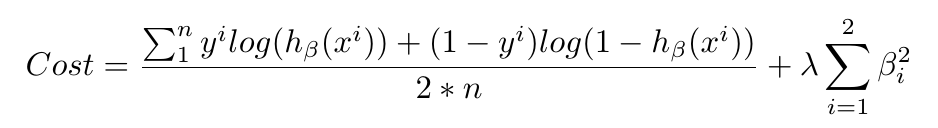Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
OpenDocCN
ml-for-humans-zh
提交
7ae2ade0
M
ml-for-humans-zh
项目概览
OpenDocCN
/
ml-for-humans-zh
通知
1
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
M
ml-for-humans-zh
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
7ae2ade0
编写于
10月 14, 2017
作者:
W
wizardforcel
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
2.2.
上级
c2337710
变更
2
隐藏空白更改
内联
并排
Showing
2 changed file
with
22 addition
and
1 deletion
+22
-1
2.2.md
2.2.md
+22
-1
img/2-2-8.png
img/2-2-8.png
+0
-0
未找到文件。
2.2.md
浏览文件 @
7ae2ade0
...
...
@@ -18,7 +18,7 @@
> 分类的一个很好的例子是,判断贷款申请人是不是骗子。
> 最终,出借人想要知道,它们是否应该贷给借款人,以及它们拥有一些容
差
,用于抵抗申请人的确是骗子的风险。这里,对数几率回归的目标就是计算申请人是骗子的概率(0%~100%)。使用这些概率,我们可以设定一些阈值,我们愿意借给高于它的借款人,对于低于它的借款人,我们拒绝他们的贷款申请,或者标记它们以便后续观察。
> 最终,出借人想要知道,它们是否应该贷给借款人,以及它们拥有一些容
忍度
,用于抵抗申请人的确是骗子的风险。这里,对数几率回归的目标就是计算申请人是骗子的概率(0%~100%)。使用这些概率,我们可以设定一些阈值,我们愿意借给高于它的借款人,对于低于它的借款人,我们拒绝他们的贷款申请,或者标记它们以便后续观察。
虽然对数几率回归通常用于二元分类,其中只存在两个类,要注意,分类可以拥有任意数量的类(例如,为手写数字分配 0~9 的标签,或者使用人脸识别来检测 Fackbook 图片中是哪个朋友)。
...
...
@@ -71,3 +71,24 @@
对率回归模型的输出,就像 S 型曲线,基于
`X`
的值展示了
`P(Y=1)`
。

为了预测
`Y`
标签,是不是垃圾邮件,有没有癌症,是不是骗子,以及其他,你需要(为正的结果)设置一个概率截断值,或者叫阈值(不是)。例如,如果模型认为,邮件是垃圾邮件的概率高于 70%,就将其标为垃圾。否则就不是垃圾。
这个阈值取决于你对假阳性(误报)和假阴性(漏报)的容忍度。如果你在诊断癌症,你对假阴性有极低的容忍度,因为如果病人有极小的几率得癌症,你都需要进一步的测试来确认。所以你需要为正向结果设置一个很低的阈值。
另一方面,在欺诈性贷款申请的例子中,假阳性的容忍度更高,也别是对于小额贷款,因为进一步的审查开销很大,并且小额贷款不值得额外的操作成本,以及对于非欺骗性的申请者来说是个障碍,它们正在等待进一步的处理。
### 对数几率回归的最小损失
就像线性回归的例子那样,我们使用梯度下降来习得使损失最小的
`beta`
参数。
在对率回归中,成本函数是这样的度量,当真实答案是
`0`
时,你有多么经常将其预测为 1,或者反过来。下面是正则化的成本函数,就像我们对线性回归所做的那样。

当你看到像这样的长式子时,不要惊慌。将其拆成小部分,并从概念上思考每个部分都是什么。之后就能理解了。
第一个部分是数据损失,也就是,模型预测值和实际值之间有多少差异。第二个部分就是正则损失,也就是,我们以什么程度,惩罚模型的较大参数,它过于看重特定的特征(要记得,这可以阻止过拟合)。
我们使用低度下降,使损失函数最小,就是像上面这样。我们构建了一个对数几率回归模型,来尽可能准确地预测分类。
img/2-2-8.png
0 → 100644
浏览文件 @
7ae2ade0
16.1 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}