复写入的样板代码。由于研究领域有不同的要求,围绕PyTorch出现了一个称为域API(DAPI)的专业库生态系统,以简化许多领域中新算法和现有算法的开发。我们很高兴发布三个更新的DAPI库,用于支持PyTorch 1.2核心版本的文本,音频和视觉。
## [TORCHAUDIO 0.3与KALDI兼容性,新变换](https://pytorch.org/blog/pytorch-1.2-and-domain-api-release/#torchaudio-03-with-kaldi-compatibility-new-transforms)

Torchaudio专注于机器理解音频波形。它是一个ML库,提供相关的信号处理功能(但不是一般的信号处理库)。它利用PyTorch的GPU支持为波形提供了许多工具和转换,使数据加载和标准化更容易,更易读。例如,它为使用sox的波形提供数据加载器,并为频谱图,重采样和mu-law编码和解码等转换提供数据加载器。
我们很高兴地宣布torchaudio 0.3.0的可用性,重点是标准化和复数,转换(重新采样)和两个新的功能(phase_vocoder,ISTFT),Kaldi兼容性和新教程。Torchaudio经过重新设计,是PyTorch的扩展,也是域API(DAPI)生态系统的一部分。
### [标准化](https://pytorch.org/blog/pytorch-1.2-and-domain-api-release/#standardization)
解决机器学习问题的重要工作是数据准备。在这个新版本中,我们更新了torchaudio的转换接口,以便围绕以下词汇和约定进行标准化。
假设张量具有通道作为第一维度,时间作为最后维度(适用时)。这使得它与PyTorch的尺寸一致。对于大小名称,使用前缀
`n_`
(例如“大小(
`n_freq`
,
`n_mel`
)的张量”),而维度名称不具有该前缀(例如“维度张量(通道,时间)”)。所有变换和函数的输入现在首先假定通道。这样做是为了与PyTorch保持一致,PyTorch具有通道,后跟样本数量。现在不推荐使用所有转换和函数的通道参数。
输出
`STFT`
是(通道,频率,时间,2),对于每个通道而言,列是特定窗口的傅里叶变换,因此当我们水平移动时,我们可以看到每列(傅里叶变换波形)随时间变化。这符合librosa的输出,使我们不再需要在我们的测试比较,转用
`Spectrogram`
,
`MelScale`
,
`MelSpectrogram`
,和
`MFCC`
。此外,由于这些新的惯例,我们弃用
`LC2CL`
并且
`BLC2CBL`
用于从一种信号形状转换到另一种形状。
作为此版本的一部分,我们还通过尺寸张量(...,2)引入对复数的支持,并提供
`magphase`
将这样的张量转换为其幅度和相位,以及类似
`complex_norm`
和
`angle`
。
[
README
](
https://github.com/pytorch/audio/blob/v0.3.0/README.md#Conventions
)
中提供了标准化的详细信息。
### [功能,转换和Kaldi兼容性](https://pytorch.org/blog/pytorch-1.2-and-domain-api-release/#functionals-transformations-and-kaldi-compatibility)
在标准化之前,我们将状态和计算分成了
`torchaudio.transforms`
和
`torchaudio.functional`
。
作为转换的一部分,我们在0.3.0中添加了一个新的转换:
`Resample`
。
`Resample`
可以将波形上采样或下采样到不同的频率。
作为功能的一部分,我们将介绍:
`phase_vocoder`
一个相位声码器,用于改变波形的速度而不改变其音调,并且
`ISTFT`
反向
`STFT`
实现与PyTorch提供的STFT兼容。这种分离允许我们使函数弱脚本化并在0.3.0中使用JIT。因此,我们有以下的转换JIT和CUDA支持:
`Spectrogram`
,
`AmplitudeToDB`
(原名
`SpectrogramToDB`
)
`MelScale`
,
`MelSpectrogram`
,
`MFCC`
,
`MuLawEncoding`
,
`MuLawDecoding`
(原名
`MuLawExpanding`
)。
我们现在还提供与Kaldi的兼容接口,以简化入门并减少用户对Kaldi的代码依赖性。我们现在有一个接口
`spectrogram`
,
`fbank`
和
`resample_waveform`
。
### [新教程](https://pytorch.org/blog/pytorch-1.2-and-domain-api-release/#new-tutorial)
为了展示新的约定和转换,我们有一个
[
新的教程,
](
https://pytorch.org/tutorials/beginner/audio_preprocessing_tutorial.html
)
演示如何使用torchaudio预处理波形。本教程将介绍加载波形并对其应用一些可用转换的示例。
我们很高兴看到torchaudio周围的活跃社区,并渴望进一步发展和支持它。我们鼓励您继续使用本教程和可用的两个数据集进行实验:VCTK和YESNO!他们有一个界面来下载数据集并以方便的格式预处理它们。您可以在
[
此处
](
https://github.com/pytorch/audio/releases
)
的发行说明中找到详细信息。
## [带有监督学习数据集的TORCHTEXT 0.4](https://pytorch.org/blog/pytorch-1.2-and-domain-api-release/#torchtext-04-with-supervised-learning-datasets)
torchtext的一个关键重点领域是提供有助于加速NLP研究的基本要素。这包括轻松访问常用数据集和基本预处理管道,以处理基于原始文本的数据。torchtext 0.4.0版本包括几个受欢迎的监督学习基线,带有“一个命令”的数据加载。包含一个
[
教程
](
https://pytorch.org/tutorials/beginner/text_sentiment_ngrams_tutorial.html
)
,以说明如何使用新数据集进行文本分类分析。我们还添加并改进了一些函数,例如
[
get_tokenizer
](
https://pytorch.org/text/data.html?highlight=get_tokenizer#torchtext.data.get_tokenizer
)
和
[
build_vocab_from_iterator
](
https://pytorch.org/text/vocab.html#build-vocab-from-iterator
)
,以便更容易实现未来的数据集。其他示例可以在
[
这里
](
https://github.com/pytorch/text/tree/master/examples/text_classification
)
找到。
文本分类是自然语言处理中的一项重要任务,具有许多应用,例如情感分析。新版本包括几个用于监督学习的流行
[
文本分类数据集
](
https://pytorch.org/text/datasets.html?highlight=textclassification#torchtext.datasets.TextClassificationDataset
)
,包括:
*
AG_NEWS
*
SogouNews
*
DBpedia中
*
YelpReviewPolarity
*
YelpReviewFull
*
雅虎知识堂
*
AmazonReviewPolarity
*
AmazonReviewFull
每个数据集都有两个部分(训练与测试),并且可以使用单个命令轻松加载。数据集还支持ngrams功能,以捕获有关本地字顺序的部分信息。请查看
[
此处
](
https://pytorch.org/tutorials/beginner/text_sentiment_ngrams_tutorial.html
)
的教程
[
,
](
https://pytorch.org/tutorials/beginner/text_sentiment_ngrams_tutorial.html
)
以了解有关如何将新数据集用于监督问题(如文本分类分析)的更多信息。
```
py
from
torchtext.datasets.text_classification
import
DATASETS
train_dataset
,
test_dataset
=
DATASETS
[
'AG_NEWS'
](
ngrams
=
2
)
```
除了域库之外,PyTorch还提供了许多工具来简化数据加载。用户现在可以使用一些支持良好的工具加载和预处理文本分类数据集,例如
[
torch.utils.data.DataLoader
](
https://pytorch.org/docs/stable/_modules/torch/utils/data/dataloader.html
)
和
[
torch.utils.data.IterableDataset
](
https://pytorch.org/docs/master/data.html#torch.utils.data.IterableDataset
)
。以下是使用DataLoader包装数据的几行代码。更多例子可以在
[
这里
](
https://github.com/pytorch/text/tree/master/examples/text_classification
)
找到。
```
py
from
torch.utils.data
import
DataLoader
data
=
DataLoader
(
train_dataset
,
collate_fn
=
generate_batch
)
```
查看
[
此处
](
https://github.com/pytorch/text/releases
)
的发行说明以了解更多信息并在
[
此处
](
http://pytorch.org/tutorials/beginner/text_sentiment_ngrams_tutorial.html
)
试用本
[
教程
](
http://pytorch.org/tutorials/beginner/text_sentiment_ngrams_tutorial.html
)
。
## TORCHVISION 0.4支持视频[](https://pytorch.org/blog/pytorch-1.2-and-domain-api-release/#torchvision-04-with-support-for-video)
视频现在是torchvision的一流公民,支持数据加载,数据集,预训练模型和变换。火炬的0.4版本包括:
*
用于读/写视频文件(包括音频)的高效IO原语,支持任意编码和格式。
*
标准视频数据集,与
`torch.utils.data.Dataset`
和兼容
`torch.utils.data.DataLoader`
。
*
基于Kinetics-400数据集构建的预训练模型,用于视频(包括训练脚本)的动作分类。
*
用于培训您自己的视频模型的参考培训脚本。
我们希望在PyTorch中处理视频数据尽可能简单,而不会影响性能。因此,我们避免了需要事先重新编码视频的步骤,因为它会涉及:
*
一个预处理步骤,它复制数据集以重新编码它。
*
时间和空间的开销,因为这种重新编码非常耗时。
*
通常,应使用外部脚本来执行重新编码。
此外,我们提供了诸如实用程序类之类的API,
`VideoClips`
通过创建一组视频中所有剪辑的索引,简化了在视频文件列表中枚举固定大小的所有可能剪辑的任务。它还允许您为视频指定固定的帧速率。下面提供了API的示例:
```
py
from
torchvision.datasets.video_utils
import
VideoClips
class
MyVideoDataset
(
object
):
def
__init__
(
self
,
video_paths
):
self
.
video_clips
=
VideoClips
(
video_paths
,
clip_length_in_frames
=
16
,
frames_between_clips
=
1
,
frame_rate
=
15
)
def
__getitem__
(
self
,
idx
):
video
,
audio
,
info
,
video_idx
=
self
.
video_clips
.
get_clip
(
idx
)
return
video
,
audio
def
__len__
(
self
):
return
self
.
video_clips
.
num_clips
()
```
大多数面向用户的API都在Python中,类似于PyTorch,这使得它易于扩展。此外,底层实现很快 - torchvision尽可能少地从视频中解码,以便从视频中返回剪辑。
有关更多详细信息,请查看
[
此处
](
https://github.com/pytorch/vision/releases
)
的torchvision 0.4
[
发行说明
](
https://github.com/pytorch/vision/releases
)
。
随着我们进一步改进和扩展PyTorch深度学习平台,我们期待继续与社区合作并听取您的反馈意见。
*我们要感谢整个PyTorch团队和社区对这项工作的所有贡献!*
docs/LatestChanges/img/spectrograms.png
0 → 100644
浏览文件 @
d211e92e
6.1 MB
docs/LatestChanges/img/transformer.png
0 → 100644
浏览文件 @
d211e92e
126.0 KB
docs/img/resources.jpg
0 → 100644
浏览文件 @
d211e92e
146.3 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录

{kind=link}

{kind=link}
{kind=link}