Context-manager that disabled gradient calculation.
Disabling gradient calculation is useful for inference, when you are sure that you will not call `Tensor.backward()`. It will reduce memory consumption for computations that would otherwise have <cite>requires_grad=True</cite>. In this mode, the result of every computation will have <cite>requires_grad=False</cite>, even when the inputs have <cite>requires_grad=True</cite>.
Disabling gradient calculation is useful for inference, when you are sure that you will not call `Tensor.backward()`. It will reduce memory consumption for computations that would otherwise have `requires_grad=True`. In this mode, the result of every computation will have `requires_grad=False`, even when the inputs have `requires_grad=True`.
Also functions as a decorator.
...
...
@@ -532,13 +532,13 @@ Example
When viewing a profile created using [`emit_nvtx`](#torch.autograd.profiler.emit_nvtx"torch.autograd.profiler.emit_nvtx") in the Nvidia Visual Profiler, correlating each backward-pass op with the corresponding forward-pass op can be difficult. To ease this task, [`emit_nvtx`](#torch.autograd.profiler.emit_nvtx"torch.autograd.profiler.emit_nvtx") appends sequence number information to the ranges it generates.
During the forward pass, each function range is decorated with `seq=<N>`. `seq` is a running counter, incremented each time a new backward Function object is created and stashed for backward. Thus, the <cite>seq=<N></cite> annotation associated with each forward function range tells you that if a backward Function object is created by this forward function, the backward object will receive sequence number N. During the backward pass, the top-level range wrapping each C++ backward Function’s `apply()` call is decorated with `stashed seq=<M>`. `M` is the sequence number that the backward object was created with. By comparing `stashed seq` numbers in backward with `seq` numbers in forward, you can track down which forward op created each backward Function.
During the forward pass, each function range is decorated with `seq=<N>`. `seq` is a running counter, incremented each time a new backward Function object is created and stashed for backward. Thus, the `seq=<N>` annotation associated with each forward function range tells you that if a backward Function object is created by this forward function, the backward object will receive sequence number N. During the backward pass, the top-level range wrapping each C++ backward Function’s `apply()` call is decorated with `stashed seq=<M>`. `M` is the sequence number that the backward object was created with. By comparing `stashed seq` numbers in backward with `seq` numbers in forward, you can track down which forward op created each backward Function.
Any functions executed during the backward pass are also decorated with `seq=<N>`. During default backward (with `create_graph=False`) this information is irrelevant, and in fact, `N` may simply be 0 for all such functions. Only the top-level ranges associated with backward Function objects’ `apply()` methods are useful, as a way to correlate these Function objects with the earlier forward pass.
**Double-backward**
If, on the other hand, a backward pass with `create_graph=True` is underway (in other words, if you are setting up for a double-backward), each function’s execution during backward is given a nonzero, useful `seq=<N>`. Those functions may themselves create Function objects to be executed later during double-backward, just as the original functions in the forward pass did. The relationship between backward and double-backward is conceptually the same as the relationship between forward and backward: The functions still emit current-sequence-number-tagged ranges, the Function objects they create still stash those sequence numbers, and during the eventual double-backward, the Function objects’ `apply()` ranges are still tagged with `stashed seq` numbers, which can be compared to <cite>seq</cite> numbers from the backward pass.
If, on the other hand, a backward pass with `create_graph=True` is underway (in other words, if you are setting up for a double-backward), each function’s execution during backward is given a nonzero, useful `seq=<N>`. Those functions may themselves create Function objects to be executed later during double-backward, just as the original functions in the forward pass did. The relationship between backward and double-backward is conceptually the same as the relationship between forward and backward: The functions still emit current-sequence-number-tagged ranges, the Function objects they create still stash those sequence numbers, and during the eventual double-backward, the Function objects’ `apply()` ranges are still tagged with `stashed seq` numbers, which can be compared to `seq` numbers from the backward pass.
<cite>torch.utils.bottleneck</cite> is a tool that can be used as an initial step for debugging bottlenecks in your program. It summarizes runs of your script with the Python profiler and PyTorch’s autograd profiler.
`torch.utils.bottleneck` is a tool that can be used as an initial step for debugging bottlenecks in your program. It summarizes runs of your script with the Python profiler and PyTorch’s autograd profiler.
where [args] are any number of arguments to <cite>script.py</cite>, or run `python -m torch.utils.bottleneck -h` for more usage instructions.
where [args] are any number of arguments to `script.py`, or run `python -m torch.utils.bottleneck -h` for more usage instructions.
@@ -62,7 +62,7 @@ You can use both tensors and storages as arguments. If a given object is not all
torch.cuda.empty_cache()
```
Releases all unoccupied cached memory currently held by the caching allocator so that those can be used in other GPU application and visible in <cite>nvidia-smi</cite>.
Releases all unoccupied cached memory currently held by the caching allocator so that those can be used in other GPU application and visible in `nvidia-smi`.
Note
...
...
@@ -141,7 +141,7 @@ Returns the current GPU memory usage by tensors in bytes for a given device.
Note
This is likely less than the amount shown in <cite>nvidia-smi</cite> since some unused memory can be held by the caching allocator and some context needs to be created on GPU. See [Memory management](notes/cuda.html#cuda-memory-management) for more details about GPU memory management.
This is likely less than the amount shown in `nvidia-smi` since some unused memory can be held by the caching allocator and some context needs to be created on GPU. See [Memory management](notes/cuda.html#cuda-memory-management) for more details about GPU memory management.
```py
torch.cuda.memory_cached(device=None)
...
...
@@ -488,7 +488,7 @@ Makes a given stream wait for the event.
torch.cuda.empty_cache()
```
Releases all unoccupied cached memory currently held by the caching allocator so that those can be used in other GPU application and visible in <cite>nvidia-smi</cite>.
Releases all unoccupied cached memory currently held by the caching allocator so that those can be used in other GPU application and visible in `nvidia-smi`.
Note
...
...
@@ -505,7 +505,7 @@ Returns the current GPU memory usage by tensors in bytes for a given device.
Note
This is likely less than the amount shown in <cite>nvidia-smi</cite> since some unused memory can be held by the caching allocator and some context needs to be created on GPU. See [Memory management](notes/cuda.html#cuda-memory-management) for more details about GPU memory management.
This is likely less than the amount shown in `nvidia-smi` since some unused memory can be held by the caching allocator and some context needs to be created on GPU. See [Memory management](notes/cuda.html#cuda-memory-management) for more details about GPU memory management.
@@ -62,9 +62,9 @@ For the full list of NCCL environment variables, please refer to [NVIDIA NCCL’
## Basics
The <cite>torch.distributed</cite> package provides PyTorch support and communication primitives for multiprocess parallelism across several computation nodes running on one or more machines. The class [`torch.nn.parallel.DistributedDataParallel()`](nn.html#torch.nn.parallel.DistributedDataParallel"torch.nn.parallel.DistributedDataParallel") builds on this functionality to provide synchronous distributed training as a wrapper around any PyTorch model. This differs from the kinds of parallelism provided by [Multiprocessing package - torch.multiprocessing](multiprocessing.html) and [`torch.nn.DataParallel()`](nn.html#torch.nn.DataParallel"torch.nn.DataParallel") in that it supports multiple network-connected machines and in that the user must explicitly launch a separate copy of the main training script for each process.
The `torch.distributed` package provides PyTorch support and communication primitives for multiprocess parallelism across several computation nodes running on one or more machines. The class [`torch.nn.parallel.DistributedDataParallel()`](nn.html#torch.nn.parallel.DistributedDataParallel"torch.nn.parallel.DistributedDataParallel") builds on this functionality to provide synchronous distributed training as a wrapper around any PyTorch model. This differs from the kinds of parallelism provided by [Multiprocessing package - torch.multiprocessing](multiprocessing.html) and [`torch.nn.DataParallel()`](nn.html#torch.nn.DataParallel"torch.nn.DataParallel") in that it supports multiple network-connected machines and in that the user must explicitly launch a separate copy of the main training script for each process.
In the single-machine synchronous case, <cite>torch.distributed</cite> or the [`torch.nn.parallel.DistributedDataParallel()`](nn.html#torch.nn.parallel.DistributedDataParallel"torch.nn.parallel.DistributedDataParallel") wrapper may still have advantages over other approaches to data-parallelism, including [`torch.nn.DataParallel()`](nn.html#torch.nn.DataParallel"torch.nn.DataParallel"):
In the single-machine synchronous case, `torch.distributed` or the [`torch.nn.parallel.DistributedDataParallel()`](nn.html#torch.nn.parallel.DistributedDataParallel"torch.nn.parallel.DistributedDataParallel") wrapper may still have advantages over other approaches to data-parallelism, including [`torch.nn.DataParallel()`](nn.html#torch.nn.DataParallel"torch.nn.DataParallel"):
* Each process maintains its own optimizer and performs a complete optimization step with each iteration. While this may appear redundant, since the gradients have already been gathered together and averaged across processes and are thus the same for every process, this means that no parameter broadcast step is needed, reducing time spent transferring tensors between nodes.
* Each process contains an independent Python interpreter, eliminating the extra interpreter overhead and “GIL-thrashing” that comes from driving several execution threads, model replicas, or GPUs from a single Python process. This is especially important for models that make heavy use of the Python runtime, including models with recurrent layers or many small components.
...
...
@@ -219,7 +219,7 @@ This is the default method, meaning that `init_method` does not have to be speci
By default collectives operate on the default group (also called the world) and require all processes to enter the distributed function call. However, some workloads can benefit from more fine-grained communication. This is where distributed groups come into play. [`new_group()`](#torch.distributed.new_group"torch.distributed.new_group") function can be used to create new groups, with arbitrary subsets of all processes. It returns an opaque group handle that can be given as a `group` argument to all collectives (collectives are distributed functions to exchange information in certain well-known programming patterns).
Currently <cite>torch.distributed</cite> does not support creating groups with different backends. In other words, each group being created will use the same backend as you specified in [`init_process_group()`](#torch.distributed.init_process_group"torch.distributed.init_process_group").
Currently `torch.distributed` does not support creating groups with different backends. In other words, each group being created will use the same backend as you specified in [`init_process_group()`](#torch.distributed.init_process_group"torch.distributed.init_process_group").
@@ -627,9 +627,9 @@ Only nccl backend is currently supported tensors should only be GPU tensors
## Launch utility
The <cite>torch.distributed</cite> package also provides a launch utility in <cite>torch.distributed.launch</cite>. This helper utility can be used to launch multiple processes per node for distributed training. This utility also supports both python2 and python3.
The `torch.distributed` package also provides a launch utility in `torch.distributed.launch`. This helper utility can be used to launch multiple processes per node for distributed training. This utility also supports both python2 and python3.
<cite>torch.distributed.launch</cite> is a module that spawns up multiple distributed training processes on each of the training nodes.
`torch.distributed.launch` is a module that spawns up multiple distributed training processes on each of the training nodes.
The utility can be used for single-node distributed training, in which one or more processes per node will be spawned. The utility can be used for either CPU training or GPU training. If the utility is used for GPU training, each distributed process will be operating on a single GPU. This can achieve well-improved single-node training performance. It can also be used in multi-node distributed training, by spawning up multiple processes on each node for well-improved multi-node distributed training performance as well. This will especially be benefitial for systems with multiple Infiniband interfaces that have direct-GPU support, since all of them can be utilized for aggregated communication bandwidth.
@@ -26,9 +26,9 @@ Currently torch.distributed.deprecated supports four backends, each with differe
## Basics
The <cite>torch.distributed.deprecated</cite> package provides PyTorch support and communication primitives for multiprocess parallelism across several computation nodes running on one or more machines. The class `torch.nn.parallel.deprecated.DistributedDataParallel()` builds on this functionality to provide synchronous distributed training as a wrapper around any PyTorch model. This differs from the kinds of parallelism provided by [Multiprocessing package - torch.multiprocessing](multiprocessing.html) and [`torch.nn.DataParallel()`](nn.html#torch.nn.DataParallel"torch.nn.DataParallel") in that it supports multiple network-connected machines and in that the user must explicitly launch a separate copy of the main training script for each process.
The `torch.distributed.deprecated` package provides PyTorch support and communication primitives for multiprocess parallelism across several computation nodes running on one or more machines. The class `torch.nn.parallel.deprecated.DistributedDataParallel()` builds on this functionality to provide synchronous distributed training as a wrapper around any PyTorch model. This differs from the kinds of parallelism provided by [Multiprocessing package - torch.multiprocessing](multiprocessing.html) and [`torch.nn.DataParallel()`](nn.html#torch.nn.DataParallel"torch.nn.DataParallel") in that it supports multiple network-connected machines and in that the user must explicitly launch a separate copy of the main training script for each process.
In the single-machine synchronous case, <cite>torch.distributed.deprecated</cite> or the `torch.nn.parallel.deprecated.DistributedDataParallel()` wrapper may still have advantages over other approaches to data-parallelism, including [`torch.nn.DataParallel()`](nn.html#torch.nn.DataParallel"torch.nn.DataParallel"):
In the single-machine synchronous case, `torch.distributed.deprecated` or the `torch.nn.parallel.deprecated.DistributedDataParallel()` wrapper may still have advantages over other approaches to data-parallelism, including [`torch.nn.DataParallel()`](nn.html#torch.nn.DataParallel"torch.nn.DataParallel"):
* Each process maintains its own optimizer and performs a complete optimization step with each iteration. While this may appear redundant, since the gradients have already been gathered together and averaged across processes and are thus the same for every process, this means that no parameter broadcast step is needed, reducing time spent transferring tensors between nodes.
* Each process contains an independent Python interpreter, eliminating the extra interpreter overhead and “GIL-thrashing” that comes from driving several execution threads, model replicas, or GPUs from a single Python process. This is especially important for models that make heavy use of the Python runtime, including models with recurrent layers or many small components.
...
...
@@ -457,9 +457,9 @@ Only NCCL backend is currently supported. `output_tensor_lists` and `input_tenso
## Launch utility
The <cite>torch.distributed.deprecated</cite> package also provides a launch utility in <cite>torch.distributed.deprecated.launch</cite>.
The `torch.distributed.deprecated` package also provides a launch utility in `torch.distributed.deprecated.launch`.
<cite>torch.distributed.launch</cite> is a module that spawns up multiple distributed training processes on each of the training nodes.
`torch.distributed.launch` is a module that spawns up multiple distributed training processes on each of the training nodes.
The utility can be used for single-node distributed training, in which one or more processes per node will be spawned. The utility can be used for either CPU training or GPU training. If the utility is used for GPU training, each distributed process will be operating on a single GPU. This can achieve well-improved single-node training performance. It can also be used in multi-node distributed training, by spawning up multiple processes on each node for well-improved multi-node distributed training performance as well. This will especially be benefitial for systems with multiple Infiniband interfaces that have direct-GPU support, since all of them can be utilized for aggregated communication bandwidth.
@@ -95,7 +95,7 @@ CUDA support with mixed compilation is provided. Simply pass CUDA source files (
***extra_include_paths** – optional list of include directories to forward to the build.
***build_directory** – optional path to use as build workspace.
***verbose** – If `True`, turns on verbose logging of load steps.
***with_cuda** – Determines whether CUDA headers and libraries are added to the build. If set to `None` (default), this value is automatically determined based on the existence of `.cu` or `.cuh` in `sources`. Set it to <cite>True`</cite> to force CUDA headers and libraries to be included.
***with_cuda** – Determines whether CUDA headers and libraries are added to the build. If set to `None` (default), this value is automatically determined based on the existence of `.cu` or `.cuh` in `sources`. Set it to `True`` to force CUDA headers and libraries to be included.
* **is_python_module** – If `True` (default), imports the produced shared library as a Python module. If `False`, loads it into the process as a plain dynamic library.
|
...
...
@@ -138,7 +138,7 @@ See [`load()`](#torch.utils.cpp_extension.load "torch.utils.cpp_extension.load")
* **cpp_sources** – A string, or list of strings, containing C++ source code.
* **cuda_sources** – A string, or list of strings, containing CUDA source code.
* **functions** – A list of function names for which to generate function bindings. If a dictionary is given, it should map function names to docstrings (which are otherwise just the function names).
***with_cuda** – Determines whether CUDA headers and libraries are added to the build. If set to `None` (default), this value is automatically determined based on whether `cuda_sources` is provided. Set it to <cite>True`</cite> to force CUDA headers and libraries to be included.
* **with_cuda** – Determines whether CUDA headers and libraries are added to the build. If set to `None` (default), this value is automatically determined based on whether `cuda_sources` is provided. Set it to `True`` to force CUDA headers and libraries to be included.
@@ -10,11 +10,11 @@ Load a model from a github repo, with pretrained weights.
| Parameters: |
***github** – Required, a string with format “repo_owner/repo_name[:tag_name]” with an optional tag/branch. The default branch is <cite>master</cite> if not specified. Example: ‘pytorch/vision[:hub]’
***github** – Required, a string with format “repo_owner/repo_name[:tag_name]” with an optional tag/branch. The default branch is `master` if not specified. Example: ‘pytorch/vision[:hub]’
***model** – Required, a string of callable name defined in repo’s hubconf.py
***force_reload** – Optional, whether to discard the existing cache and force a fresh download. Default is <cite>False</cite>.
****args** – Optional, the corresponding args for callable <cite>model</cite>.
*****kwargs** – Optional, the corresponding kwargs for callable <cite>model</cite>.
***force_reload** – Optional, whether to discard the existing cache and force a fresh download. Default is `False`.
****args** – Optional, the corresponding args for callable `model`.
*****kwargs** – Optional, the corresponding kwargs for callable `model`.
Load a `ScriptModule` previously saved with `save`
All previously saved modules, no matter their device, are first loaded onto CPU, and then are moved to the devices they were saved from. If this fails (e.g. because the run time system doesn’t have certain devices), an exception is raised. However, storages can be dynamically remapped to an alternative set of devices using the <cite>map_location</cite> argument. Comparing to [`torch.load()`](torch.html#torch.load"torch.load"), <cite>map_location</cite> in this function is simplified, which only accepts a string (e.g., ‘cpu’, ‘cuda:0’), or torch.device (e.g., torch.device(‘cpu’))
All previously saved modules, no matter their device, are first loaded onto CPU, and then are moved to the devices they were saved from. If this fails (e.g. because the run time system doesn’t have certain devices), an exception is raised. However, storages can be dynamically remapped to an alternative set of devices using the `map_location` argument. Comparing to [`torch.load()`](torch.html#torch.load"torch.load"), `map_location` in this function is simplified, which only accepts a string (e.g., ‘cpu’, ‘cuda:0’), or torch.device (e.g., torch.device(‘cpu’))
| Parameters: |
...
...
@@ -915,7 +915,7 @@ graph(%0 : Float(3, 4)) {
```
We can fix this by modifying the code to not use the in-place update, but rather build up the result tensor out-of-place with <cite>torch.cat</cite>:
We can fix this by modifying the code to not use the in-place update, but rather build up the result tensor out-of-place with `torch.cat`:
Loads the Torch serialized object at the given URL.
If the object is already present in <cite>model_dir</cite>, it’s deserialized and returned. The filename part of the URL should follow the naming convention `filename-<sha256>.ext` where `<sha256>` is the first eight or more digits of the SHA256 hash of the contents of the file. The hash is used to ensure unique names and to verify the contents of the file.
If the object is already present in `model_dir`, it’s deserialized and returned. The filename part of the URL should follow the naming convention `filename-<sha256>.ext` where `<sha256>` is the first eight or more digits of the SHA256 hash of the contents of the file. The hash is used to ensure unique names and to verify the contents of the file.
The default value of <cite>model_dir</cite> is `$TORCH_HOME/models` where `$TORCH_HOME` defaults to `~/.torch`. The default directory can be overridden with the `$TORCH_MODEL_ZOO` environment variable.
The default value of `model_dir` is `$TORCH_HOME/models` where `$TORCH_HOME` defaults to `~/.torch`. The default directory can be overridden with the `$TORCH_MODEL_ZOO` environment variable.
***nonlinearity** – the non-linear function (`nn.functional` name)
***param** – optional parameter for the non-linear function
|
| --- | --- |
Examples
```py
>>>gain=nn.init.calculate_gain('leaky_relu')
```
```py
torch.nn.init.uniform_(tensor,a=0,b=1)
```
Fills the input Tensor with values drawn from the uniform distribution ).
| Parameters: |
***tensor** – an n-dimensional `torch.Tensor`
***a** – the lower bound of the uniform distribution
***b** – the upper bound of the uniform distribution
|
| --- | --- |
Examples
```py
>>>w=torch.empty(3,5)
>>>nn.init.uniform_(w)
```
```py
torch.nn.init.normal_(tensor,mean=0,std=1)
```
Fills the input Tensor with values drawn from the normal distribution 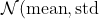).
| Parameters: |
***tensor** – an n-dimensional `torch.Tensor`
***mean** – the mean of the normal distribution
***std** – the standard deviation of the normal distribution
|
| --- | --- |
Examples
```py
>>>w=torch.empty(3,5)
>>>nn.init.normal_(w)
```
```py
torch.nn.init.constant_(tensor,val)
```
Fills the input Tensor with the value 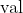.
| Parameters: |
***tensor** – an n-dimensional `torch.Tensor`
***val** – the value to fill the tensor with
|
| --- | --- |
Examples
```py
>>>w=torch.empty(3,5)
>>>nn.init.constant_(w,0.3)
```
```py
torch.nn.init.eye_(tensor)
```
Fills the 2-dimensional input `Tensor` with the identity matrix. Preserves the identity of the inputs in `Linear` layers, where as many inputs are preserved as possible.
| Parameters: | **tensor** – a 2-dimensional `torch.Tensor` |
| --- | --- |
Examples
```py
>>>w=torch.empty(3,5)
>>>nn.init.eye_(w)
```
```py
torch.nn.init.dirac_(tensor)
```
Fills the {3, 4, 5}-dimensional input `Tensor` with the Dirac delta function. Preserves the identity of the inputs in `Convolutional` layers, where as many input channels are preserved as possible.
Fills the input `Tensor` with values according to the method described in “Understanding the difficulty of training deep feedforward neural networks” - Glorot, X. & Bengio, Y. (2010), using a uniform distribution. The resulting tensor will have values sampled from ) where
Fills the input `Tensor` with values according to the method described in “Understanding the difficulty of training deep feedforward neural networks” - Glorot, X. & Bengio, Y. (2010), using a normal distribution. The resulting tensor will have values sampled from ) where
Fills the input `Tensor` with values according to the method described in “Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification” - He, K. et al. (2015), using a uniform distribution. The resulting tensor will have values sampled from ) where
***a** – the negative slope of the rectifier used after this layer (0 for ReLU by default)
***mode** – either ‘fan_in’ (default) or ‘fan_out’. Choosing `fan_in` preserves the magnitude of the variance of the weights in the forward pass. Choosing `fan_out` preserves the magnitudes in the backwards pass.
***nonlinearity** – the non-linear function (`nn.functional` name), recommended to use only with ‘relu’ or ‘leaky_relu’ (default).
Fills the input `Tensor` with values according to the method described in “Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification” - He, K. et al. (2015), using a normal distribution. The resulting tensor will have values sampled from ) where
***a** – the negative slope of the rectifier used after this layer (0 for ReLU by default)
***mode** – either ‘fan_in’ (default) or ‘fan_out’. Choosing `fan_in` preserves the magnitude of the variance of the weights in the forward pass. Choosing `fan_out` preserves the magnitudes in the backwards pass.
***nonlinearity** – the non-linear function (`nn.functional` name), recommended to use only with ‘relu’ or ‘leaky_relu’ (default).
Fills the input `Tensor` with a (semi) orthogonal matrix, as described in “Exact solutions to the nonlinear dynamics of learning in deep linear neural networks” - Saxe, A. et al. (2013). The input tensor must have at least 2 dimensions, and for tensors with more than 2 dimensions the trailing dimensions are flattened.
| Parameters: |
***tensor** – an n-dimensional `torch.Tensor`, where 
***gain** – optional scaling factor
|
| --- | --- |
Examples
```py
>>>w=torch.empty(3,5)
>>>nn.init.orthogonal_(w)
```
```py
torch.nn.init.sparse_(tensor,sparsity,std=0.01)
```
Fills the 2D input `Tensor` as a sparse matrix, where the non-zero elements will be drawn from the normal distribution 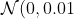), as described in “Deep learning via Hessian-free optimization” - Martens, J. (2010).
| Parameters: |
***tensor** – an n-dimensional `torch.Tensor`
***sparsity** – The fraction of elements in each column to be set to zero
***std** – the standard deviation of the normal distribution used to generate the non-zero values
Thanks to PyTorch’s ability to calculate gradients automatically, we can use any standard Python function (or callable object) as a model! So let’s just write a plain matrix multiplication and broadcasted addition to create a simple linear model. We also need an activation function, so we’ll write <cite>log_softmax</cite> and use it. Remember: although PyTorch provides lots of pre-written loss functions, activation functions, and so forth, you can easily write your own using plain python. PyTorch will even create fast GPU or vectorized CPU code for your function automatically.
Thanks to PyTorch’s ability to calculate gradients automatically, we can use any standard Python function (or callable object) as a model! So let’s just write a plain matrix multiplication and broadcasted addition to create a simple linear model. We also need an activation function, so we’ll write `log_softmax` and use it. Remember: although PyTorch provides lots of pre-written loss functions, activation functions, and so forth, you can easily write your own using plain python. PyTorch will even create fast GPU or vectorized CPU code for your function automatically.
```py
deflog_softmax(x):
...
...
@@ -775,7 +775,7 @@ Out:
`torch.nn` has another handy class we can use to simply our code: [Sequential](https://pytorch.org/docs/stable/nn.html#torch.nn.Sequential) . A `Sequential` object runs each of the modules contained within it, in a sequential manner. This is a simpler way of writing our neural network.
To take advantage of this, we need to be able to easily define a **custom layer** from a given function. For instance, PyTorch doesn’t have a <cite>view</cite> layer, and we need to create one for our network. `Lambda` will create a layer that we can then use when defining a network with `Sequential`.
To take advantage of this, we need to be able to easily define a **custom layer** from a given function. For instance, PyTorch doesn’t have a `view` layer, and we need to create one for our network. `Lambda` will create a layer that we can then use when defining a network with `Sequential`.
```py
classLambda(nn.Module):
...
...
@@ -948,7 +948,7 @@ Out:
## Closing thoughts
We now have a general data pipeline and training loop which you can use for training many types of models using Pytorch. To see how simple training a model can now be, take a look at the <cite>mnist_sample</cite> sample notebook.
We now have a general data pipeline and training loop which you can use for training many types of models using Pytorch. To see how simple training a model can now be, take a look at the `mnist_sample` sample notebook.
Of course, there are many things you’ll want to add, such as data augmentation, hyperparameter tuning, monitoring training, transfer learning, and so forth. These features are available in the fastai library, which has been developed using the same design approach shown in this tutorial, providing a natural next step for practitioners looking to take their models further.
...
...
@@ -956,7 +956,7 @@ We promised at the start of this tutorial we’d explain through example each of
> * **torch.nn**
> * `Module`: creates a callable which behaves like a function, but can also contain state(such as neural net layer weights). It knows what `Parameter` (s) it contains and can zero all their gradients, loop through them for weight updates, etc.
> * `Parameter`: a wrapper for a tensor that tells a `Module` that it has weights that need updating during backprop. Only tensors with the <cite>requires_grad</cite> attribute set are updated
> * `Parameter`: a wrapper for a tensor that tells a `Module` that it has weights that need updating during backprop. Only tensors with the `requires_grad` attribute set are updated
> * `functional`: a module(usually imported into the `F` namespace by convention) which contains activation functions, loss functions, etc, as well as non-stateful versions of layers such as convolutional and linear layers.
> * `torch.optim`: Contains optimizers such as `SGD`, which update the weights of `Parameter` during the backward step
> * `Dataset`: An abstract interface of objects with a `__len__` and a `__getitem__`, including classes provided with Pytorch such as `TensorDataset`
@@ -98,7 +98,7 @@ Note that the introduction of broadcasting can cause backwards incompatible chan
```
would previously produce a Tensor with size: torch.Size([4,1]), but now produces a Tensor with size: torch.Size([4,4]). In order to help identify cases in your code where backwards incompatibilities introduced by broadcasting may exist, you may set <cite>torch.utils.backcompat.broadcast_warning.enabled</cite> to <cite>True</cite>, which will generate a python warning in such cases.
would previously produce a Tensor with size: torch.Size([4,1]), but now produces a Tensor with size: torch.Size([4,4]). In order to help identify cases in your code where backwards incompatibilities introduced by broadcasting may exist, you may set `torch.utils.backcompat.broadcast_warning.enabled` to `True`, which will generate a python warning in such cases.
@@ -53,7 +53,7 @@ By default, GPU operations are asynchronous. When you call a function that uses
In general, the effect of asynchronous computation is invisible to the caller, because (1) each device executes operations in the order they are queued, and (2) PyTorch automatically performs necessary synchronization when copying data between CPU and GPU or between two GPUs. Hence, computation will proceed as if every operation was executed synchronously.
You can force synchronous computation by setting environment variable <cite>CUDA_LAUNCH_BLOCKING=1</cite>. This can be handy when an error occurs on the GPU. (With asynchronous execution, such an error isn’t reported until after the operation is actually executed, so the stack trace does not show where it was requested.)
You can force synchronous computation by setting environment variable `CUDA_LAUNCH_BLOCKING=1`. This can be handy when an error occurs on the GPU. (With asynchronous execution, such an error isn’t reported until after the operation is actually executed, so the stack trace does not show where it was requested.)
As an exception, several functions such as [`to()`](../tensors.html#torch.Tensor.to"torch.Tensor.to") and [`copy_()`](../tensors.html#torch.Tensor.copy_"torch.Tensor.copy_") admit an explicit `non_blocking` argument, which lets the caller bypass synchronization when it is unnecessary. Another exception is CUDA streams, explained below.
Here, `total_loss` is accumulating history across your training loop, since `loss` is a differentiable variable with autograd history. You can fix this by writing <cite>total_loss += float(loss)</cite> instead.
Here, `total_loss` is accumulating history across your training loop, since `loss` is a differentiable variable with autograd history. You can fix this by writing `total_loss += float(loss)` instead.
Other instances of this problem: [1](https://discuss.pytorch.org/t/resolved-gpu-out-of-memory-error-with-batch-size-1/3719).
To run the exported script with [caffe2](https://caffe2.ai/), you will need to install <cite>caffe2</cite>: If you don’t have one already, Please [follow the install instructions](https://caffe2.ai/docs/getting-started.html).
To run the exported script with [caffe2](https://caffe2.ai/), you will need to install `caffe2`: If you don’t have one already, Please [follow the install instructions](https://caffe2.ai/docs/getting-started.html).
Once these are installed, you can use the backend for Caffe2:
@@ -14,7 +14,7 @@ To construct an [`Optimizer`](#torch.optim.Optimizer "torch.optim.Optimizer") yo
Note
If you need to move a model to GPU via <cite>.cuda()</cite>, please do so before constructing optimizers for it. Parameters of a model after <cite>.cuda()</cite> will be different objects with those before the call.
If you need to move a model to GPU via `.cuda()`, please do so before constructing optimizers for it. Parameters of a model after `.cuda()` will be different objects with those before the call.
In general, you should make sure that optimized parameters live in consistent locations when optimizers are constructed and used.
...
...
@@ -108,7 +108,7 @@ Parameters need to be specified as collections that have a deterministic orderin
add_param_group(param_group)
```
Add a param group to the [`Optimizer`](#torch.optim.Optimizer"torch.optim.Optimizer") s <cite>param_groups</cite>.
Add a param group to the [`Optimizer`](#torch.optim.Optimizer"torch.optim.Optimizer") s `param_groups`.
This can be useful when fine tuning a pre-trained network as frozen layers can be made trainable and added to the [`Optimizer`](#torch.optim.Optimizer"torch.optim.Optimizer") as training progresses.
...
...
@@ -637,12 +637,12 @@ Reduce learning rate when a metric has stopped improving. Models often benefit f
***mode** ([_str_](https://docs.python.org/3/library/stdtypes.html#str"(in Python v3.7)")) – One of <cite>min</cite>, <cite>max</cite>. In <cite>min</cite> mode, lr will be reduced when the quantity monitored has stopped decreasing; in <cite>max</cite> mode it will be reduced when the quantity monitored has stopped increasing. Default: ‘min’.
***mode** ([_str_](https://docs.python.org/3/library/stdtypes.html#str"(in Python v3.7)")) – One of `min`, `max`. In `min` mode, lr will be reduced when the quantity monitored has stopped decreasing; in `max` mode it will be reduced when the quantity monitored has stopped increasing. Default: ‘min’.
***factor** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")) – Factor by which the learning rate will be reduced. new_lr = lr * factor. Default: 0.1.
***patience** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")) – Number of epochs with no improvement after which learning rate will be reduced. For example, if <cite>patience = 2</cite>, then we will ignore the first 2 epochs with no improvement, and will only decrease the LR after the 3rd epoch if the loss still hasn’t improved then. Default: 10.
***patience** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")) – Number of epochs with no improvement after which learning rate will be reduced. For example, if `patience = 2`, then we will ignore the first 2 epochs with no improvement, and will only decrease the LR after the 3rd epoch if the loss still hasn’t improved then. Default: 10.
***verbose** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")) – If `True`, prints a message to stdout for each update. Default: `False`.
***threshold** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")) – Threshold for measuring the new optimum, to only focus on significant changes. Default: 1e-4.
***threshold_mode** ([_str_](https://docs.python.org/3/library/stdtypes.html#str"(in Python v3.7)")) – One of <cite>rel</cite>, <cite>abs</cite>. In <cite>rel</cite> mode, dynamic_threshold = best * ( 1 + threshold ) in ‘max’ mode or best * ( 1 - threshold ) in <cite>min</cite> mode. In <cite>abs</cite> mode, dynamic_threshold = best + threshold in <cite>max</cite> mode or best - threshold in <cite>min</cite> mode. Default: ‘rel’.
***threshold_mode** ([_str_](https://docs.python.org/3/library/stdtypes.html#str"(in Python v3.7)")) – One of `rel`, `abs`. In `rel` mode, dynamic_threshold = best * ( 1 + threshold ) in ‘max’ mode or best * ( 1 - threshold ) in `min` mode. In `abs` mode, dynamic_threshold = best + threshold in `max` mode or best - threshold in `min` mode. Default: ‘rel’.
***cooldown** ([_int_](https://docs.python.org/3/library/functions.html#int"(in Python v3.7)")) – Number of epochs to wait before resuming normal operation after lr has been reduced. Default: 0.
***min_lr** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")_or_[_list_](https://docs.python.org/3/library/stdtypes.html#list"(in Python v3.7)")) – A scalar or a list of scalars. A lower bound on the learning rate of all param groups or each group respectively. Default: 0.
***eps** ([_float_](https://docs.python.org/3/library/functions.html#float"(in Python v3.7)")) – Minimal decay applied to lr. If the difference between new and old lr is smaller than eps, the update is ignored. Default: 1e-8.
@@ -22,7 +22,7 @@ Strictly speaking, we will present the state as the difference between the curre
**Packages**
First, let’s import needed packages. Firstly, we need [gym](https://gym.openai.com/docs) for the environment (Install using <cite>pip install gym</cite>). We’ll also use the following from PyTorch:
First, let’s import needed packages. Firstly, we need [gym](https://gym.openai.com/docs) for the environment (Install using `pip install gym`). We’ll also use the following from PyTorch:
* neural networks (`torch.nn`)
* optimization (`torch.optim`)
...
...
@@ -342,7 +342,7 @@ def optimize_model():
Below, you can find the main training loop. At the beginning we reset the environment and initialize the `state` Tensor. Then, we sample an action, execute it, observe the next screen and the reward (always 1), and optimize our model once. When the episode ends (our model fails), we restart the loop.
Below, <cite>num_episodes</cite> is set small. You should download the notebook and run lot more epsiodes, such as 300+ for meaningful duration improvements.
Below, `num_episodes` is set small. You should download the notebook and run lot more epsiodes, such as 300+ for meaningful duration improvements.
This function does exact same thing as [`torch.addmm()`](torch.html#torch.addmm"torch.addmm") in the forward, except that it supports backward for sparse matrix `mat1`. `mat1` need to have <cite>sparse_dim = 2</cite>. Note that the gradients of `mat1` is a coalesced sparse tensor.
This function does exact same thing as [`torch.addmm()`](torch.html#torch.addmm"torch.addmm") in the forward, except that it supports backward for sparse matrix `mat1`. `mat1` need to have `sparse_dim = 2`. Note that the gradients of `mat1` is a coalesced sparse tensor.
| Parameters: |
...
...
@@ -228,7 +228,7 @@ This function does exact same thing as [`torch.addmm()`](torch.html#torch.addmm
torch.sparse.mm(mat1,mat2)
```
Performs a matrix multiplication of the sparse matrix `mat1` and dense matrix `mat2`. Similar to [`torch.mm()`](torch.html#torch.mm"torch.mm"), If `mat1` is a  tensor, `mat2` is a  tensor, out will be a  dense tensor. `mat1` need to have <cite>sparse_dim = 2</cite>. This function also supports backward for both matrices. Note that the gradients of `mat1` is a coalesced sparse tensor.
Performs a matrix multiplication of the sparse matrix `mat1` and dense matrix `mat2`. Similar to [`torch.mm()`](torch.html#torch.mm"torch.mm"), If `mat1` is a  tensor, `mat2` is a  tensor, out will be a  dense tensor. `mat1` need to have `sparse_dim = 2`. This function also supports backward for both matrices. Note that the gradients of `mat1` is a coalesced sparse tensor.
Returns the sum of each row of SparseTensor `input` in the given dimensions `dim`. If :attr::<cite>dim</cite> is a list of dimensions, reduce over all of them. When sum over all `sparse_dim`, this method returns a Tensor instead of SparseTensor.
Returns the sum of each row of SparseTensor `input` in the given dimensions `dim`. If :attr::`dim` is a list of dimensions, reduce over all of them. When sum over all `sparse_dim`, this method returns a Tensor instead of SparseTensor.
All summed `dim` are squeezed (see [`torch.squeeze()`](torch.html#torch.squeeze"torch.squeeze")), resulting an output tensor having :attr::<cite>dim</cite> fewer dimensions than `input`.
All summed `dim` are squeezed (see [`torch.squeeze()`](torch.html#torch.squeeze"torch.squeeze")), resulting an output tensor having :attr::`dim` fewer dimensions than `input`.
During backward, only gradients at `nnz` locations of `input` will propagate back. Note that the gradients of `input` is coalesced.
If <cite>shared</cite> is <cite>True</cite>, then memory is shared between all processes. All changes are written to the file. If <cite>shared</cite> is <cite>False</cite>, then the changes on the storage do not affect the file.
If `shared` is `True`, then memory is shared between all processes. All changes are written to the file. If `shared` is `False`, then the changes on the storage do not affect the file.
<cite>size</cite> is the number of elements in the storage. If <cite>shared</cite> is <cite>False</cite>, then the file must contain at least <cite>size * sizeof(Type)</cite> bytes (<cite>Type</cite> is the type of storage). If <cite>shared</cite> is <cite>True</cite> the file will be created if needed.
`size` is the number of elements in the storage. If `shared` is `False`, then the file must contain at least `size * sizeof(Type)` bytes (`Type` is the type of storage). If `shared` is `True` the file will be created if needed.
| Parameters: |
...
...
@@ -178,7 +178,7 @@ Returns a list containing the elements of this storage
type(dtype=None,non_blocking=False,**kwargs)
```
Returns the type if <cite>dtype</cite> is not provided, else casts this object to the specified type.
Returns the type if `dtype` is not provided, else casts this object to the specified type.
If this is already of the correct type, no copy is performed and the original object is returned.
When data is a tensor <cite>x</cite>, [`new_tensor()`](#torch.Tensor.new_tensor"torch.Tensor.new_tensor") reads out ‘the data’ from whatever it is passed, and constructs a leaf variable. Therefore `tensor.new_tensor(x)` is equivalent to `x.clone().detach()` and `tensor.new_tensor(x, requires_grad=True)` is equivalent to `x.clone().detach().requires_grad_(True)`. The equivalents using `clone()` and `detach()` are recommended.
When data is a tensor `x`, [`new_tensor()`](#torch.Tensor.new_tensor"torch.Tensor.new_tensor") reads out ‘the data’ from whatever it is passed, and constructs a leaf variable. Therefore `tensor.new_tensor(x)` is equivalent to `x.clone().detach()` and `tensor.new_tensor(x, requires_grad=True)` is equivalent to `x.clone().detach().requires_grad_(True)`. The equivalents using `clone()` and `detach()` are recommended.
| Parameters: |
...
...
@@ -571,7 +571,7 @@ Returns a copy of the `self` tensor. The copy has the same size and data type as
Note
Unlike <cite>copy_()</cite>, this function is recorded in the computation graph. Gradients propagating to the cloned tensor will propagate to the original tensor.
Unlike `copy_()`, this function is recorded in the computation graph. Gradients propagating to the cloned tensor will propagate to the original tensor.
```py
contiguous()→Tensor
...
...
@@ -1129,8 +1129,8 @@ If `accumulate` is `True`, the elements in [`tensor`](torch.html#torch.tensor "t
| Parameters: |
***indices** (_tuple of LongTensor_) – tensors used to index into <cite>self</cite>.
***value** ([_Tensor_](#torch.Tensor"torch.Tensor")) – tensor of same dtype as <cite>self</cite>.
***indices** (_tuple of LongTensor_) – tensors used to index into `self`.
***value** ([_Tensor_](#torch.Tensor"torch.Tensor")) – tensor of same dtype as `self`.
***accumulate** ([_bool_](https://docs.python.org/3/library/functions.html#bool"(in Python v3.7)")) – whether to accumulate into self
|
...
...
@@ -1510,7 +1510,7 @@ See [`torch.nonzero()`](torch.html#torch.nonzero "torch.nonzero")
norm(p='fro',dim=None,keepdim=False)
```
See :func: <cite>torch.norm</cite>
See :func: `torch.norm`
```py
normal_(mean=0,std=1,*,generator=None)→Tensor
...
...
@@ -1652,7 +1652,7 @@ See [`torch.qr()`](torch.html#torch.qr "torch.qr")
random_(from=0,to=None,*,generator=None)→Tensor
```
Fills `self` tensor with numbers sampled from the discrete uniform distribution over `[from, to - 1]`. If not specified, the values are usually only bounded by `self` tensor’s data type. However, for floating point types, if unspecified, range will be `[0, 2^mantissa]` to ensure that every value is representable. For example, <cite>torch.tensor(1, dtype=torch.double).random_()</cite> will be uniform in `[0, 2^53]`.
Fills `self` tensor with numbers sampled from the discrete uniform distribution over `[from, to - 1]`. If not specified, the values are usually only bounded by `self` tensor’s data type. However, for floating point types, if unspecified, range will be `[0, 2^mantissa]` to ensure that every value is representable. For example, `torch.tensor(1, dtype=torch.double).random_()` will be uniform in `[0, 2^53]`.
```py
reciprocal()→Tensor
...
...
@@ -2420,7 +2420,7 @@ In-place version of [`trunc()`](#torch.Tensor.trunc "torch.Tensor.trunc")
Returns the type if <cite>dtype</cite> is not provided, else casts this object to the specified type.
Returns the type if `dtype` is not provided, else casts this object to the specified type.
If this is already of the correct type, no copy is performed and the original object is returned.
...
...
@@ -2460,7 +2460,7 @@ Returns a tensor which contains all slices of size [`size`](#torch.Tensor.size "
Step between two slices is given by `step`.
If <cite>sizedim</cite> is the size of dimension dim for `self`, the size of dimension [`dim`](#torch.Tensor.dim"torch.Tensor.dim") in the returned tensor will be <cite>(sizedim - size) / step + 1</cite>.
If `sizedim` is the size of dimension dim for `self`, the size of dimension [`dim`](#torch.Tensor.dim"torch.Tensor.dim") in the returned tensor will be `(sizedim - size) / step + 1`.
An additional dimension of size size is appended in the returned tensor.
@@ -8,7 +8,7 @@ TorchScript supports a large subset of operations provided by the `torch` packag
The following paragraphs give an example of writing a TorchScript custom op to call into [OpenCV](https://www.opencv.org), a computer vision library written in C++. We will discuss how to work with tensors in C++, how to efficiently convert them to third party tensor formats (in this case, OpenCV [``](#id1)Mat``s), how to register your operator with the TorchScript runtime and finally how to compile the operator and use it in Python and C++.
This tutorial assumes you have the _preview release_ of PyTorch 1.0 installed via `pip` or <cite>conda</cite>. See [https://pytorch.org/get-started/locally](https://pytorch.org/get-started/locally) for instructions on grabbing the latest release of PyTorch 1.0\. Alternatively, you can compile PyTorch from source. The documentation in [this file](https://github.com/pytorch/pytorch/blob/master/CONTRIBUTING.md) will assist you with this.
This tutorial assumes you have the _preview release_ of PyTorch 1.0 installed via `pip` or `conda`. See [https://pytorch.org/get-started/locally](https://pytorch.org/get-started/locally) for instructions on grabbing the latest release of PyTorch 1.0\. Alternatively, you can compile PyTorch from source. The documentation in [this file](https://github.com/pytorch/pytorch/blob/master/CONTRIBUTING.md) will assist you with this.
## Implementing the Custom Operator in C++
...
...
@@ -678,7 +678,7 @@ The JIT compilation feature provided by the PyTorch C++ extension toolkit allows
Note
“JIT compilation” here has nothing to do with the JIT compilation taking place in the TorchScript compiler to optimize your program. It simply means that your custom operator C++ code will be compiled in a folder under your system’s <cite>/tmp</cite> directory the first time you import it, as if you had compiled it yourself beforehand.
“JIT compilation” here has nothing to do with the JIT compilation taking place in the TorchScript compiler to optimize your program. It simply means that your custom operator C++ code will be compiled in a folder under your system’s `/tmp` directory the first time you import it, as if you had compiled it yourself beforehand.
This JIT compilation feature comes in two flavors. In the first, you still keep your operator implementation in a separate file (`op.cpp`), and then use `torch.utils.cpp_extension.load()` to compile your extension. Usually, this function will return the Python module exposing your C++ extension. However, since we are not compiling our custom operator into its own Python module, we only want to compile a plain shared library . Fortunately, `torch.utils.cpp_extension.load()` has an argument `is_python_module` which we can set to `False` to indicate that we are only interested in building a shared library and not a Python module. `torch.utils.cpp_extension.load()` will then compile and also load the shared library into the current process, just like `torch.ops.load_library` did before:
[SVHN](http://ufldl.stanford.edu/housenumbers/) Dataset. Note: The SVHN dataset assigns the label <cite>10</cite> to the digit <cite>0</cite>. However, in this Dataset, we assign the label <cite>0</cite> to the digit <cite>0</cite> to be compatible with PyTorch loss functions which expect the class labels to be in the range <cite>[0, C-1]</cite>
[SVHN](http://ufldl.stanford.edu/housenumbers/) Dataset. Note: The SVHN dataset assigns the label `10` to the digit `0`. However, in this Dataset, we assign the label `0` to the digit `0` to be compatible with PyTorch loss functions which expect the class labels to be in the range `[0, C-1]`
Instancing a pre-trained model will download its weights to a cache directory. This directory can be set using the <cite>TORCH_MODEL_ZOO</cite> environment variable. See [`torch.utils.model_zoo.load_url()`](../model_zoo.html#torch.utils.model_zoo.load_url"torch.utils.model_zoo.load_url") for details.
Instancing a pre-trained model will download its weights to a cache directory. This directory can be set using the `TORCH_MODEL_ZOO` environment variable. See [`torch.utils.model_zoo.load_url()`](../model_zoo.html#torch.utils.model_zoo.load_url"torch.utils.model_zoo.load_url") for details.
Some models use modules which have different training and evaluation behavior, such as batch normalization. To switch between these modes, use `model.train()` or `model.eval()` as appropriate. See [`train()`](../nn.html#torch.nn.Module.train"torch.nn.Module.train") or [`eval()`](../nn.html#torch.nn.Module.eval"torch.nn.Module.eval") for details.
The image hue is adjusted by converting the image to HSV and cyclically shifting the intensities in the hue channel (H). The image is then converted back to original image mode.
<cite>hue_factor</cite> is the amount of shift in H channel and must be in the interval <cite>[-0.5, 0.5]</cite>.
`hue_factor` is the amount of shift in H channel and must be in the interval `[-0.5, 0.5]`.
See [https://en.wikipedia.org/wiki/Hue](https://en.wikipedia.org/wiki/Hue) for more details on Hue.
@@ -10,7 +10,7 @@ The numerical properties of a [`torch.dtype`](tensor_attributes.html#torch.torch
classtorch.finfo
```
A [`torch.finfo`](#torch.torch.finfo"torch.torch.finfo") is an object that represents the numerical properties of a floating point [`torch.dtype`](tensor_attributes.html#torch.torch.dtype"torch.torch.dtype"), (i.e. <cite>torch.float32</cite>, <cite>torch.float64</cite>, and <cite>torch.float16</cite>). This is similar to [numpy.finfo](https://docs.scipy.org/doc/numpy/reference/generated/numpy.finfo.html).
A [`torch.finfo`](#torch.torch.finfo"torch.torch.finfo") is an object that represents the numerical properties of a floating point [`torch.dtype`](tensor_attributes.html#torch.torch.dtype"torch.torch.dtype"), (i.e. `torch.float32`, `torch.float64`, and `torch.float16`). This is similar to [numpy.finfo](https://docs.scipy.org/doc/numpy/reference/generated/numpy.finfo.html).
A [`torch.finfo`](#torch.torch.finfo"torch.torch.finfo") provides the following attributes:
...
...
@@ -31,7 +31,7 @@ The constructor of [`torch.finfo`](#torch.torch.finfo "torch.torch.finfo") can b
classtorch.iinfo
```
A [`torch.iinfo`](#torch.torch.iinfo"torch.torch.iinfo") is an object that represents the numerical properties of a integer [`torch.dtype`](tensor_attributes.html#torch.torch.dtype"torch.torch.dtype")(i.e.<cite>torch.uint8</cite>, <cite>torch.int8</cite>, <cite>torch.int16</cite>, <cite>torch.int32</cite>, and <cite>torch.int64</cite>). This is similar to [numpy.iinfo](https://docs.scipy.org/doc/numpy/reference/generated/numpy.iinfo.html).
A [`torch.iinfo`](#torch.torch.iinfo"torch.torch.iinfo") is an object that represents the numerical properties of a integer [`torch.dtype`](tensor_attributes.html#torch.torch.dtype"torch.torch.dtype")(i.e.`torch.uint8`, `torch.int8`, `torch.int16`, `torch.int32`, and `torch.int64`). This is similar to [numpy.iinfo](https://docs.scipy.org/doc/numpy/reference/generated/numpy.iinfo.html).
A [`torch.iinfo`](#torch.torch.iinfo"torch.torch.iinfo") provides the following attributes: