init
上级
Showing
README.md
0 → 100644
{kind=link}
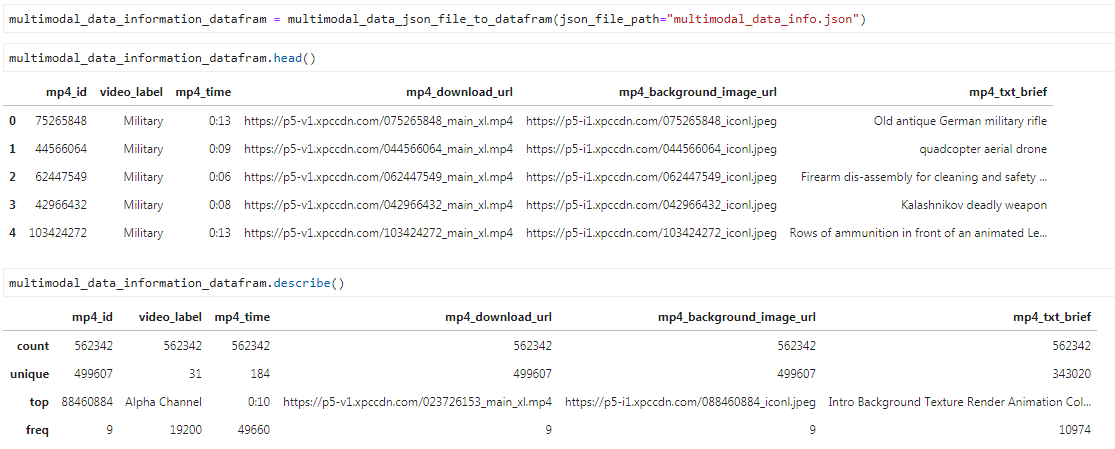
28.3 KB
{kind=link}
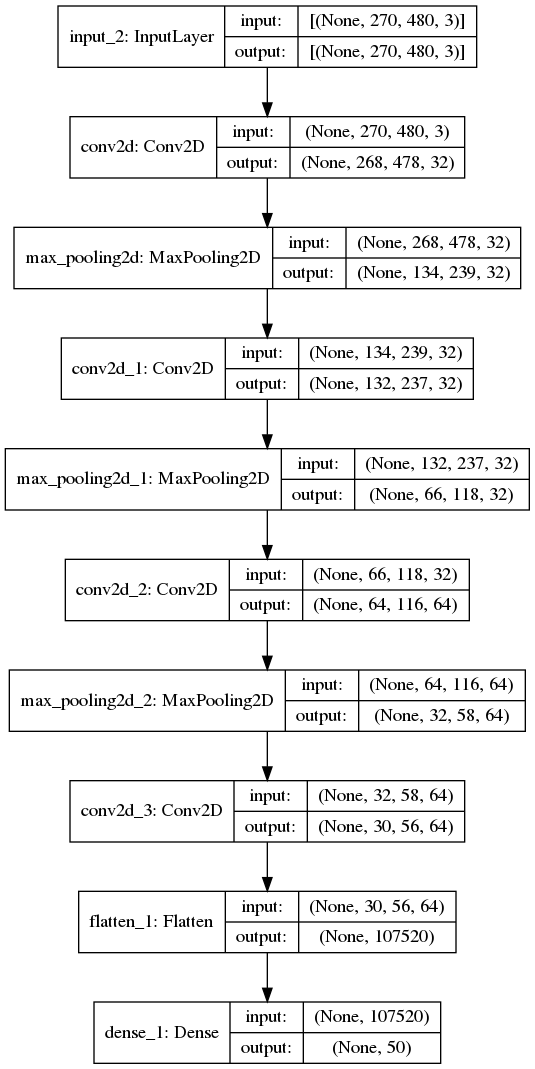
85.8 KB
{kind=link}
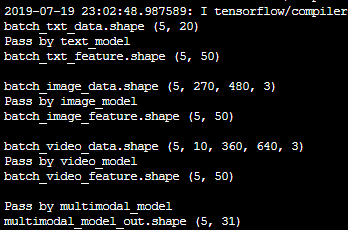
6.1 KB
{kind=link}
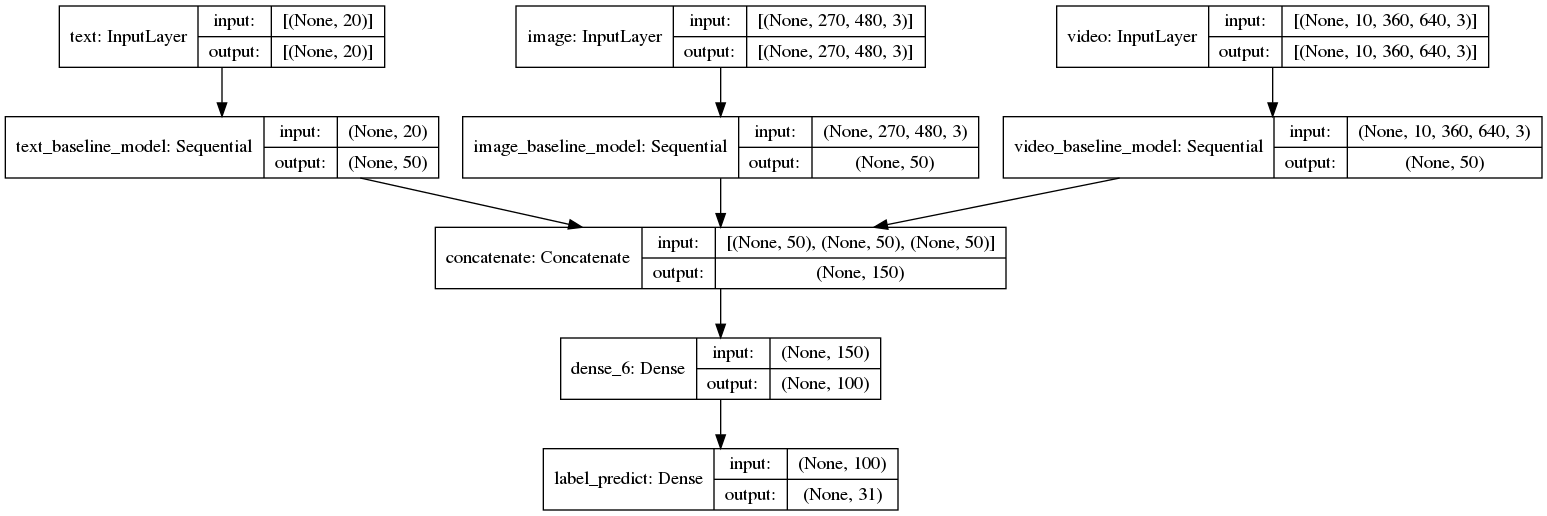
48.2 KB
{kind=link}
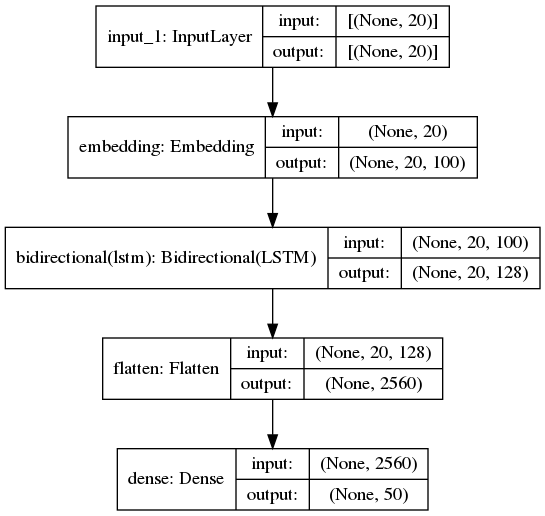
32.5 KB
{kind=link}

171.1 KB
data_download_tools/README.md
0 → 100644
{kind=link}

129.6 KB
此差异已折叠。
{kind=link}
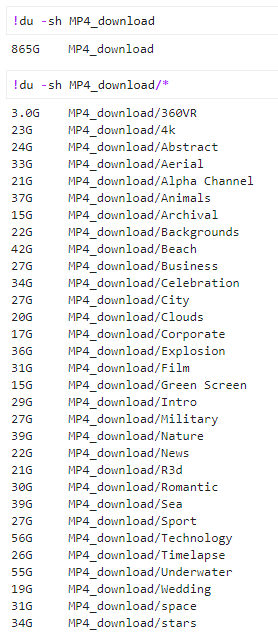
11.9 KB
example_data/99945958.jpeg
0 → 100644
{kind=link}

35.2 KB
example_data/99945958.mp4
0 → 100644
文件已添加
example_data/99945958.txt
0 → 100644
{kind=link}

4.7 KB