@@ -14,15 +14,14 @@ The graph is differentiated using the chain rule. If any of `tensors` are non-sc
This function accumulates gradients in the leaves - you might need to zero them before calling it.
| Parameters: |
Parameters:
***tensors** (_sequence of Tensor_) – Tensors of which the derivative will be computed.
***grad_tensors** (_sequence of_ _(_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")_or_[_None_](https://docs.python.org/3/library/constants.html#None"(in Python v3.7)")_)_) – Gradients w.r.t. each element of corresponding tensors. None values can be specified for scalar Tensors or ones that don’t require grad. If a None value would be acceptable for all grad_tensors, then this argument is optional.
***retain_graph** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – If `False`, the graph used to compute the grad will be freed. Note that in nearly all cases setting this option to `True` is not needed and often can be worked around in a much more efficient way. Defaults to the value of `create_graph`.
***create_graph** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – If `True`, graph of the derivative will be constructed, allowing to compute higher order derivative products. Defaults to `False`.
@@ -34,7 +33,7 @@ Computes and returns the sum of gradients of outputs w.r.t. the inputs.
If `only_inputs` is `True`, the function will only return a list of gradients w.r.t the specified inputs. If it’s `False`, then gradient w.r.t. all remaining leaves will still be computed, and will be accumulated into their `.grad` attribute.
| Parameters: |
Parameters:
***outputs** (_sequence of Tensor_) – outputs of the differentiated function.
***inputs** (_sequence of Tensor_) – Inputs w.r.t. which the gradient will be returned (and not accumulated into `.grad`).
...
...
@@ -43,8 +42,7 @@ If `only_inputs` is `True`, the function will only return a list of gradients w.
***create_graph** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – If `True`, graph of the derivative will be constructed, allowing to compute higher order derivative products. Default: `False`.
***allow_unused** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – If `False`, specifying inputs that were not used when computing outputs (and therefore their grad is always zero) is an error. Defaults to `False`.
|
| --- | --- |
## Locally disabling gradient computation
...
...
@@ -175,14 +173,13 @@ The graph is differentiated using the chain rule. If the tensor is non-scalar (i
This function accumulates gradients in the leaves - you might need to zero them before calling it.
| Parameters: |
Parameters:
***gradient** ([_Tensor_](tensors.html#torch.Tensor"torch.Tensor")_or_[_None_](https://docs.python.org/3/library/constants.html#None"(in Python v3.7)")) – Gradient w.r.t. the tensor. If it is a tensor, it will be automatically converted to a Tensor that does not require grad unless `create_graph` is True. None values can be specified for scalar Tensors or ones that don’t require grad. If a None value would be acceptable then this argument is optional.
***retain_graph** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – If `False`, the graph used to compute the grads will be freed. Note that in nearly all cases setting this option to True is not needed and often can be worked around in a much more efficient way. Defaults to the value of `create_graph`.
***create_graph** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – If `True`, graph of the derivative will be constructed, allowing to compute higher order derivative products. Defaults to `False`.
|
| --- | --- |
```py
detach()
...
...
@@ -371,7 +368,7 @@ Warning
If any checked tensor in `input` has overlapping memory, i.e., different indices pointing to the same memory address (e.g., from `torch.expand()`), this check will likely fail because the numerical gradients computed by point perturbation at such indices will change values at all other indices that share the same memory address.
| Parameters: |
Parameters:
***func** (_function_) – a Python function that takes Tensor inputs and returns a Tensor or a tuple of Tensors
***inputs** (_tuple of Tensor_ _or_ [_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – inputs to the function
...
...
@@ -380,8 +377,7 @@ If any checked tensor in `input` has overlapping memory, i.e., different indices
***raise_exception** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – indicating whether to raise an exception if the check fails. The exception gives more information about the exact nature of the failure. This is helpful when debugging gradchecks.
|
| --- | --- |
| Returns: | True if all differences satisfy allclose condition |
| --- | --- |
...
...
@@ -403,7 +399,7 @@ Warning
If any checked tensor in `input` and `grad_outputs` has overlapping memory, i.e., different indices pointing to the same memory address (e.g., from `torch.expand()`), this check will likely fail because the numerical gradients computed by point perturbation at such indices will change values at all other indices that share the same memory address.
| Parameters: |
Parameters:
***func** (_function_) – a Python function that takes Tensor inputs and returns a Tensor or a tuple of Tensors
***inputs** (_tuple of Tensor_ _or_ [_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – inputs to the function
...
...
@@ -414,8 +410,7 @@ If any checked tensor in `input` and `grad_outputs` has overlapping memory, i.e.
***gen_non_contig_grad_outputs** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – if `grad_outputs` is `None` and `gen_non_contig_grad_outputs` is `True`, the randomly generated gradient outputs are made to be noncontiguous
***raise_exception** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – indicating whether to raise an exception if the check fails. The exception gives more information about the exact nature of the failure. This is helpful when debugging gradchecks.
|
| --- | --- |
| Returns: | True if all differences satisfy allclose condition |
| --- | --- |
...
...
@@ -429,13 +424,12 @@ class torch.autograd.profiler.profile(enabled=True, use_cuda=False)
Context manager that manages autograd profiler state and holds a summary of results.
| Parameters: |
Parameters:
***enabled** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – Setting this to False makes this context manager a no-op. Default: `True`.
***use_cuda** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – Enables timing of CUDA events as well using the cudaEvent API. Adds approximately 4us of overhead to each tensor operation. Default: `False`
If `function` invocation during backward does anything different than the one during forward, e.g., due to some global variable, the checkpointed version won’t be equivalent, and unfortunately it can’t be detected.
| Parameters: |
Parameters:
***function** – describes what to run in the forward pass of the model or part of the model. It should also know how to handle the inputs passed as the tuple. For example, in LSTM, if user passes `(activation, hidden)`, `function` should correctly use the first input as `activation` and the second input as `hidden`
***args** – tuple containing inputs to the `function`
|
| --- | --- |
| Returns: | Output of running `function` on `*args` |
| --- | --- |
...
...
@@ -48,14 +47,13 @@ Warning
Checkpointing doesn’t work with [`torch.autograd.grad()`](autograd.html#torch.autograd.grad"torch.autograd.grad"), but only with [`torch.autograd.backward()`](autograd.html#torch.autograd.backward"torch.autograd.backward").
| Parameters: |
Parameters:
***functions** – A [`torch.nn.Sequential`](nn.html#torch.nn.Sequential"torch.nn.Sequential") or the list of modules or functions (comprising the model) to run sequentially.
***segments** – Number of chunks to create in the model
***inputs** – tuple of Tensors that are inputs to `functions`
|
| --- | --- |
| Returns: | Output of running `functions` sequentially on `*inputs` |
***tensor** ([_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – tensor to broadcast.
***devices** (_Iterable_) – an iterable of devices among which to broadcast. Note that it should be like (src, dst1, dst2, …), the first element of which is the source device to broadcast from.
|
| --- | --- |
| Returns: | A tuple containing copies of the `tensor`, placed on devices corresponding to indices from `devices`. |
Broadcasts a sequence tensors to the specified GPUs. Small tensors are first coalesced into a buffer to reduce the number of synchronizations.
| Parameters: |
Parameters:
***tensors** (_sequence_) – tensors to broadcast.
***devices** (_Iterable_) – an iterable of devices among which to broadcast. Note that it should be like (src, dst1, dst2, …), the first element of which is the source device to broadcast from.
***buffer_size** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")) – maximum size of the buffer used for coalescing
|
| --- | --- |
| Returns: | A tuple containing copies of the `tensor`, placed on devices corresponding to indices from `devices`. |
| --- | --- |
...
...
@@ -303,13 +301,12 @@ Sums tensors from multiple GPUs.
All inputs should have matching shapes.
| Parameters: |
Parameters:
***inputs** (_Iterable__[_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")_]_) – an iterable of tensors to add.
***destination** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")_,_ _optional_) – a device on which the output will be placed (default: current device).
|
| --- | --- |
| Returns: | A tensor containing an elementwise sum of all inputs, placed on the `destination` device. |
***tensor** ([_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – tensor to scatter.
***devices** (_Iterable__[_[_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")_]_) – iterable of ints, specifying among which devices the tensor should be scattered.
***chunk_sizes** (_Iterable__[_[_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")_]__,_ _optional_) – sizes of chunks to be placed on each device. It should match `devices` in length and sum to `tensor.size(dim)`. If not specified, the tensor will be divided into equal chunks.
***dim** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")_,_ _optional_) – A dimension along which to chunk the tensor.
|
| --- | --- |
| Returns: | A tuple containing chunks of the `tensor`, spread across given `devices`. |
| --- | --- |
...
...
@@ -339,14 +335,13 @@ Gathers tensors from multiple GPUs.
Tensor sizes in all dimension different than `dim` have to match.
| Parameters: |
Parameters:
***tensors** (_Iterable__[_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")_]_) – iterable of tensors to gather.
***dim** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")) – a dimension along which the tensors will be concatenated.
***destination** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")_,_ _optional_) – output device (-1 means CPU, default: current device)
|
| --- | --- |
| Returns: | A tensor located on `destination` device, that is a result of concatenating `tensors` along `dim`. |
| --- | --- |
...
...
@@ -360,13 +355,12 @@ Wrapper around a CUDA stream.
A CUDA stream is a linear sequence of execution that belongs to a specific device, independent from other streams. See [CUDA semantics](notes/cuda.html#cuda-semantics) for details.
| Parameters: |
Parameters:
***device** ([_torch.device_](tensor_attributes.html#torch.torch.device"torch.torch.device")_or_[_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")_,_ _optional_) – a device on which to allocate the stream. If [`device`](#torch.cuda.device"torch.cuda.device") is `None` (default) or a negative integer, this will use the current device.
***priority** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")_,_ _optional_) – priority of the stream. Lower numbers represent higher priorities.
|
| --- | --- |
```py
query()
...
...
@@ -434,14 +428,13 @@ class torch.cuda.Event(enable_timing=False, blocking=False, interprocess=False,
Wrapper around CUDA event.
| Parameters: |
Parameters:
***enable_timing** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")) – indicates if the event should measure time (default: `False`)
***blocking** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")) – if `True`, [`wait()`](#torch.cuda.Event.wait"torch.cuda.Event.wait") will be blocking (default: `False`)
***interprocess** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")) – if `True`, the event can be shared between processes (default: `False`)
@@ -50,7 +49,7 @@ class torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=
Data loader. Combines a dataset and a sampler, and provides single- or multi-process iterators over the dataset.
| Parameters: |
Parameters:
***dataset** ([_Dataset_](#torch.utils.data.Dataset"torch.utils.data.Dataset")) – dataset from which to load the data.
***batch_size** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")_,_ _optional_) – how many samples per batch to load (default: `1`).
...
...
@@ -64,8 +63,7 @@ Data loader. Combines a dataset and a sampler, and provides single- or multi-pro
***timeout** (_numeric__,_ _optional_) – if positive, the timeout value for collecting a batch from workers. Should always be non-negative. (default: `0`)
***worker_init_fn** (_callable__,_ _optional_) – If not `None`, this will be called on each worker subprocess with the worker id (an int in `[0, num_workers - 1]`) as input, after seeding and before data loading. (default: `None`)
Randomly split a dataset into non-overlapping new datasets of given lengths.
| Parameters: |
Parameters:
***dataset** ([_Dataset_](#torch.utils.data.Dataset"torch.utils.data.Dataset")) – Dataset to be split
***lengths** (_sequence_) – lengths of splits to be produced
|
| --- | --- |
```py
classtorch.utils.data.Sampler(data_source)
...
...
@@ -112,14 +109,13 @@ class torch.utils.data.RandomSampler(data_source, replacement=False, num_samples
Samples elements randomly. If without replacement, then sample from a shuffled dataset. If with replacement, then user can specify `num_samples` to draw.
| Parameters: |
Parameters:
***data_source** ([_Dataset_](#torch.utils.data.Dataset"torch.utils.data.Dataset")) – dataset to sample from
***num_samples** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")) – number of samples to draw, default=len(dataset)
***replacement** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")) – samples are drawn with replacement if `True`, default=False
@@ -136,14 +132,13 @@ class torch.utils.data.WeightedRandomSampler(weights, num_samples, replacement=T
Samples elements from [0,..,len(weights)-1] with given probabilities (weights).
| Parameters: |
Parameters:
***weights** (_sequence_) – a sequence of weights, not necessary summing up to one
***num_samples** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")) – number of samples to draw
***replacement** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")) – if `True`, samples are drawn with replacement. If not, they are drawn without replacement, which means that when a sample index is drawn for a row, it cannot be drawn again for that row.
@@ -151,14 +146,13 @@ class torch.utils.data.BatchSampler(sampler, batch_size, drop_last)
Wraps another sampler to yield a mini-batch of indices.
| Parameters: |
Parameters:
***sampler** ([_Sampler_](#torch.utils.data.Sampler"torch.utils.data.Sampler")) – Base sampler.
***batch_size** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")) – Size of mini-batch.
***drop_last** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")) – If `True`, the sampler will drop the last batch if its size would be less than `batch_size`
|
| --- | --- |
Example
...
...
@@ -182,12 +176,11 @@ Note
Dataset is assumed to be of constant size.
| Parameters: |
Parameters:
***dataset** – Dataset used for sampling.
***num_replicas** (_optional_) – Number of processes participating in distributed training.
***rank** (_optional_) – Rank of the current process within num_replicas.
Initializes the default distributed process group, and this will also initialize the distributed package
| Parameters: |
Parameters:
***backend** ([_str_](https://docs.python.org/3/library/stdtypes.html#str"(in Python v3.7)")_or_[_Backend_](#torch.distributed.Backend"torch.distributed.Backend")) – The backend to use. Depending on build-time configurations, valid values include `mpi`, `gloo`, and `nccl`. This field should be given as a lowercase string (e.g., `"gloo"`), which can also be accessed via [`Backend`](#torch.distributed.Backend"torch.distributed.Backend") attributes (e.g., `Backend.GLOO`).
***init_method** ([_str_](https://docs.python.org/3/library/stdtypes.html#str"(in Python v3.7)")_,_ _optional_) – URL specifying how to initialize the process group.
...
...
@@ -88,8 +88,7 @@ Initializes the default distributed process group, and this will also initialize
***timeout** (_timedelta__,_ _optional_) – Timeout for operations executed against the process group. Default value equals 30 minutes. This is only applicable for the `gloo` backend.
***group_name** ([_str_](https://docs.python.org/3/library/stdtypes.html#str"(in Python v3.7)")_,_ _optional__,_ _deprecated_) – Group name.
|
| --- | --- |
To enable `backend == Backend.MPI`, PyTorch needs to built from source on a system that supports MPI. The same applies to NCCL as well.
...
...
@@ -229,13 +228,12 @@ Creates a new distributed group.
This function requires that all processes in the main group (i.e. all processes that are part of the distributed job) enter this function, even if they are not going to be members of the group. Additionally, groups should be created in the same order in all processes.
| Parameters: |
Parameters:
***ranks** ([_list_](https://docs.python.org/3/library/stdtypes.html#list"(in Python v3.7)")_[_[_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")_]_) – List of ranks of group members.
***timeout** (_timedelta__,_ _optional_) – Timeout for operations executed against the process group. Default value equals 30 minutes. This is only applicable for the `gloo` backend.
|
| --- | --- |
| Returns: | A handle of distributed group that can be given to collective calls. |
***tensor** ([_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – Tensor to fill with received data.
***src** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")_,_ _optional_) – Source rank. Will receive from any process if unspecified.
***group** (_ProcessGroup__,_ _optional_) – The process group to work on
***tag** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")_,_ _optional_) – Tag to match recv with remote send
|
| --- | --- |
| Returns: | Sender rank -1, if not part of the group |
***group** (_ProcessGroup__,_ _optional_) – The process group to work on
***tag** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")_,_ _optional_) – Tag to match recv with remote send
|
| --- | --- |
| Returns: | A distributed request object. None, if not part of the group |
| --- | --- |
...
...
@@ -337,15 +331,14 @@ Broadcasts the tensor to the whole group.
`tensor` must have the same number of elements in all processes participating in the collective.
| Parameters: |
Parameters:
***tensor** ([_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – Data to be sent if `src` is the rank of current process, and tensor to be used to save received data otherwise.
***group** (_ProcessGroup__,_ _optional_) – The process group to work on
***async_op** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – Whether this op should be an async op
|
| --- | --- |
| Returns: | Async work handle, if async_op is set to True. None, if not async_op or if not part of the group |
| --- | --- |
...
...
@@ -357,15 +350,14 @@ Reduces the tensor data across all machines in such a way that all get the final
After the call `tensor` is going to be bitwise identical in all processes.
| Parameters: |
Parameters:
***tensor** ([_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – Input and output of the collective. The function operates in-place.
***op** (_optional_) – One of the values from `torch.distributed.ReduceOp` enum. Specifies an operation used for element-wise reductions.
***group** (_ProcessGroup__,_ _optional_) – The process group to work on
***async_op** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – Whether this op should be an async op
|
| --- | --- |
| Returns: | Async work handle, if async_op is set to True. None, if not async_op or if not part of the group |
| --- | --- |
...
...
@@ -377,7 +369,7 @@ Reduces the tensor data across all machines.
Only the process with rank `dst` is going to receive the final result.
| Parameters: |
Parameters:
***tensor** ([_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – Input and output of the collective. The function operates in-place.
@@ -385,8 +377,7 @@ Only the process with rank `dst` is going to receive the final result.
***group** (_ProcessGroup__,_ _optional_) – The process group to work on
***async_op** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – Whether this op should be an async op
|
| --- | --- |
| Returns: | Async work handle, if async_op is set to True. None, if not async_op or if not part of the group |
***tensor_list** ([_list_](https://docs.python.org/3/library/stdtypes.html#list"(in Python v3.7)")_[_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")_]_) – Output list. It should contain correctly-sized tensors to be used for output of the collective.
***tensor** ([_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – Tensor to be broadcast from current process.
***group** (_ProcessGroup__,_ _optional_) – The process group to work on
***async_op** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – Whether this op should be an async op
|
| --- | --- |
| Returns: | Async work handle, if async_op is set to True. None, if not async_op or if not part of the group |
***gather_list** ([_list_](https://docs.python.org/3/library/stdtypes.html#list"(in Python v3.7)")_[_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")_]_) – List of appropriately-sized tensors to use for received data. Required only in the receiving process.
...
...
@@ -422,8 +412,7 @@ Gathers a list of tensors in a single process.
***group** (_ProcessGroup__,_ _optional_) – The process group to work on
***async_op** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – Whether this op should be an async op
|
| --- | --- |
| Returns: | Async work handle, if async_op is set to True. None, if not async_op or if not part of the group |
| --- | --- |
...
...
@@ -435,7 +424,7 @@ Scatters a list of tensors to all processes in a group.
Each process will receive exactly one tensor and store its data in the `tensor` argument.
***scatter_list** ([_list_](https://docs.python.org/3/library/stdtypes.html#list"(in Python v3.7)")_[_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")_]_) – List of tensors to scatter. Required only in the process that is sending the data.
...
...
@@ -443,8 +432,7 @@ Each process will receive exactly one tensor and store its data in the `tensor`
***group** (_ProcessGroup__,_ _optional_) – The process group to work on
***async_op** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – Whether this op should be an async op
|
| --- | --- |
| Returns: | Async work handle, if async_op is set to True. None, if not async_op or if not part of the group |
| --- | --- |
...
...
@@ -456,13 +444,12 @@ Synchronizes all processes.
This collective blocks processes until the whole group enters this function, if async_op is False, or if async work handle is called on wait().
| Parameters: |
Parameters:
***group** (_ProcessGroup__,_ _optional_) – The process group to work on
***async_op** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – Whether this op should be an async op
|
| --- | --- |
| Returns: | Async work handle, if async_op is set to True. None, if not async_op or if not part of the group |
| --- | --- |
...
...
@@ -546,7 +533,7 @@ Broadcasts the tensor to the whole group with multiple GPU tensors per node.
Only nccl and gloo backend are currently supported tensors should only be GPU tensors
| Parameters: |
Parameters:
***tensor_list** (_List__[_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")_]_) – Tensors that participate in the collective operation. if `src` is the rank, then `src_tensor``th element of ``tensor_list` (`tensor_list[src_tensor]`) will be broadcasted to all other tensors (on different GPUs) in the src process and all tensors in `tensor_list` of other non-src processes. You also need to make sure that `len(tensor_list)` is the same for all the distributed processes calling this function.
@@ -554,8 +541,7 @@ Only nccl and gloo backend are currently supported tensors should only be GPU te
***async_op** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – Whether this op should be an async op
| Returns: | Async work handle, if async_op is set to True. None, if not async_op or if not part of the group |
| --- | --- |
...
...
@@ -569,15 +555,14 @@ After the call, all `tensor` in `tensor_list` is going to be bitwise identical i
Only nccl and gloo backend is currently supported tensors should only be GPU tensors
| Parameters: |
Parameters:
***list** (_tensor_) – List of input and output tensors of the collective. The function operates in-place and requires that each tensor to be a GPU tensor on different GPUs. You also need to make sure that `len(tensor_list)` is the same for all the distributed processes calling this function.
***op** (_optional_) – One of the values from `torch.distributed.ReduceOp` enum. Specifies an operation used for element-wise reductions.
***group** (_ProcessGroup__,_ _optional_) – The process group to work on
***async_op** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – Whether this op should be an async op
|
| --- | --- |
| Returns: | Async work handle, if async_op is set to True. None, if not async_op or if not part of the group |
| --- | --- |
...
...
@@ -591,7 +576,7 @@ Only the GPU of `tensor_list[dst_tensor]` on the process with rank `dst` is goin
Only nccl backend is currently supported tensors should only be GPU tensors
| Parameters: |
Parameters:
***tensor_list** (_List__[_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")_]_) – Input and output GPU tensors of the collective. The function operates in-place. You also need to make sure that `len(tensor_list)` is the same for all the distributed processes calling this function.
@@ -600,8 +585,7 @@ Only nccl backend is currently supported tensors should only be GPU tensors
***async_op** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – Whether this op should be an async op
| Returns: | Async work handle, if async_op is set to True. None, otherwise |
| --- | --- |
...
...
@@ -613,15 +597,14 @@ Gathers tensors from the whole group in a list. Each tensor in `tensor_list` sho
Only nccl backend is currently supported tensors should only be GPU tensors
| Parameters: |
Parameters:
***output_tensor_lists** (_List__[__List__[_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")_]__]_) – Output lists. It should contain correctly-sized tensors on each GPU to be used for output of the collective. e.g. `output_tensor_lists[i]` contains the all_gather result that resides on the GPU of `input_tensor_list[i]`. Note that each element of `output_tensor_lists[i]` has the size of `world_size * len(input_tensor_list)`, since the function all gathers the result from every single GPU in the group. To interpret each element of `output_tensor_list[i]`, note that `input_tensor_list[j]` of rank k will be appear in `output_tensor_list[i][rank * world_size + j]` Also note that `len(output_tensor_lists)`, and the size of each element in `output_tensor_lists` (each element is a list, therefore `len(output_tensor_lists[i])`) need to be the same for all the distributed processes calling this function.
***input_tensor_list** (_List__[_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")_]_) – List of tensors(on different GPUs) to be broadcast from current process. Note that `len(input_tensor_list)` needs to be the same for all the distributed processes calling this function.
***group** (_ProcessGroup__,_ _optional_) – The process group to work on
***async_op** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – Whether this op should be an async op
|
| --- | --- |
| Returns: | Async work handle, if async_op is set to True. None, if not async_op or if not part of the group |
***backend** ([_str_](https://docs.python.org/3/library/stdtypes.html#str"(in Python v3.7)")) – Name of the backend to use. Depending on build-time configuration valid values include: `tcp`, `mpi`, `gloo` and `nccl`.
***init_method** ([_str_](https://docs.python.org/3/library/stdtypes.html#str"(in Python v3.7)")_,_ _optional_) – URL specifying how to initialize the package.
...
...
@@ -51,8 +51,7 @@ Initializes the distributed package.
***rank** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")_,_ _optional_) – Rank of the current process.
***group_name** ([_str_](https://docs.python.org/3/library/stdtypes.html#str"(in Python v3.7)")_,_ _optional_) – Group name. See description of init methods.
|
| --- | --- |
To enable `backend == mpi`, PyTorch needs to built from source on a system that supports MPI. If you want to use Open MPI with CUDA-aware support, please use Open MPI major version 2 and above.
***tensor** ([_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – Tensor to fill with received data.
***src** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")_,_ _optional_) – Source rank. Will receive from any process if unspecified.
@@ -224,14 +219,13 @@ Broadcasts the tensor to the whole group.
`tensor` must have the same number of elements in all processes participating in the collective.
| Parameters: |
Parameters:
***tensor** ([_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – Data to be sent if `src` is the rank of current process, and tensor to be used to save received data otherwise.
***tensor_list** ([_list_](https://docs.python.org/3/library/stdtypes.html#list"(in Python v3.7)")_[_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")_]_) – Output list. It should contain correctly-sized tensors to be used for output of the collective.
***tensor** ([_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – Tensor to be broadcast from current process.
***group** (_optional_) – Group of the collective.
***dst** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")) – Destination rank. Required in all processes except the one that is receiveing the data.
***gather_list** ([_list_](https://docs.python.org/3/library/stdtypes.html#list"(in Python v3.7)")_[_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")_]_) – List of appropriately-sized tensors to use for received data. Required only in the receiving process.
***group** (_optional_) – Group of the collective.
***src** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")) – Source rank. Required in all processes except the one that is sending the data.
***scatter_list** ([_list_](https://docs.python.org/3/library/stdtypes.html#list"(in Python v3.7)")_[_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")_]_) – List of tensors to scatter. Required only in the process that is sending the data.
***group** (_optional_) – Group of the collective.
Only NCCL backend is currently supported. `tensor_list` should only contain GPU tensors.
| Parameters: |
Parameters:
***tensor_list** (_List__[_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")_]_) – Tensors that participate in the collective operation. if `src` is the rank, then the first element of `tensor_list` (`tensor_list[0]`) will be broadcasted to all other tensors (on different GPUs) in the src process and all tensors in `tensor_list` of other non-src processes. You also need to make sure that `len(tensor_list)` is the same for all the distributed processes calling this function.
Only NCCL backend is currently supported. `tensor_list` should only contain GPU tensors.
| Parameters: |
Parameters:
***tensor_list** (_List__[_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")_]_) – List of input and output tensors of the collective. The function operates in-place and requires that each tensor to be a GPU tensor on different GPUs. You also need to make sure that `len(tensor_list)` is the same for all the distributed processes calling this function.
***op** (_optional_) – One of the values from `torch.distributed.deprecated.reduce_op` enum. Specifies an operation used for element-wise reductions.
***group** (_optional_) – Group of the collective.
Only NCCL backend is currently supported. `tensor_list` should only contain GPU tensors.
| Parameters: |
Parameters:
***tensor_list** (_List__[_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")_]_) – Input and output GPU tensors of the collective. The function operates in-place. You also need to make sure that `len(tensor_list)` is the same for all the distributed processes calling this function.
Only NCCL backend is currently supported. `output_tensor_lists` and `input_tensor_list` should only contain GPU tensors.
| Parameters: |
Parameters:
***output_tensor_lists** (_List__[__List__[_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")_]__]_) – Output lists. It should contain correctly-sized tensors on each GPU to be used for output of the collective. e.g. `output_tensor_lists[i]` contains the all_gather result that resides on the GPU of `input_tensor_list[i]`. Note that each element of `output_tensor_lists[i]` has the size of `world_size * len(input_tensor_list)`, since the function all gathers the result from every single GPU in the group. To interpret each element of `output_tensor_list[i]`, note that `input_tensor_list[j]` of rank k will be appear in `output_tensor_list[i][rank * world_size + j]` Also note that `len(output_tensor_lists)`, and the size of each element in `output_tensor_lists` (each element is a list, therefore `len(output_tensor_lists[i])`) need to be the same for all the distributed processes calling this function.
***input_tensor_list** (_List__[_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")_]_) – List of tensors (on different GPUs) to be broadcast from current process. Note that `len(input_tensor_list)` needs to be the same for all the distributed processes calling this function.
***group** (_optional_) – Group of the collective.
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to `batch_shape`. This method calls [`expand`](tensors.html#torch.Tensor.expand"torch.Tensor.expand") on the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in `__init__.py`, when an instance is first created.
| Parameters: |
Parameters:
***batch_shape** (_torch.Size_) – the desired expanded size.
***_instance** – new instance provided by subclasses that need to override `.expand`.
|
| --- | --- |
| Returns: | New distribution instance with batch dimensions expanded to `batch_size`. |
| --- | --- |
...
...
@@ -233,13 +232,12 @@ tensor([ 0.])
```
| Parameters: |
Parameters:
***probs** (_Number__,_ [_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – the probabilty of sampling `1`
***logits** (_Number__,_ [_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – the log-odds of sampling `1`
***concentration1** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_or_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – 1st concentration parameter of the distribution (often referred to as alpha)
***concentration0** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_or_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – 2nd concentration parameter of the distribution (often referred to as beta)
***total_count** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")_or_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – number of Bernoulli trials
***loc** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_or_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – mode or median of the distribution.
***scale** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_or_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – half width at half maximum.
***concentration** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_or_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – shape parameter of the distribution (often referred to as alpha)
***rate** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_or_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – rate = 1 / scale of the distribution (often referred to as beta)
***loc** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_or_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – Location parameter of the distribution
***scale** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_or_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – Scale parameter of the distribution
@@ -1190,13 +1180,12 @@ This is mainly useful for changing the shape of the result of [`log_prob()`](#to
```
| Parameters: |
Parameters:
***base_distribution** ([_torch.distributions.distribution.Distribution_](#torch.distributions.distribution.Distribution"torch.distributions.distribution.Distribution")) – a base distribution
***reinterpreted_batch_ndims** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")) – the number of batch dims to reinterpret as event dims
|
| --- | --- |
```py
arg_constraints={}
...
...
@@ -1265,13 +1254,12 @@ tensor([ 0.1046])
```
| Parameters: |
Parameters:
***loc** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_or_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – mean of the distribution
***scale** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_or_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – scale of the distribution
***loc** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_or_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – mean of log of distribution
***scale** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_or_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – standard deviation of log of the distribution
***loc** ([_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – mean of the distribution with shape `batch_shape + event_shape`
***cov_factor** ([_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – factor part of low-rank form of covariance matrix with shape `batch_shape + event_shape + (rank,)`
***cov_diag** ([_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – diagonal part of low-rank form of covariance matrix with shape `batch_shape + event_shape`
|
| --- | --- |
Note
...
...
@@ -1511,14 +1497,13 @@ tensor([-4.1338])
```
| Parameters: |
Parameters:
***total_count** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")) – number of trials
Creates a Negative Binomial distribution, i.e. distribution of the number of independent identical Bernoulli trials needed before `total_count` failures are achieved. The probability of success of each Bernoulli trial is [`probs`](#torch.distributions.negative_binomial.NegativeBinomial.probs"torch.distributions.negative_binomial.NegativeBinomial.probs").
| Parameters: |
Parameters:
***total_count** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_or_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – non-negative number of negative Bernoulli trials to stop, although the distribution is still valid for real valued count
***probs** ([_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – Event probabilities of success in the half open interval [0, 1)
* **logits** ([_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – Event log-odds for probabilities of success
***loc** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_or_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – mean of the distribution (often referred to as mu)
***scale** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_or_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – standard deviation of the distribution (often referred to as sigma)
***scale** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_or_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – Scale parameter of the distribution
***alpha** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_or_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – Shape parameter of the distribution
***df** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_or_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – degrees of freedom
***loc** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_or_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – mean of the distribution
***scale** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_or_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – scale of the distribution
***scale** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_or_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – Scale parameter of distribution (lambda).
***concentration** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_or_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – Concentration parameter of distribution (k/shape).
@@ -2413,13 +2387,12 @@ register_kl(DerivedP, DerivedQ)(kl_version1) # Break the tie.
```
| Parameters: |
Parameters:
***type_p** ([_type_](https://docs.python.org/3/library/functions.html#type"(in Python v3.7)")) – A subclass of `Distribution`.
***type_q** ([_type_](https://docs.python.org/3/library/functions.html#type"(in Python v3.7)")) – A subclass of `Distribution`.
|
| --- | --- |
## `Transforms`
...
...
@@ -2458,8 +2431,7 @@ Derived classes should implement one or both of `_call()` or `_inverse()`. Deriv
***sign** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")_or_[_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – For bijective univariate transforms, this should be +1 or -1 depending on whether transform is monotone increasing or decreasing.
***event_dim** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")) – Number of dimensions that are correlated together in the transform `event_shape`. This should be 0 for pointwise transforms, 1 for transforms that act jointly on vectors, 2 for transforms that act jointly on matrices, etc.
|
| --- | --- |
```py
inv
...
...
@@ -2518,14 +2490,13 @@ class torch.distributions.transforms.AffineTransform(loc, scale, event_dim=0, ca
Transform via the pointwise affine mapping .
***event_dim** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")) – Optional size of `event_shape`. This should be zero for univariate random variables, 1 for distributions over vectors, 2 for distributions over matrices, etc.
***constraint** (subclass of [`Constraint`](#torch.distributions.constraints.Constraint"torch.distributions.constraints.Constraint")) – A subclass of [`Constraint`](#torch.distributions.constraints.Constraint"torch.distributions.constraints.Constraint"), or a singleton object of the desired class.
***factory** (_callable_) – A callable that inputs a constraint object and returns a [`Transform`](#torch.distributions.transforms.Transform"torch.distributions.transforms.Transform") object.
@@ -85,7 +85,7 @@ To compile the sources, the default system compiler (`c++`) is used, which can b
CUDA support with mixed compilation is provided. Simply pass CUDA source files (`.cu` or `.cuh`) along with other sources. Such files will be detected and compiled with nvcc rather than the C++ compiler. This includes passing the CUDA lib64 directory as a library directory, and linking `cudart`. You can pass additional flags to nvcc via `extra_cuda_cflags`, just like with `extra_cflags` for C++. Various heuristics for finding the CUDA install directory are used, which usually work fine. If not, setting the `CUDA_HOME` environment variable is the safest option.
| Parameters: |
Parameters:
***name** – The name of the extension to build. This MUST be the same as the name of the pybind11 module!
***sources** – A list of relative or absolute paths to C++ source files.
...
...
@@ -98,8 +98,7 @@ CUDA support with mixed compilation is provided. Simply pass CUDA source files (
***with_cuda** – Determines whether CUDA headers and libraries are added to the build. If set to `None` (default), this value is automatically determined based on the existence of `.cu` or `.cuh` in `sources`. Set it to `True`` to force CUDA headers and libraries to be included.
* **is_python_module** – If `True` (default), imports the produced shared library as a Python module. If `False`, loads it into the process as a plain dynamic library.
|
| --- | --- |
| Returns: | If `is_python_module` is `True`, returns the loaded PyTorch extension as a Python module. If `is_python_module` is `False` returns nothing (the shared library is loaded into the process as a side effect). |
| --- | --- |
...
...
@@ -133,15 +132,14 @@ The sources in `cuda_sources` are concatenated into a separate `.cu` file and pr
See [`load()`](#torch.utils.cpp_extension.load "torch.utils.cpp_extension.load") for a description of arguments omitted below.
| Parameters: |
Parameters:
* **cpp_sources** – A string, or list of strings, containing C++ source code.
* **cuda_sources** – A string, or list of strings, containing CUDA source code.
* **functions** – A list of function names for which to generate function bindings. If a dictionary is given, it should map function names to docstrings (which are otherwise just the function names).
* **with_cuda** – Determines whether CUDA headers and libraries are added to the build. If set to `None` (default), this value is automatically determined based on whether `cuda_sources` is provided. Set it to `True`` to force CUDA headers and libraries to be included.
Load a model from a github repo, with pretrained weights.
| Parameters: |
Parameters:
***github** – Required, a string with format “repo_owner/repo_name[:tag_name]” with an optional tag/branch. The default branch is `master` if not specified. Example: ‘pytorch/vision[:hub]’
***model** – Required, a string of callable name defined in repo’s hubconf.py
...
...
@@ -16,8 +16,7 @@ Load a model from a github repo, with pretrained weights.
****args** – Optional, the corresponding args for callable `model`.
*****kwargs** – Optional, the corresponding kwargs for callable `model`.
|
| --- | --- |
| Returns: | a single model with corresponding pretrained weights. |
@@ -142,13 +142,12 @@ Load a `ScriptModule` previously saved with `save`
All previously saved modules, no matter their device, are first loaded onto CPU, and then are moved to the devices they were saved from. If this fails (e.g. because the run time system doesn’t have certain devices), an exception is raised. However, storages can be dynamically remapped to an alternative set of devices using the `map_location` argument. Comparing to [`torch.load()`](torch.html#torch.load"torch.load"), `map_location` in this function is simplified, which only accepts a string (e.g., ‘cpu’, ‘cuda:0’), or torch.device (e.g., torch.device(‘cpu’))
| Parameters: |
Parameters:
***f** – a file-like object (has to implement read, readline, tell, and seek), or a string containing a file name
***map_location** – can a string (e.g., ‘cpu’, ‘cuda:0’), a device (e.g., torch.device(‘cpu’))
|
| --- | --- |
| Returns: | A `ScriptModule` object. |
| --- | --- |
...
...
@@ -178,13 +177,12 @@ Warning
Tracing only correctly records functions and modules which are not data dependent (e.g., have conditionals on data in tensors) and do not have any untracked external dependencies (e.g., perform input/output or access global variables). If you trace such models, you may silently get incorrect results on subsequent invocations of the model. The tracer will try to emit warnings when doing something that may cause an incorrect trace to be produced.
| Parameters: |
Parameters:
***func** (_callable_ _or_ [_torch.nn.Module_](nn.html#torch.nn.Module"torch.nn.Module")) – a python function or torch.nn.Module that will be run with example_inputs. arguments and returns to func must be Tensors or (possibly nested) tuples that contain tensors.
***example_inputs** ([_tuple_](https://docs.python.org/3/library/stdtypes.html#tuple"(in Python v3.7)")) – a tuple of example inputs that will be passed to the function while tracing. The resulting trace can be run with inputs of different types and shapes assuming the traced operations support those types and shapes. example_inputs may also be a single Tensor in which case it is automatically wrapped in a tuple
@@ -12,15 +12,14 @@ If the object is already present in `model_dir`, it’s deserialized and returne
The default value of `model_dir` is `$TORCH_HOME/models` where `$TORCH_HOME` defaults to `~/.torch`. The default directory can be overridden with the `$TORCH_MODEL_ZOO` environment variable.
| Parameters: |
Parameters:
***url** (_string_) – URL of the object to download
***model_dir** (_string__,_ _optional_) – directory in which to save the object
***map_location** (_optional_) – a function or a dict specifying how to remap storage locations (see torch.load)
***progress** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – whether or not to display a progress bar to stderr
@@ -85,7 +85,7 @@ Spawns `nprocs` processes that run `fn` with `args`.
If one of the processes exits with a non-zero exit status, the remaining processes are killed and an exception is raised with the cause of termination. In the case an exception was caught in the child process, it is forwarded and its traceback is included in the exception raised in the parent process.
| Parameters: |
Parameters:
***fn** (_function_) –
...
...
@@ -98,8 +98,7 @@ If one of the processes exits with a non-zero exit status, the remaining process
***join** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")) – Perform a blocking join on all processes.
***daemon** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")) – The spawned processes’ daemon flag. If set to True, daemonic processes will be created.
|
| --- | --- |
| Returns: | None if `join` is `True`, [`SpawnContext`](#torch.multiprocessing.SpawnContext"torch.multiprocessing.SpawnContext") if `join` is `False` |
Fills the input Tensor with values drawn from the normal distribution 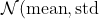).
Fills the input `Tensor` with a (semi) orthogonal matrix, as described in “Exact solutions to the nonlinear dynamics of learning in deep linear neural networks” - Saxe, A. et al. (2013). The input tensor must have at least 2 dimensions, and for tensors with more than 2 dimensions the trailing dimensions are flattened.
| Parameters: |
Parameters:
***tensor** – an n-dimensional `torch.Tensor`, where 
Fills the 2D input `Tensor` as a sparse matrix, where the non-zero elements will be drawn from the normal distribution 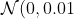), as described in “Deep learning via Hessian-free optimization” - Martens, J. (2010).
| Parameters: |
Parameters:
***tensor** – an n-dimensional `torch.Tensor`
***sparsity** – The fraction of elements in each column to be set to zero
Parameters need to be specified as collections that have a deterministic ordering that is consistent between runs. Examples of objects that don’t satisfy those properties are sets and iterators over values of dictionaries.
| Parameters: |
Parameters:
***params** (_iterable_) – an iterable of [`torch.Tensor`](tensors.html#torch.Tensor"torch.Tensor") s or [`dict`](https://docs.python.org/3/library/stdtypes.html#dict"(in Python v3.7)") s. Specifies what Tensors should be optimized.
***defaults** – (dict): a dict containing default values of optimization options (used when a parameter group doesn’t specify them).
|
| --- | --- |
```py
add_param_group(param_group)
...
...
@@ -112,13 +111,12 @@ Add a param group to the [`Optimizer`](#torch.optim.Optimizer "torch.optim.Optim
This can be useful when fine tuning a pre-trained network as frozen layers can be made trainable and added to the [`Optimizer`](#torch.optim.Optimizer"torch.optim.Optimizer") as training progresses.
| Parameters: |
Parameters:
***param_group** ([_dict_](https://docs.python.org/3/library/stdtypes.html#dict"(in Python v3.7)")) – Specifies what Tensors should be optimized along with group
It has been proposed in [ADADELTA: An Adaptive Learning Rate Method](https://arxiv.org/abs/1212.5701).
| Parameters: |
Parameters:
***params** (_iterable_) – iterable of parameters to optimize or dicts defining parameter groups
***rho** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_,_ _optional_) – coefficient used for computing a running average of squared gradients (default: 0.9)
...
...
@@ -175,8 +173,7 @@ It has been proposed in [ADADELTA: An Adaptive Learning Rate Method](https://arx
***lr** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_,_ _optional_) – coefficient that scale delta before it is applied to the parameters (default: 1.0)
***amsgrad** (_boolean__,_ _optional_) – whether to use the AMSGrad variant of this algorithm from the paper [On the Convergence of Adam and Beyond](https://openreview.net/forum?id=ryQu7f-RZ)(default: False)
|
| --- | --- |
```py
step(closure=None)
...
...
@@ -251,15 +246,14 @@ Implements lazy version of Adam algorithm suitable for sparse tensors.
In this variant, only moments that show up in the gradient get updated, and only those portions of the gradient get applied to the parameters.
| Parameters: |
Parameters:
***params** (_iterable_) – iterable of parameters to optimize or dicts defining parameter groups
***betas** (_Tuple__[_[_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_,_[_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_]__,_ _optional_) – coefficients used for computing running averages of gradient and its square (default: (0.9, 0.999))
***eps** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_,_ _optional_) – term added to the denominator to improve numerical stability (default: 1e-8)
|
| --- | --- |
```py
step(closure=None)
...
...
@@ -278,7 +272,7 @@ Implements Adamax algorithm (a variant of Adam based on infinity norm).
It has been proposed in [Adam: A Method for Stochastic Optimization](https://arxiv.org/abs/1412.6980).
| Parameters: |
Parameters:
***params** (_iterable_) – iterable of parameters to optimize or dicts defining parameter groups
@@ -286,8 +280,7 @@ It has been proposed in [Adam: A Method for Stochastic Optimization](https://arx
***eps** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_,_ _optional_) – term added to the denominator to improve numerical stability (default: 1e-8)
@@ -315,8 +308,7 @@ It has been proposed in [Acceleration of stochastic approximation by averaging](
***t0** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_,_ _optional_) – point at which to start averaging (default: 1e6)
This is a very memory intensive optimizer (it requires additional `param_bytes * (history_size + 1)` bytes). If it doesn’t fit in memory try reducing the history size, or use a different algorithm.
***max_iter** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")) – maximal number of iterations per optimization step (default: 20)
...
...
@@ -354,8 +346,7 @@ This is a very memory intensive optimizer (it requires additional `param_bytes *
***tolerance_change** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")) – termination tolerance on function value/parameter changes (default: 1e-9).
***history_size** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")) – update history size (default: 100).
|
| --- | --- |
```py
step(closure)
...
...
@@ -376,7 +367,7 @@ Proposed by G. Hinton in his [course](http://www.cs.toronto.edu/~tijmen/csc321/s
The centered version first appears in [Generating Sequences With Recurrent Neural Networks](https://arxiv.org/pdf/1308.0850v5.pdf).
| Parameters: |
Parameters:
***params** (_iterable_) – iterable of parameters to optimize or dicts defining parameter groups
@@ -386,8 +377,7 @@ The centered version first appears in [Generating Sequences With Recurrent Neura
***centered** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – if `True`, compute the centered RMSProp, the gradient is normalized by an estimation of its variance
Nesterov momentum is based on the formula from [On the importance of initialization and momentum in deep learning](http://www.cs.toronto.edu/%7Ehinton/absps/momentum.pdf).
| Parameters: |
Parameters:
***params** (_iterable_) – iterable of parameters to optimize or dicts defining parameter groups
***lr_lambda** (_function_ _or_ [_list_](https://docs.python.org/3/library/stdtypes.html#list"(in Python v3.7)")) – A function which computes a multiplicative factor given an integer parameter epoch, or a list of such functions, one for each group in optimizer.param_groups.
***last_epoch** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")) – The index of last epoch. Default: -1.
|
| --- | --- |
Example
...
...
@@ -534,15 +521,14 @@ class torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoc
Sets the learning rate of each parameter group to the initial lr decayed by gamma every step_size epochs. When last_epoch=-1, sets initial lr as lr.
***last_epoch** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")) – The index of last epoch. Default: -1.
|
| --- | --- |
Example
...
...
@@ -566,15 +552,14 @@ class torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, las
Set the learning rate of each parameter group to the initial lr decayed by gamma once the number of epoch reaches one of the milestones. When last_epoch=-1, sets initial lr as lr.
@@ -618,15 +602,14 @@ When last_epoch=-1, sets initial lr as lr.
It has been proposed in [SGDR: Stochastic Gradient Descent with Warm Restarts](https://arxiv.org/abs/1608.03983). Note that this only implements the cosine annealing part of SGDR, and not the restarts.
@@ -634,7 +617,7 @@ class torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0
Reduce learning rate when a metric has stopped improving. Models often benefit from reducing the learning rate by a factor of 2-10 once learning stagnates. This scheduler reads a metrics quantity and if no improvement is seen for a ‘patience’ number of epochs, the learning rate is reduced.
***mode** ([_str_](https://docs.python.org/3/library/stdtypes.html#str"(in Python v3.7)")) – One of `min`, `max`. In `min` mode, lr will be reduced when the quantity monitored has stopped decreasing; in `max` mode it will be reduced when the quantity monitored has stopped increasing. Default: ‘min’.
...
...
@@ -647,8 +630,7 @@ Reduce learning rate when a metric has stopped improving. Models often benefit f
***min_lr** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_or_[_list_](https://docs.python.org/3/library/stdtypes.html#list"(in Python v3.7)")) – A scalar or a list of scalars. A lower bound on the learning rate of all param groups or each group respectively. Default: 0.
***eps** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")) – Minimal decay applied to lr. If the difference between new and old lr is smaller than eps, the update is ignored. Default: 1e-8.
This function does exact same thing as [`torch.addmm()`](torch.html#torch.addmm"torch.addmm") in the forward, except that it supports backward for sparse matrix `mat1`. `mat1` need to have `sparse_dim = 2`. Note that the gradients of `mat1` is a coalesced sparse tensor.
| Parameters: |
Parameters:
***mat** ([_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – a dense matrix to be added
***mat1** (_SparseTensor_) – a sparse matrix to be multiplied
...
...
@@ -221,8 +221,7 @@ This function does exact same thing as [`torch.addmm()`](torch.html#torch.addmm
***beta** (_Number__,_ _optional_) – multiplier for `mat` ()
***alpha** (_Number__,_ _optional_) – multiplier for ()
|
| --- | --- |
```py
torch.sparse.mm(mat1,mat2)
...
...
@@ -230,13 +229,12 @@ torch.sparse.mm(mat1, mat2)
Performs a matrix multiplication of the sparse matrix `mat1` and dense matrix `mat2`. Similar to [`torch.mm()`](torch.html#torch.mm"torch.mm"), If `mat1` is a  tensor, `mat2` is a  tensor, out will be a  dense tensor. `mat1` need to have `sparse_dim = 2`. This function also supports backward for both matrices. Note that the gradients of `mat1` is a coalesced sparse tensor.
| Parameters: |
Parameters:
***mat1** (_SparseTensor_) – the first sparse matrix to be multiplied
***mat2** ([_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – the second dense matrix to be multiplied
|
| --- | --- |
Example:
...
...
@@ -277,14 +275,13 @@ All summed `dim` are squeezed (see [`torch.squeeze()`](torch.html#torch.squeeze
During backward, only gradients at `nnz` locations of `input` will propagate back. Note that the gradients of `input` is coalesced.
| Parameters: |
Parameters:
***input** ([_Tensor_](tensors.html#torch.Tensor"torch.Tensor")) – the input SparseTensor
***dim** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")_or_ _tuple of python:ints_) – a dimension or a list of dimensions to reduce. Default: reduce over all dims.
***dtype** (`torch.dtype`, optional) – the desired data type of returned Tensor. Default: dtype of `input`.
@@ -46,14 +46,13 @@ Returns a copy of this object in CUDA memory.
If this object is already in CUDA memory and on the correct device, then no copy is performed and the original object is returned.
| Parameters: |
Parameters:
***device** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")) – The destination GPU id. Defaults to the current device.
***non_blocking** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")) – If `True` and the source is in pinned memory, the copy will be asynchronous with respect to the host. Otherwise, the argument has no effect.
*****kwargs** – For compatibility, may contain the key `async` in place of the `non_blocking` argument.
|
| --- | --- |
```py
data_ptr()
...
...
@@ -91,14 +90,13 @@ If `shared` is `True`, then memory is shared between all processes. All changes
`size` is the number of elements in the storage. If `shared` is `False`, then the file must contain at least `size * sizeof(Type)` bytes (`Type` is the type of storage). If `shared` is `True` the file will be created if needed.
| Parameters: |
Parameters:
***filename** ([_str_](https://docs.python.org/3/library/stdtypes.html#str"(in Python v3.7)")) – file name to map
***shared** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")) – whether to share memory
***size** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")) – number of elements in the storage
|
| --- | --- |
```py
half()
...
...
@@ -182,12 +180,11 @@ Returns the type if `dtype` is not provided, else casts this object to the speci
If this is already of the correct type, no copy is performed and the original object is returned.
| Parameters: |
Parameters:
***dtype** ([_type_](https://docs.python.org/3/library/functions.html#type"(in Python v3.7)")_or_ _string_) – The desired type
***non_blocking** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")) – If `True`, and the source is in pinned memory and destination is on the GPU or vice versa, the copy is performed asynchronously with respect to the host. Otherwise, the argument has no effect.
*****kwargs** – For compatibility, may contain the key `async` in place of the `non_blocking` argument. The `async` arg is deprecated.
When data is a tensor `x`, [`new_tensor()`](#torch.Tensor.new_tensor"torch.Tensor.new_tensor") reads out ‘the data’ from whatever it is passed, and constructs a leaf variable. Therefore `tensor.new_tensor(x)` is equivalent to `x.clone().detach()` and `tensor.new_tensor(x, requires_grad=True)` is equivalent to `x.clone().detach().requires_grad_(True)`. The equivalents using `clone()` and `detach()` are recommended.
| Parameters: |
Parameters:
***data** (_array_like_) – The returned Tensor copies `data`.
***dtype** ([`torch.dtype`](tensor_attributes.html#torch.torch.dtype"torch.torch.dtype"), optional) – the desired type of returned tensor. Default: if None, same [`torch.dtype`](tensor_attributes.html#torch.torch.dtype"torch.torch.dtype") as this tensor.
***device** ([`torch.device`](tensor_attributes.html#torch.torch.device"torch.torch.device"), optional) – the desired device of returned tensor. Default: if None, same [`torch.device`](tensor_attributes.html#torch.torch.device"torch.torch.device") as this tensor.
***requires_grad** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – If autograd should record operations on the returned tensor. Default: `False`.
Returns a Tensor of size [`size`](#torch.Tensor.size"torch.Tensor.size") filled with `fill_value`. By default, the returned Tensor has the same [`torch.dtype`](tensor_attributes.html#torch.torch.dtype"torch.torch.dtype") and [`torch.device`](tensor_attributes.html#torch.torch.device"torch.torch.device") as this tensor.
| Parameters: |
Parameters:
***fill_value** (_scalar_) – the number to fill the output tensor with.
***dtype** ([`torch.dtype`](tensor_attributes.html#torch.torch.dtype"torch.torch.dtype"), optional) – the desired type of returned tensor. Default: if None, same [`torch.dtype`](tensor_attributes.html#torch.torch.dtype"torch.torch.dtype") as this tensor.
***device** ([`torch.device`](tensor_attributes.html#torch.torch.device"torch.torch.device"), optional) – the desired device of returned tensor. Default: if None, same [`torch.device`](tensor_attributes.html#torch.torch.device"torch.torch.device") as this tensor.
***requires_grad** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – If autograd should record operations on the returned tensor. Default: `False`.
Returns a Tensor of size [`size`](#torch.Tensor.size"torch.Tensor.size") filled with uninitialized data. By default, the returned Tensor has the same [`torch.dtype`](tensor_attributes.html#torch.torch.dtype"torch.torch.dtype") and [`torch.device`](tensor_attributes.html#torch.torch.device"torch.torch.device") as this tensor.
| Parameters: |
Parameters:
***dtype** ([`torch.dtype`](tensor_attributes.html#torch.torch.dtype"torch.torch.dtype"), optional) – the desired type of returned tensor. Default: if None, same [`torch.dtype`](tensor_attributes.html#torch.torch.dtype"torch.torch.dtype") as this tensor.
***device** ([`torch.device`](tensor_attributes.html#torch.torch.device"torch.torch.device"), optional) – the desired device of returned tensor. Default: if None, same [`torch.device`](tensor_attributes.html#torch.torch.device"torch.torch.device") as this tensor.
***requires_grad** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – If autograd should record operations on the returned tensor. Default: `False`.
Returns a Tensor of size [`size`](#torch.Tensor.size"torch.Tensor.size") filled with `1`. By default, the returned Tensor has the same [`torch.dtype`](tensor_attributes.html#torch.torch.dtype"torch.torch.dtype") and [`torch.device`](tensor_attributes.html#torch.torch.device"torch.torch.device") as this tensor.
| Parameters: |
Parameters:
***size** (_int..._) – a list, tuple, or `torch.Size` of integers defining the shape of the output tensor.
***dtype** ([`torch.dtype`](tensor_attributes.html#torch.torch.dtype"torch.torch.dtype"), optional) – the desired type of returned tensor. Default: if None, same [`torch.dtype`](tensor_attributes.html#torch.torch.dtype"torch.torch.dtype") as this tensor.
***device** ([`torch.device`](tensor_attributes.html#torch.torch.device"torch.torch.device"), optional) – the desired device of returned tensor. Default: if None, same [`torch.device`](tensor_attributes.html#torch.torch.device"torch.torch.device") as this tensor.
***requires_grad** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – If autograd should record operations on the returned tensor. Default: `False`.
Returns a Tensor of size [`size`](#torch.Tensor.size"torch.Tensor.size") filled with `0`. By default, the returned Tensor has the same [`torch.dtype`](tensor_attributes.html#torch.torch.dtype"torch.torch.dtype") and [`torch.device`](tensor_attributes.html#torch.torch.device"torch.torch.device") as this tensor.
| Parameters: |
Parameters:
***size** (_int..._) – a list, tuple, or `torch.Size` of integers defining the shape of the output tensor.
***dtype** ([`torch.dtype`](tensor_attributes.html#torch.torch.dtype"torch.torch.dtype"), optional) – the desired type of returned tensor. Default: if None, same [`torch.dtype`](tensor_attributes.html#torch.torch.dtype"torch.torch.dtype") as this tensor.
***device** ([`torch.device`](tensor_attributes.html#torch.torch.device"torch.torch.device"), optional) – the desired device of returned tensor. Default: if None, same [`torch.device`](tensor_attributes.html#torch.torch.device"torch.torch.device") as this tensor.
***requires_grad** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – If autograd should record operations on the returned tensor. Default: `False`.
|
| --- | --- |
Example:
...
...
@@ -587,13 +582,12 @@ Copies the elements from `src` into `self` tensor and returns `self`.
The `src` tensor must be [broadcastable](notes/broadcasting.html#broadcasting-semantics) with the `self` tensor. It may be of a different data type or reside on a different device.
| Parameters: |
Parameters:
***src** ([_Tensor_](#torch.Tensor"torch.Tensor")) – the source tensor to copy from
***non_blocking** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")) – if `True` and this copy is between CPU and GPU, the copy may occur asynchronously with respect to the host. For other cases, this argument has no effect.
|
| --- | --- |
```py
cos()→Tensor
...
...
@@ -641,13 +635,12 @@ Returns a copy of this object in CUDA memory.
If this object is already in CUDA memory and on the correct device, then no copy is performed and the original object is returned.
| Parameters: |
Parameters:
***device** ([`torch.device`](tensor_attributes.html#torch.torch.device"torch.torch.device")) – The destination GPU device. Defaults to the current CUDA device.
***non_blocking** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")) – If `True` and the source is in pinned memory, the copy will be asynchronous with respect to the host. Otherwise, the argument has no effect. Default: `False`.
|
| --- | --- |
```py
cumprod(dim,dtype=None)→Tensor
...
...
@@ -1034,14 +1027,13 @@ Note
When using the CUDA backend, this operation may induce nondeterministic behaviour that is not easily switched off. Please see the notes on [Reproducibility](notes/randomness.html) for background.
| Parameters: |
Parameters:
***dim** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")) – dimension along which to index
***index** (_LongTensor_) – indices of [`tensor`](torch.html#torch.tensor"torch.tensor") to select from
***tensor** ([_Tensor_](#torch.Tensor"torch.Tensor")) – the tensor containing values to add
|
| --- | --- |
Example:
...
...
@@ -1066,14 +1058,13 @@ Copies the elements of [`tensor`](torch.html#torch.tensor "torch.tensor") into t
The [`dim`](#torch.Tensor.dim"torch.Tensor.dim")th dimension of [`tensor`](torch.html#torch.tensor"torch.tensor") must have the same size as the length of `index` (which must be a vector), and all other dimensions must match `self`, or an error will be raised.
| Parameters: |
Parameters:
***dim** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")) – dimension along which to index
***index** (_LongTensor_) – indices of [`tensor`](torch.html#torch.tensor"torch.tensor") to select from
***tensor** ([_Tensor_](#torch.Tensor"torch.Tensor")) – the tensor containing values to copy
Fills the elements of the `self` tensor with value `val` by selecting the indices in the order given in `index`.
| Parameters: |
Parameters:
***dim** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")) – dimension along which to index
***index** (_LongTensor_) – indices of `self` tensor to fill in
***val** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")) – the value to fill with
|
| --- | --- |
```py
Example::
...
...
@@ -1127,14 +1117,13 @@ Puts values from the tensor `value` into the tensor `self` using the indices spe
If `accumulate` is `True`, the elements in [`tensor`](torch.html#torch.tensor"torch.tensor") are added to `self`. If accumulate is `False`, the behavior is undefined if indices contain duplicate elements.
| Parameters: |
Parameters:
***indices** (_tuple of LongTensor_) – tensors used to index into `self`.
***value** ([_Tensor_](#torch.Tensor"torch.Tensor")) – tensor of same dtype as `self`.
***accumulate** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")) – whether to accumulate into self
Copies elements from `source` into `self` tensor at positions where the `mask` is one. The shape of `mask` must be [broadcastable](notes/broadcasting.html#broadcasting-semantics) with the shape of the underlying tensor. The `source` should have at least as many elements as the number of ones in `mask`
| Parameters: |
Parameters:
***mask** ([_ByteTensor_](#torch.ByteTensor"torch.ByteTensor")) – the binary mask
***source** ([_Tensor_](#torch.Tensor"torch.Tensor")) – the tensor to copy from
|
| --- | --- |
Note
...
...
@@ -1346,13 +1334,12 @@ masked_fill_(mask, value)
Fills elements of `self` tensor with `value` where `mask` is one. The shape of `mask` must be [broadcastable](notes/broadcasting.html#broadcasting-semantics) with the shape of the underlying tensor.
| Parameters: |
Parameters:
***mask** ([_ByteTensor_](#torch.ByteTensor"torch.ByteTensor")) – the binary mask
***value** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")) – the value to fill in with
|
| --- | --- |
```py
masked_select(mask)→Tensor
...
...
@@ -1622,14 +1609,13 @@ Copies the elements from [`tensor`](torch.html#torch.tensor "torch.tensor") into
If `accumulate` is `True`, the elements in [`tensor`](torch.html#torch.tensor"torch.tensor") are added to `self`. If accumulate is `False`, the behavior is undefined if indices contain duplicate elements.
| Parameters: |
Parameters:
***indices** (_LongTensor_) – the indices into self
***tensor** ([_Tensor_](#torch.Tensor"torch.Tensor")) – the tensor containing values to copy from
***accumulate** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")) – whether to accumulate into self
|
| --- | --- |
Example:
...
...
@@ -1846,14 +1832,13 @@ This is the reverse operation of the manner described in [`gather()`](#torch.Ten
Moreover, as for [`gather()`](#torch.Tensor.gather"torch.Tensor.gather"), the values of `index` must be between `0` and `self.size(dim) - 1` inclusive, and all values in a row along the specified dimension [`dim`](#torch.Tensor.dim"torch.Tensor.dim") must be unique.
| Parameters: |
Parameters:
***dim** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")) – the axis along which to index
***index** (_LongTensor_) – the indices of elements to scatter, can be either empty or the same size of src. When empty, the operation returns identity
***src** ([_Tensor_](#torch.Tensor"torch.Tensor")_or_[_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")) – the source element(s) to scatter
|
| --- | --- |
Example:
...
...
@@ -1897,14 +1882,13 @@ Note
When using the CUDA backend, this operation may induce nondeterministic behaviour that is not easily switched off. Please see the notes on [Reproducibility](notes/randomness.html) for background.
| Parameters: |
Parameters:
***dim** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")) – the axis along which to index
***index** (_LongTensor_) – the indices of elements to scatter and add, can be either empty or the same size of src. When empty, the operation returns identity.
***other** ([_Tensor_](#torch.Tensor"torch.Tensor")) – the source elements to scatter and add
Returns a new SparseTensor with values from Tensor `input` filtered by indices of `mask` and values are ignored. `input` and `mask` must have the same shape.
| Parameters: |
Parameters:
***input** ([_Tensor_](#torch.Tensor"torch.Tensor")) – an input Tensor
***mask** (_SparseTensor_) – a SparseTensor which we filter `input` based on its indices
|
| --- | --- |
Example:
...
...
@@ -2424,14 +2405,13 @@ Returns the type if `dtype` is not provided, else casts this object to the speci
If this is already of the correct type, no copy is performed and the original object is returned.
| Parameters: |
Parameters:
***dtype** ([_type_](https://docs.python.org/3/library/functions.html#type"(in Python v3.7)")_or_ _string_) – The desired type
***non_blocking** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")) – If `True`, and the source is in pinned memory and destination is on the GPU or vice versa, the copy is performed asynchronously with respect to the host. Otherwise, the argument has no effect.
*****kwargs** – For compatibility, may contain the key `async` in place of the `non_blocking` argument. The `async` arg is deprecated.
|
| --- | --- |
```py
type_as(tensor)→Tensor
...
...
@@ -2464,14 +2444,13 @@ If `sizedim` is the size of dimension dim for `self`, the size of dimension [`di
An additional dimension of size size is appended in the returned tensor.
| Parameters: |
Parameters:
***dim** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")) – dimension in which unfolding happens
***size** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")) – the size of each slice that is unfolded
***step** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")) – the step between each slice
|
| --- | --- |
Example:
...
...
@@ -2609,14 +2588,13 @@ Returns True if all elements in each row of the tensor in the given dimension `d
If `keepdim` is `True`, the output tensor is of the same size as `input` except in the dimension `dim` where it is of size 1. Otherwise, `dim` is squeezed (see [`torch.squeeze()`](torch.html#torch.squeeze"torch.squeeze")), resulting in the output tensor having 1 fewer dimension than `input`.
| Parameters: |
Parameters:
***dim** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")) – the dimension to reduce
***keepdim** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")) – whether the output tensor has `dim` retained or not
***out** ([_Tensor_](#torch.Tensor"torch.Tensor")_,_ _optional_) – the output tensor
|
| --- | --- |
Example:
...
...
@@ -2661,14 +2639,13 @@ Returns True if any elements in each row of the tensor in the given dimension `d
If `keepdim` is `True`, the output tensor is of the same size as `input` except in the dimension `dim` where it is of size 1. Otherwise, `dim` is squeezed (see [`torch.squeeze()`](torch.html#torch.squeeze"torch.squeeze")), resulting in the output tensor having 1 fewer dimension than `input`.
| Parameters: |
Parameters:
***dim** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")) – the dimension to reduce
***keepdim** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")) – whether the output tensor has `dim` retained or not
***out** ([_Tensor_](#torch.Tensor"torch.Tensor")_,_ _optional_) – the output tensor
All the datasets have almost similar API. They all have two common arguments: `transform` and `target_transform` to transform the input and target respectively.
***root** (_string_) – Root directory of dataset where `processed/training.pt` and `processed/test.pt` exist.
***train** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – If True, creates dataset from `training.pt`, otherwise from `test.pt`.
...
...
@@ -50,17 +50,16 @@ class torchvision.datasets.MNIST(root, train=True, transform=None, target_transf
***transform** (_callable__,_ _optional_) – A function/transform that takes in an PIL image and returns a transformed version. E.g, `transforms.RandomCrop`
***target_transform** (_callable__,_ _optional_) – A function/transform that takes in the target and transforms it.
***root** (_string_) – Root directory of dataset where `processed/training.pt` and `processed/test.pt` exist.
***train** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – If True, creates dataset from `training.pt`, otherwise from `test.pt`.
...
...
@@ -68,17 +67,16 @@ class torchvision.datasets.FashionMNIST(root, train=True, transform=None, target
***transform** (_callable__,_ _optional_) – A function/transform that takes in an PIL image and returns a transformed version. E.g, `transforms.RandomCrop`
***target_transform** (_callable__,_ _optional_) – A function/transform that takes in the target and transforms it.
***root** (_string_) – Root directory of dataset where `processed/training.pt` and `processed/test.pt` exist.
***split** (_string_) – The dataset has 6 different splits: `byclass`, `bymerge`, `balanced`, `letters`, `digits` and `mnist`. This argument specifies which one to use.
...
...
@@ -87,29 +85,27 @@ class torchvision.datasets.EMNIST(root, split, **kwargs)¶
***transform** (_callable__,_ _optional_) – A function/transform that takes in an PIL image and returns a transformed version. E.g, `transforms.RandomCrop`
***target_transform** (_callable__,_ _optional_) – A function/transform that takes in the target and transforms it.
|
| --- | --- |
Note
These require the [COCO API to be installed](https://github.com/pdollar/coco/tree/master/PythonAPI)
***root** (_string_) – Root directory where images are downloaded to.
***annFile** (_string_) – Path to json annotation file.
***transform** (_callable__,_ _optional_) – A function/transform that takes in an PIL image and returns a transformed version. E.g, `transforms.ToTensor`
***target_transform** (_callable__,_ _optional_) – A function/transform that takes in the target and transforms it.
|
| --- | --- |
Example
...
...
@@ -142,7 +138,7 @@ u'A mountain view with a plume of smoke in the background']
***root** (_string_) – Root directory where images are downloaded to.
***annFile** (_string_) – Path to json annotation file.
***transform** (_callable__,_ _optional_) – A function/transform that takes in an PIL image and returns a transformed version. E.g, `transforms.ToTensor`
***target_transform** (_callable__,_ _optional_) – A function/transform that takes in the target and transforms it.
***root** (_string_) – Root directory for the database files.
***classes** (_string_ _or_ [_list_](https://docs.python.org/3/library/stdtypes.html#list"(in Python v3.7)")) – One of {‘train’, ‘val’, ‘test’} or a list of categories to load. e,g. [‘bedroom_train’, ‘church_train’].
***transform** (_callable__,_ _optional_) – A function/transform that takes in an PIL image and returns a transformed version. E.g, `transforms.RandomCrop`
***target_transform** (_callable__,_ _optional_) – A function/transform that takes in the target and transforms it.
A generic data loader where the images are arranged in this way:
...
...
@@ -229,18 +223,17 @@ root/cat/asd932_.png
```
| Parameters: |
Parameters:
***root** (_string_) – Root directory path.
***transform** (_callable__,_ _optional_) – A function/transform that takes in an PIL image and returns a transformed version. E.g, `transforms.RandomCrop`
***target_transform** (_callable__,_ _optional_) – A function/transform that takes in the target and transforms it.
***loader** – A function to load an image given its path.
A generic data loader where the samples are arranged in this way:
...
...
@@ -269,7 +262,7 @@ root/class_y/asd932_.ext
```
| Parameters: |
Parameters:
***root** (_string_) – Root directory path.
***loader** (_callable_) – A function to load a sample given its path.
...
...
@@ -277,11 +270,10 @@ root/class_y/asd932_.ext
***transform** (_callable__,_ _optional_) – A function/transform that takes in a sample and returns a transformed version. E.g, `transforms.RandomCrop` for images.
***target_transform** – A function/transform that takes in the target and transforms it.
|
| --- | --- |
```py
__getitem__(index)¶
__getitem__(index)
```
...
...
@@ -297,13 +289,13 @@ This should simply be implemented with an `ImageFolder` dataset. The data is pre
[Here is an example](https://github.com/pytorch/examples/blob/e0d33a69bec3eb4096c265451dbb85975eb961ea/imagenet/main.py#L113-L126).
***root** (_string_) – Root directory of dataset where directory `cifar-10-batches-py` exists or will be saved to if download is set to True.
***train** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – If True, creates dataset from training set, otherwise creates from test set.
...
...
@@ -311,11 +303,10 @@ class torchvision.datasets.CIFAR10(root, train=True, transform=None, target_tran
***target_transform** (_callable__,_ _optional_) – A function/transform that takes in the target and transforms it.
***download** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – If true, downloads the dataset from the internet and puts it in root directory. If dataset is already downloaded, it is not downloaded again.
***root** (_string_) – Root directory of dataset where directory `stl10_binary` exists.
***split** (_string_) – One of {‘train’, ‘test’, ‘unlabeled’, ‘train+unlabeled’}. Accordingly dataset is selected.
...
...
@@ -349,11 +340,10 @@ class torchvision.datasets.STL10(root, split='train', transform=None, target_tra
***target_transform** (_callable__,_ _optional_) – A function/transform that takes in the target and transforms it.
***download** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – If true, downloads the dataset from the internet and puts it in root directory. If dataset is already downloaded, it is not downloaded again.
[SVHN](http://ufldl.stanford.edu/housenumbers/) Dataset. Note: The SVHN dataset assigns the label `10` to the digit `0`. However, in this Dataset, we assign the label `0` to the digit `0` to be compatible with PyTorch loss functions which expect the class labels to be in the range `[0, C-1]`
| Parameters: |
Parameters:
***root** (_string_) – Root directory of dataset where directory `SVHN` exists.
***split** (_string_) – One of {‘train’, ‘test’, ‘extra’}. Accordingly dataset is selected. ‘extra’ is Extra training set.
...
...
@@ -379,11 +369,10 @@ class torchvision.datasets.SVHN(root, split='train', transform=None, target_tran
***target_transform** (_callable__,_ _optional_) – A function/transform that takes in the target and transforms it.
***download** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – If true, downloads the dataset from the internet and puts it in root directory. If dataset is already downloaded, it is not downloaded again.
[Learning Local Image Descriptors Data](http://phototour.cs.washington.edu/patches/default.htm) Dataset.
| Parameters: |
Parameters:
***root** (_string_) – Root directory where images are.
***name** (_string_) – Name of the dataset to load.
***transform** (_callable__,_ _optional_) – A function/transform that takes in an PIL image and returns a transformed version.
***download** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – If true, downloads the dataset from the internet and puts it in root directory. If dataset is already downloaded, it is not downloaded again.
SqueezeNet model architecture from the [“SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size”](https://arxiv.org/abs/1602.07360) paper.
...
...
@@ -236,7 +236,7 @@ SqueezeNet model architecture from the [“SqueezeNet: AlexNet-level accuracy wi
SqueezeNet 1.1 model from the [official SqueezeNet repo](https://github.com/DeepScale/SqueezeNet/tree/master/SqueezeNet_v1.1). SqueezeNet 1.1 has 2.4x less computation and slightly fewer parameters than SqueezeNet 1.0, without sacrificing accuracy.
...
...
@@ -248,7 +248,7 @@ SqueezeNet 1.1 model from the [official SqueezeNet repo](https://github.com/Deep
***tensor** ([_Tensor_](../tensors.html#torch.Tensor"torch.Tensor")_or_[_list_](https://docs.python.org/3/library/stdtypes.html#list"(in Python v3.7)")) – 4D mini-batch Tensor of shape (B x C x H x W) or a list of images all of the same size.
***nrow** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")_,_ _optional_) – Number of images displayed in each row of the grid. The Final grid size is (B / nrow, nrow). Default is 8.
...
...
@@ -19,24 +19,21 @@ Make a grid of images.
***scale_each** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")_,_ _optional_) – If True, scale each image in the batch of images separately rather than the (min, max) over all images.
***pad_value** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_,_ _optional_) – Value for the padded pixels.
|
| --- | --- |
Example
See this notebook [here](https://gist.github.com/anonymous/bf16430f7750c023141c562f3e9f2a91)
***tensor** ([_Tensor_](../tensors.html#torch.Tensor"torch.Tensor")_or_[_list_](https://docs.python.org/3/library/stdtypes.html#list"(in Python v3.7)")) – Image to be saved. If given a mini-batch tensor, saves the tensor as a grid of images by calling `make_grid`.
*****kwargs** – Other arguments are documented in `make_grid`.