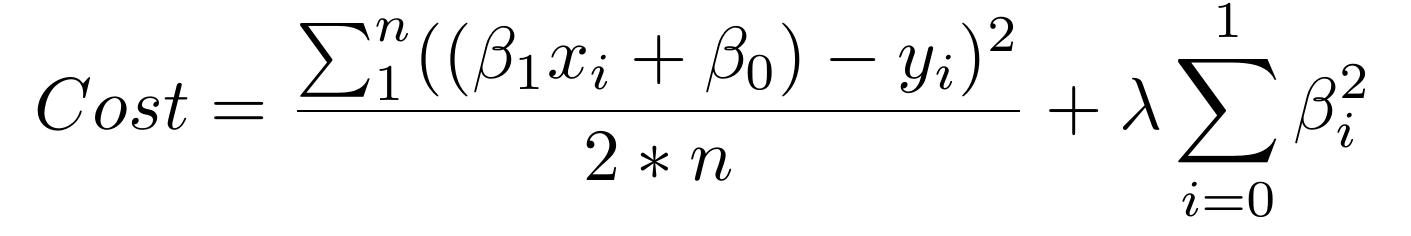Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
OpenDocCN
ml-for-humans-zh
提交
148f5c64
M
ml-for-humans-zh
项目概览
OpenDocCN
/
ml-for-humans-zh
通知
1
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
M
ml-for-humans-zh
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
148f5c64
编写于
10月 13, 2017
作者:
W
wizardforcel
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
2.1
上级
7fcf8d91
变更
2
隐藏空白更改
内联
并排
Showing
2 changed file
with
46 addition
and
0 deletion
+46
-0
2.1.md
2.1.md
+46
-0
img/2-9.png
img/2-9.png
+0
-0
未找到文件。
2.1.md
浏览文件 @
148f5c64
...
...
@@ -188,3 +188,49 @@ Y_train = [80, 91.5, 42, 55, …, 100] # 对应的年收入,单位为千美元
> 来源:Coursera 的机器学习课程,由吴恩达讲授
要记住,我们关心的唯一的事情就是,模型在测试数据上如何表现。你打算在标记邮件之前,预测哪个邮件会标记为垃圾,而不仅仅是构建一个模型,它可以以 100% 准确度,重新分类最开始用于构建自身的邮件。马后炮是 20/20,真正的问题是学到的经验是否在未来有所帮助。
右边的模型对于训练数据是零损失的,因为它完美拟合了每个数据点。但是这个经验不能推广。对于解释不在线上的数据点来说,这是个灾难性的任务。
两种避免过拟合的方法:
1.
使用更多训练数据。你拥有更多,通过从任意单一的训练样本大量学习,就更难过拟合数据。
2.
使用正则化。在损失函数里添加一个惩罚,来构建一个模型,避免为任意一个特征分配过多的解释性权重,或者允许考虑过多特征。

上面的和式的第一部分是正常的损失函数。第二部分就是正则项,为较大的
`β`
系数添加惩罚,它将过大的解释性权重给予任何特定的特征。同时使用这两个元素,成本函数现在平衡了两个优先级:解释训练数据,并防止解释过于特定。
损失函数中,正则项的
`lambda`
系数是个超参数:你的模型的通用设置,可以增加或者减少(也就是调整),以便改进表现。较高的
`lambda`
值会更严厉地惩罚较大的
`β`
参数,它们可能导致过拟合。为了决定
`lambda`
的最佳值,你可以使用叫做交叉验证的方法,它涉及在训练过程中,保留一部分训练数据,之后观察,模型对保留部分的解释有多好。我们会深入了解它。
## 这就完成了
这里是我们在这一节中涉及到的东西:
+
监督机器学习如何让计算机,能够从带标签的训练数据中学习,而不需要显式编程。
+
监督学习的任务:回归和分类。
+
线性回归,简单而实用的参数化算法。
+
使用梯度下降习得参数。
+
过拟合和正则化
下一节“2.2 节:监督机器学习 II”中,我们会讨论分类的两个基本方法:对数几率回归(LR)和支持向量机(SVM)。
## 练习材料和扩展阅读
### 2.1a 线性回归
对于线性回归的更彻底的讲授,阅读
[
《An Introduction to Statistical Learning》
](
https://www-bcf.usc.edu/~gareth/ISL/index.html
)
的 1~3 章。这本书可以免费在线阅读,并且是用于使用配套练习理解机器学习概念的优秀资源。
对于更多练习:
+
玩转
[
波士顿房价数据集
](
https://www.cs.toronto.edu/~delve/data/boston/bostonDetail.html
)
。你可以使用带有漂亮 GUI 的软件,例如 Minitab 和 Excel,或者使用 Python 或者 R 用笨办法来完成它。
+
亲自尝试 Kaggle 挑战,例如房价预测,并在自己尝试之后,看看其他人如何解决问题。
### 2.1b 实现梯度下降
为了在 Python 中实际实现梯度下降,查阅
[
这篇教程
](
https://spin.atomicobject.com/2014/06/24/gradient-descent-linear-regression/
)
。然后,
[
这里
](
https://eli.thegreenplace.net/2016/understanding-gradient-descent/
)
是相同概念的更加数学化的严格描述。
在实战中,你很少需要从零开始实现梯度下降,但是理解它背后的工作原理,会让你更有效地使用它,并且在出现问题时理解其原因。
img/2-9.png
0 → 100644
浏览文件 @
148f5c64
32.2 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}