c d tex
Showing
{kind=link}
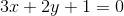
467 字节
{kind=link}
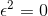
234 字节
{kind=link}

282 字节
{kind=link}
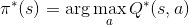
875 字节
{kind=link}

288 字节
{kind=link}

635 字节
{kind=link}
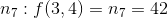
609 字节
{kind=link}
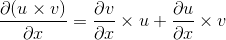
1.0 KB
{kind=link}
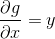
422 字节
{kind=link}
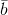
139 字节
{kind=link}

197 字节
{kind=link}
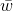
145 字节
{kind=link}
356 字节
{kind=link}
810 字节
{kind=link}
552 字节
{kind=link}
496 字节
{kind=link}
330 字节
{kind=link}
379 字节
{kind=link}
331 字节
{kind=link}
906 字节
{kind=link}
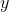
137 字节
{kind=link}
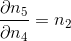
498 字节
{kind=link}
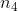
160 字节
{kind=link}
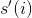
244 字节
{kind=link}
162 字节
{kind=link}
525 字节
{kind=link}
244 字节
{kind=link}
769 字节
{kind=link}
649 字节
{kind=link}
611 字节
{kind=link}
352 字节
{kind=link}
306 字节
{kind=link}
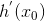
313 字节
{kind=link}
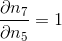
452 字节
{kind=link}
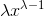
246 字节
{kind=link}
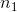
156 字节
{kind=link}
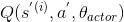
636 字节
{kind=link}
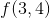
321 字节
{kind=link}
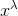
160 字节
{kind=link}
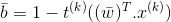
748 字节
{kind=link}
726 字节
{kind=link}
861 字节
{kind=link}
197 字节
{kind=link}
406 字节
{kind=link}
390 字节
{kind=link}
135 字节
{kind=link}

245 字节
{kind=link}
623 字节
{kind=link}
2.5 KB
{kind=link}
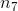
165 字节
{kind=link}
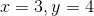
344 字节
{kind=link}
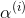
224 字节
{kind=link}
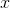
124 字节
{kind=link}
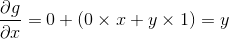
944 字节
{kind=link}
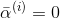
312 字节
{kind=link}
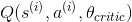
685 字节
{kind=link}
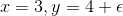
406 字节
{kind=link}
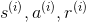
458 字节
{kind=link}
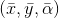
358 字节
{kind=link}

276 字节
{kind=link}
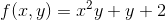
635 字节
{kind=link}
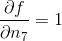
435 字节
{kind=link}
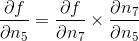
897 字节
{kind=link}
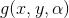
400 字节
{kind=link}

133 字节
{kind=link}
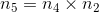
364 字节
{kind=link}

171 字节
{kind=link}
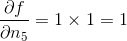
572 字节
{kind=link}
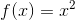
363 字节
{kind=link}
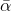
139 字节
{kind=link}
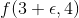
400 字节
{kind=link}
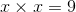
281 字节
{kind=link}
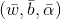
367 字节
{kind=link}

813 字节
{kind=link}
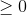
192 字节
{kind=link}
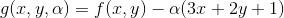
1.0 KB
{kind=link}
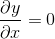
422 字节
{kind=link}
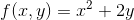
559 字节
{kind=link}
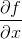
313 字节
{kind=link}
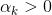
274 字节
{kind=link}
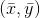
281 字节