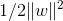Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
OpenDocCN
hands-on-ml-zh
提交
6e6e8e21
H
hands-on-ml-zh
项目概览
OpenDocCN
/
hands-on-ml-zh
通知
13
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
H
hands-on-ml-zh
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
6e6e8e21
编写于
5月 24, 2018
作者:
W
wizardforcel
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
tex
上级
67c22ba9
变更
4
隐藏空白更改
内联
并排
Showing
4 changed file
with
4 addition
and
4 deletion
+4
-4
docs/5.支持向量机.md
docs/5.支持向量机.md
+4
-4
images/tex-03549015bd48d379883d926e6857b448.gif
images/tex-03549015bd48d379883d926e6857b448.gif
+0
-0
images/tex-8b908429a5b5ee2e519f8caa16f82ee1.gif
images/tex-8b908429a5b5ee2e519f8caa16f82ee1.gif
+0
-0
images/tex-98c822c91ab5af02c383eb03fa5b5446.gif
images/tex-98c822c91ab5af02c383eb03fa5b5446.gif
+0
-0
未找到文件。
docs/5.支持向量机.md
浏览文件 @
6e6e8e21
...
...
@@ -126,7 +126,7 @@ poly_kernel_svm_clf.fit(X, y)
公式 5-1 RBF


它是个从 0 到 1 的钟型函数,值为 0 的离地标很远,值为 1 的在地标上。现在我们准备计算新特征。例如,我们看一下样本
`x1=-1`
:它距离第一个地标距离是 1,距离第二个地标是 2。因此它的新特征为
`x2=exp((-0.3 × 1)^2)≈0.74`
和
`x3=exp((-0.3 × 2)^2)≈0.30`
。图 5-8 右边的图显示了特征转换后的数据集(删除了原始特征),正如你看到的,它现在是线性可分了。
...
...
@@ -226,11 +226,11 @@ svm_poly_reg.fit(X, y)
### 训练目标
看下决策函数的斜率:它等于权重向量的范数 !
[
\
\\|w\\\|
](
../images/tex-8c4e86c0589861da28f13331294e04ef
.gif
)
。如果我们把这个斜率除于 2,决策函数等于 ±1 的点将会离决策边界原来的两倍大。换句话,即斜率除于 2,那么间隔将增加两倍。在图 5-13 中,2D 形式比较容易可视化。权重向量
`w`
越小,间隔越大。
看下决策函数的斜率:它等于权重向量的范数 !
[
\
|w\|
](
../images/tex-03549015bd48d379883d926e6857b448
.gif
)
。如果我们把这个斜率除于 2,决策函数等于 ±1 的点将会离决策边界原来的两倍大。换句话,即斜率除于 2,那么间隔将增加两倍。在图 5-13 中,2D 形式比较容易可视化。权重向量
`w`
越小,间隔越大。

所以我们的目标是最小化 !
[
\
\\|w\\\|
](
../images/tex-8c4e86c0589861da28f13331294e04ef
.gif
)
,从而获得大的间隔。然而,如果我们想要避免间隔违规(硬间隔),对于正的训练样本,我们需要决策函数大于 1,对于负训练样本,小于 -1。若我们对负样本(即 !
[
y^{(i)} = 0
](
../images/tex-9694b9470a2a80b31bcc6584edf2bf07.gif
)
)定义 !
[
t^{(i)}=-1
](
../images/tex-e9e1ea47451dc98fefd42615328d631b.gif
)
,对正样本(即 !
[
y^{(i)} = 1
](
../images/tex-acd7569716837ec3ce2aa6e0a5ddd513.gif
)
)定义 !
[
t^{(i)}=1
](
../images/tex-c19c0fd70a5476c3ffd036cdc186cd3d.gif
)
,那么我们可以对所有的样本表示为 !
[
t^{(i)} (w^T x^{(i)} + b) \ge 1
](
../images/tex-90df7f0e34b9b6efed412669d8ab1581.gif
)
。
所以我们的目标是最小化 !
[
\
|w\|
](
../images/tex-03549015bd48d379883d926e6857b448
.gif
)
,从而获得大的间隔。然而,如果我们想要避免间隔违规(硬间隔),对于正的训练样本,我们需要决策函数大于 1,对于负训练样本,小于 -1。若我们对负样本(即 !
[
y^{(i)} = 0
](
../images/tex-9694b9470a2a80b31bcc6584edf2bf07.gif
)
)定义 !
[
t^{(i)}=-1
](
../images/tex-e9e1ea47451dc98fefd42615328d631b.gif
)
,对正样本(即 !
[
y^{(i)} = 1
](
../images/tex-acd7569716837ec3ce2aa6e0a5ddd513.gif
)
)定义 !
[
t^{(i)}=1
](
../images/tex-c19c0fd70a5476c3ffd036cdc186cd3d.gif
)
,那么我们可以对所有的样本表示为 !
[
t^{(i)} (w^T x^{(i)} + b) \ge 1
](
../images/tex-90df7f0e34b9b6efed412669d8ab1581.gif
)
。
因此,我们可以将硬间隔线性 SVM 分类器表示为公式 5-3 中的约束优化问题
...
...
@@ -238,7 +238,7 @@ svm_poly_reg.fit(X, y)
> 注
>
>  等于 ,我们最小化 ,而不是最小化 。这会给我们相同的结果(因为最小化`w`值和`b`值,也是最小化该值一半的平方),但是  有很好又简单的导数(只有`w`), 在`w=0`处是不可微的。优化算法在可微函数表现得更好。
>  等于 ,我们最小化 ,而不是最小化 。这会给我们相同的结果(因为最小化`w`值和`b`值,也是最小化该值一半的平方),但是  有很好又简单的导数(只有`w`), 在`w=0`处是不可微的。优化算法在可微函数表现得更好。
为了获得软间隔的目标,我们需要对每个样本应用一个松弛变量(slack variable)!
[
\zeta^{(i)} \ge 0
](
../images/tex-68c09d43aa56238535663931cc8887b9.gif
)
。!
[
\zeta^{(i)}
](
../images/tex-328b39f0c7d087f501c1f45ed2b361e5.gif
)
表示了第
`i`
个样本允许违规间隔的程度。我们现在有两个不一致的目标:一个是使松弛变量尽可能的小,从而减小间隔违规,另一个是使
`1/2 w·w`
尽量小,从而增大间隔。这时
`C`
超参数发挥作用:它允许我们在两个目标之间权衡。我们得到了公式 5-4 的约束优化问题。
...
...
images/tex-03549015bd48d379883d926e6857b448.gif
0 → 100644
浏览文件 @
6e6e8e21
207 字节
images/tex-8b908429a5b5ee2e519f8caa16f82ee1.gif
0 → 100644
浏览文件 @
6e6e8e21
845 字节
images/tex-98c822c91ab5af02c383eb03fa5b5446.gif
0 → 100644
浏览文件 @
6e6e8e21
381 字节
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}
{kind=link}