Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
OpenDocCN
hands-on-ml-zh
提交
0e81df51
H
hands-on-ml-zh
项目概览
OpenDocCN
/
hands-on-ml-zh
通知
13
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
H
hands-on-ml-zh
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
体验新版 GitCode,发现更多精彩内容 >>
提交
0e81df51
编写于
5月 03, 2018
作者:
P
Peter Ho
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
some fix
上级
94b8a865
变更
3
隐藏空白更改
内联
并排
Showing
3 changed file
with
11 addition
and
7 deletion
+11
-7
docs/5.支持向量机.md
docs/5.支持向量机.md
+1
-0
docs/7.集成学习和随机森林.md
docs/7.集成学习和随机森林.md
+6
-6
docs/8.降维.md
docs/8.降维.md
+4
-1
未找到文件。
docs/5.支持向量机.md
浏览文件 @
0e81df51
# 第5章 支持向量机
支持向量机(SVM)是个非常强大并且有多种功能的机器学习模型,能够做线性或者非线性的分类,回归,甚至异常值检测。机器学习领域中最为流行的模型之一,是任何学习机器学习的人必备的工具。SVM 特别适合复杂的分类,而中小型的数据集分类中很少用到。
本章节将阐述支持向量机的核心概念,怎么使用这个强大的模型,以及它是如何工作的。
## 线性支持向量机分类
...
...
docs/7.集成学习和随机森林.md
浏览文件 @
0e81df51
...
...
@@ -73,7 +73,7 @@ VotingClassifier 0.896
正如你在图 7-4 上所看到的,分类器可以通过不同的 CPU 核或其他的服务器一起被训练。相似的,分类器也可以一起被制作。这就是为什么 Bagging 和 Pasting 是如此流行的原因之一:它们的可扩展性很好。
## 在 sklearn 中的 Bagging 和 Pasting
##
#
在 sklearn 中的 Bagging 和 Pasting
sklearn 为 Bagging 和 Pasting 提供了一个简单的API:
`BaggingClassifier`
类(或者对于回归可以是
`BaggingRegressor`
。接下来的代码训练了一个 500 个决策树分类器的集成,每一个都是在数据集上有放回采样 100 个训练实例下进行训练(这是 Bagging 的例子,如果你想尝试 Pasting,就设置
`bootstrap=False`
)。
`n_jobs`
参数告诉 sklearn 用于训练和预测所需要 CPU 核的数量。(-1 代表着 sklearn 会使用所有空闲核):
...
...
@@ -92,7 +92,7 @@ sklearn 为 Bagging 和 Pasting 提供了一个简单的API:`BaggingClassifier
Bootstrap 在每个预测器被训练的子集中引入了更多的分集,所以 Bagging 结束时的偏差比 Pasting 更高,但这也意味着预测因子最终变得不相关,从而减少了集合的方差。总体而言,Bagging 通常会导致更好的模型,这就解释了为什么它通常是首选的。然而,如果你有空闲时间和 CPU 功率,可以使用交叉验证来评估 Bagging 和 Pasting 哪一个更好。
## Out-of-Bag 评价
##
#
Out-of-Bag 评价
对于 Bagging 来说,一些实例可能被一些分类器重复采样,但其他的有可能不会被采样。
`BaggingClassifier`
默认采样。
`BaggingClassifier`
默认是有放回的采样
`m`
个实例 (
`bootstrap=True`
),其中
`m`
是训练集的大小,这意味着平均下来只有63%的训练实例被每个分类器采样,剩下的37%个没有被采样的训练实例就叫做
*Out-of-Bag*
实例。注意对于每一个的分类器它们的 37% 不是相同的。
...
...
@@ -153,7 +153,7 @@ array([[ 0., 1.], [ 0.60588235, 0.39411765],[ 1., 0. ],
>>>
bag_clf
=
BaggingClassifier
(
DecisionTreeClassifier
(
splitter
=
"random"
,
max_leaf_nodes
=
16
),
n_estimators
=
500
,
max_samples
=
1.0
,
bootstrap
=
True
,
n_jobs
=-
1
)
```
## 极端随机树
##
#
极端随机树
当你在随机森林上生长树时,在每个结点分裂时只考虑随机特征集上的特征(正如之前讨论过的一样)。相比于找到更好的特征我们可以通过使用对特征使用随机阈值使树更加随机(像规则决策树一样)。
...
...
@@ -163,7 +163,7 @@ array([[ 0., 1.], [ 0.60588235, 0.39411765],[ 1., 0. ],
我们很难去分辨
`ExtraTreesClassifier`
和
`RandomForestClassifier`
到底哪个更好。通常情况下是通过交叉验证来比较它们(使用网格搜索调整超参数)。
## 特征重要度
##
#
特征重要度
最后,如果你观察一个单一决策树,重要的特征会出现在更靠近根部的位置,而不重要的特征会经常出现在靠近叶子的位置。因此我们可以通过计算一个特征在森林的全部树中出现的平均深度来预测特征的重要性。sklearn 在训练后会自动计算每个特征的重要度。你可以通过
`feature_importances_`
变量来查看结果。例如如下代码在 iris 数据集(第四章介绍)上训练了一个
`RandomForestClassifier`
模型,然后输出了每个特征的重要性。看来,最重要的特征是花瓣长度(44%)和宽度(42%),而萼片长度和宽度相对比较是不重要的(分别为 11% 和 2%):
...
...
@@ -190,7 +190,7 @@ petal width (cm) 0.423357996355
提升(Boosting,最初称为
*假设增强*
)指的是可以将几个弱学习者组合成强学习者的集成方法。对于大多数的提升方法的思想就是按顺序去训练分类器,每一个都要尝试修正前面的分类。现如今已经有很多的提升方法了,但最著名的就是
*Adaboost*
(适应性提升,是
*Adaptive Boosting*
的简称) 和
*Gradient Boosting*
(梯度提升)。让我们先从
*Adaboost*
说起。
## Adaboost
##
#
Adaboost
使一个新的分类器去修正之前分类结果的方法就是对之前分类结果不对的训练实例多加关注。这导致新的预测因子越来越多地聚焦于这种情况。这是
*Adaboost*
使用的技术。
...
...
@@ -252,7 +252,7 @@ sklearn 通常使用 Adaboost 的多分类版本 *SAMME*(这就代表了 *分
如果你的 Adaboost 集成过拟合了训练集,你可以尝试减少基分类器的数量或者对基分类器使用更强的正则化。
## 梯度提升
##
#
梯度提升
另一个非常著名的提升算法是梯度提升。与 Adaboost 一样,梯度提升也是通过向集成中逐步增加分类器运行的,每一个分类器都修正之前的分类结果。然而,它并不像 Adaboost 那样每一次迭代都更改实例的权重,这个方法是去使用新的分类器去拟合前面分类器预测的
*残差*
。
...
...
docs/8.降维.md
浏览文件 @
0e81df51
...
...
@@ -55,9 +55,12 @@
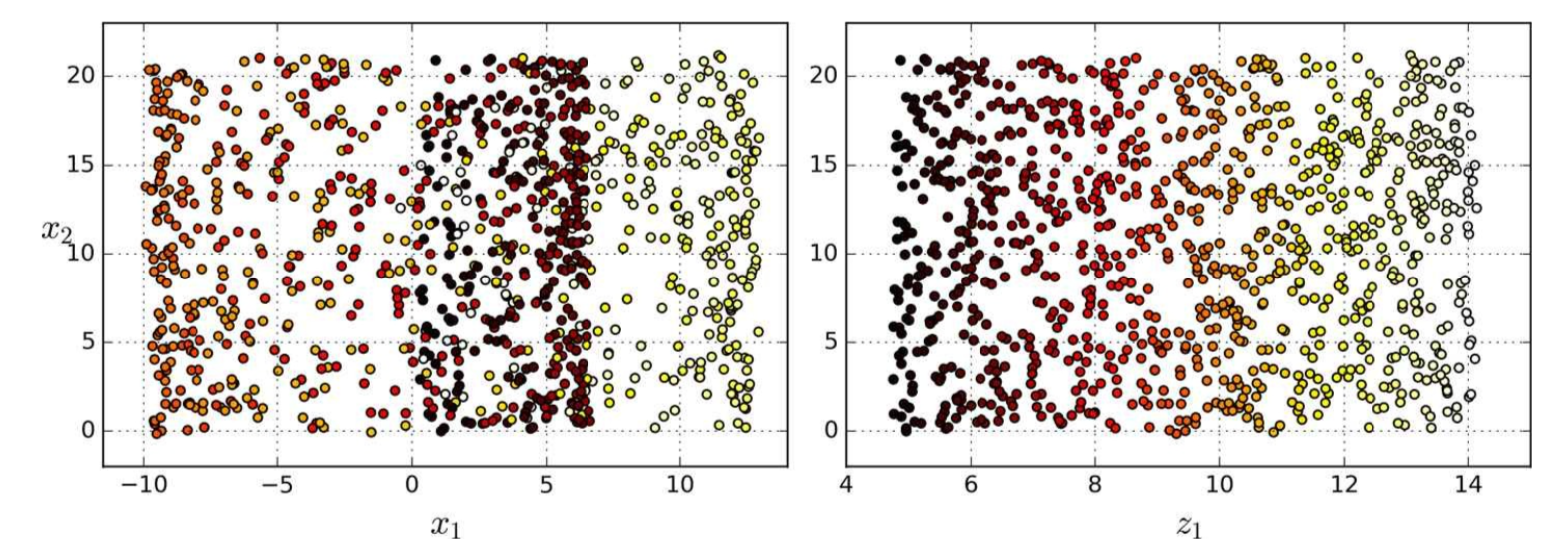
图 8-5 投射到平面的压缩(左)vs 展开瑞士卷(右)
### 流形学习
瑞士卷一个是二维流形的例子。简而言之,二维流形是一种二维形状,它可以在更高维空间中弯曲或扭曲。更一般地,一个
`d`
维流形是类似于
`d`
维超平面的
`n`
维空间(其中
`d < n`
)的一部分。在我们瑞士卷这个例子中,
`d = 2`
,
`n = 3`
:它有些像 2D 平面,但是它实际上是在第三维中卷曲。
许多降维算法通过对训练实例所在的流形进行建模从而达到降维目的;这叫做流形学习。它依赖于流形猜想(manifold assumption),也被称为流形假设(manifold hypothesis),它认为大多数现实世界的高维数据集大都靠近一个更低维的流形。这种假设经常在实践中被证实。
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录