Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
OpenDocCN
ds-ipynb-zh
提交
d94289bf
D
ds-ipynb-zh
项目概览
OpenDocCN
/
ds-ipynb-zh
10 个月 前同步成功
通知
1
Star
74
Fork
24
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
D
ds-ipynb-zh
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
d94289bf
编写于
1月 04, 2019
作者:
W
wizardforcel
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
9.6-9.7
上级
84075c84
变更
5
隐藏空白更改
内联
并排
Showing
5 changed file
with
557 addition
and
0 deletion
+557
-0
docs/9.6.md
docs/9.6.md
+243
-0
docs/9.7.md
docs/9.7.md
+314
-0
img/9-6-1.png
img/9-6-1.png
+0
-0
img/9-7-1.png
img/9-7-1.png
+0
-0
img/9-7-2.png
img/9-7-2.png
+0
-0
未找到文件。
docs/9.6.md
0 → 100644
浏览文件 @
d94289bf
## 9.6 聚合:最小、最大和之间的任何东西
> 本节是[《Python 数据科学手册》](https://github.com/jakevdp/PythonDataScienceHandbook)(Python Data Science Handbook)的摘录。
>
> 译者:[飞龙](https://github.com/wizardforcel)
>
> 协议:[CC BY-NC-SA 4.0](http://creativecommons.org/licenses/by-nc-sa/4.0/)
通常,当面对大量数据时,第一步是计算相关数据的汇总统计信息。
也许最常见的汇总统计数据是均值和标准差,它允许你汇总数据集中的“典型”值,但其他汇总也很有用(总和,乘积,中位数,最小值和最大值,分位数等)。
NumPy 具有内置的快速的聚合函数,可用于处理数组;我们将在这里讨论和演示其中的一些内容。
### 对数组中的值求和
作为一个简单的例子,考虑计算数组中所有值的总和。Python 本身可以使用内置的
``sum``
函数来实现:
```
py
import
numpy
as
np
L
=
np
.
random
.
random
(
100
)
sum
(
L
)
# 55.61209116604941
```
NumPy 的
``sum``
函数的语法非常相似,结果在最简单的情况下是相同的:
```
py
np
.
sum
(
L
)
# 55.612091166049424
```
但是,因为它在编译代码中执行操作,所以操作的 NumPy 版本计算速度更快:
```
py
big_array
=
np
.
random
.
rand
(
1000000
)
%
timeit
sum
(
big_array
)
%
timeit
np
.
sum
(
big_array
)
'''
10 loops, best of 3: 104 ms per loop
1000 loops, best of 3: 442 μs per loop
'''
```
但要小心:
``sum``
函数和
``np.sum``
函数不相同,有时会产生混乱!
特别是,它们的可选参数具有不同的含义,并且
``np.sum``
知道多个数组维度,我们将在下一节中看到。
### 最小和最大
类似地,Python 内置了
``min``
和
``max``
函数,用于查找任何给定数组的最小值和最大值:
```
py
min
(
big_array
),
max
(
big_array
)
# (1.1717128136634614e-06, 0.9999976784968716)
```
NumPy 的相应函数具有相似的语法,并且同样运行得更快:
```
py
np
.
min
(
big_array
),
np
.
max
(
big_array
)
# (1.1717128136634614e-06, 0.9999976784968716)
%
timeit
min
(
big_array
)
%
timeit
np
.
min
(
big_array
)
'''
10 loops, best of 3: 82.3 ms per loop
1000 loops, best of 3: 497 μs per loop
'''
```
对于
``min``
,
``max``
,
``sum``
和其他几个 NumPy 聚合,更短的语法是使用数组对象本身的方法:
```
py
print
(
big_array
.
min
(),
big_array
.
max
(),
big_array
.
sum
())
# 1.17171281366e-06 0.999997678497 499911.628197
```
只要有可能,请确保在 NumPy 数组上运行时,使用这些聚合的 NumPy 版本!
#### 多维聚合
一种常见类型的聚合操作是沿行或列的聚合。假设你有一些存储在二维数组中的数据:
```
py
M
=
np
.
random
.
random
((
3
,
4
))
print
(
M
)
'''
[[ 0.8967576 0.03783739 0.75952519 0.06682827]
[ 0.8354065 0.99196818 0.19544769 0.43447084]
[ 0.66859307 0.15038721 0.37911423 0.6687194 ]]
'''
```
默认情况下,每个NumPy聚合函数都将返回整个数组的聚合:
```
py
M
.
sum
()
# 6.0850555667307118
```
聚合函数接受另一个参数来指定计算聚合的轴。 例如,我们可以通过指定
``axis = 0``
,寻找每列中的最小值:
```
py
M
.
min
(
axis
=
0
)
# array([ 0.66859307, 0.03783739, 0.19544769, 0.06682827])
```
该函数返回四个值,对应于四列数字。同样,我们可以在每行中找到最大值:
```
py
M
.
max
(
axis
=
1
)
# array([ 0.8967576 , 0.99196818, 0.6687194 ])
```
此处指定轴的方式,可能会使来自其他语言的用户感到困惑。
``axis``
关键字指定要折叠的数组的维度,而不是将返回的维度。
因此,指定
``axis = 0``
意味着折叠第一个轴:对于二维数组,这意味着将聚合每列中的值。
#### 其它聚合函数
NumPy 提供了许多其他聚合函数,但我们不会在这里详细讨论它们。
此外,大多数聚合都有一个
`NaN`
安全的替代品来计算结果,同时忽略缺失值,缺失值由特殊的 IEEE 浮点
`NaN`
值标记(对于缺失数据的更全面讨论,请参阅“处理缺失数据)。
其中一些
`NaN`
安全的函数直到 NumPy 1.8 才被添加,所以它们在旧的 NumPy 版本中不可用。
下表提供了 NumPy 中可用的实用聚合函数的列表:
| 函数名称 | NaN 安全的版本 | 描述 |
|-------------------|---------------------|-----------------------------------------------|
|
``np.sum``
|
``np.nansum``
| 计算元素的和 |
|
``np.prod``
|
``np.nanprod``
| 计算元素的积 |
|
``np.mean``
|
``np.nanmean``
| 计算元素的均值 |
|
``np.std``
|
``np.nanstd``
| 计算标准差 |
|
``np.var``
|
``np.nanvar``
| 计算方差 |
|
``np.min``
|
``np.nanmin``
| 寻找最小值 |
|
``np.max``
|
``np.nanmax``
| 寻找最大值 |
|
``np.argmin``
|
``np.nanargmin``
| 寻找最小值的下标 |
|
``np.argmax``
|
``np.nanargmax``
| 寻找最大值的下标 |
|
``np.median``
|
``np.nanmedian``
| 计算元素的中值 |
|
``np.percentile``
|
``np.nanpercentile``
| 计算元素的百分位数 |
|
``np.any``
| N/A | 计算是否任何元素是真 |
|
``np.all``
| N/A | 计算是否所有元素是真 |
我们将在本书的其余部分经常看到这些聚合。
### 示例:美国总统的平均身高是多少?
NumPy 中可用的聚合对于汇总一组值非常有用。举个简单的例子,让我们考虑所有美国总统的身高。此数据位于
`president_heights.csv`
文件中,该文件是一个简单的逗号分隔的标签和值的列表:
```
py
!
head
-
4
data
/
president_heights
.
csv
'''
order,name,height(cm)
1,George Washington,189
2,John Adams,170
3,Thomas Jefferson,189
'''
```
我们将使用 Pandas 软件包,来读取文件并提取信息(请注意,高度以厘米为单位)。我们将在第三章中更全面地探索 Pandas。
```
py
import
pandas
as
pd
data
=
pd
.
read_csv
(
'data/president_heights.csv'
)
heights
=
np
.
array
(
data
[
'height(cm)'
])
print
(
heights
)
'''
[189 170 189 163 183 171 185 168 173 183 173 173 175 178 183 193 178 173
174 183 183 168 170 178 182 180 183 178 182 188 175 179 183 193 182 183
177 185 188 188 182 185]
'''
```
现在我们有了这个数据数组,我们可以计算各种汇总统计数据:
```
py
print
(
"Mean height: "
,
heights
.
mean
())
print
(
"Standard deviation:"
,
heights
.
std
())
print
(
"Minimum height: "
,
heights
.
min
())
print
(
"Maximum height: "
,
heights
.
max
())
'''
Mean height: 179.738095238
Standard deviation: 6.93184344275
Minimum height: 163
Maximum height: 193
'''
```
请注意,在每种情况下,聚合操作都会将整个数组缩减为单个汇总值,从而为我们提供值分布的信息。
我们也可能打算计算分位数:
```
py
print
(
"25th percentile: "
,
np
.
percentile
(
heights
,
25
))
print
(
"Median: "
,
np
.
median
(
heights
))
print
(
"75th percentile: "
,
np
.
percentile
(
heights
,
75
))
'''
25th percentile: 174.25
Median: 182.0
75th percentile: 183.0
'''
```
我们看到美国总统的身高中值为 182 厘米,或者只有 6 英尺。
当然,有时看到这些数据的直观表示更有用,我们可以使用 Matplotlib 中的工具来完成(我们将在第四章中更全面地讨论 Matplotlib)。 例如,此代码生成以下图表:
```
py
%
matplotlib
inline
import
matplotlib.pyplot
as
plt
import
seaborn
;
seaborn
.
set
()
# 设置绘图风格
plt
.
hist
(
heights
)
plt
.
title
(
'Height Distribution of US Presidents'
)
plt
.
xlabel
(
'height (cm)'
)
plt
.
ylabel
(
'number'
);
```

这些聚合是探索性数据分析的一些基本部分,我们将在本书的后续章节中进行更深入的探索。
docs/9.7.md
0 → 100644
浏览文件 @
d94289bf
## 9.7 数组上的计算:广播
> 本节是[《Python 数据科学手册》](https://github.com/jakevdp/PythonDataScienceHandbook)(Python Data Science Handbook)的摘录。
>
> 译者:[飞龙](https://github.com/wizardforcel)
>
> 协议:[CC BY-NC-SA 4.0](http://creativecommons.org/licenses/by-nc-sa/4.0/)
我们在上一节中看到,NumPy 的通用函数如何用于向量化操作,从而消除缓慢的 Python 循环。向量化操作的另一种方法是使用 NumPy 的广播功能。广播只是一组规则,用于在不同大小的数组上应用二元
`ufunc`
(例如,加法,减法,乘法等)。
### 广播简介
回想一下,对于相同大小的数组,二元操作是逐元素执行的:
```
py
import
numpy
as
np
a
=
np
.
array
([
0
,
1
,
2
])
b
=
np
.
array
([
5
,
5
,
5
])
a
+
b
# array([5, 6, 7])
```
广播允许在不同大小的数组上执行这类二元操作 - 例如,我们可以轻松将数组和标量相加(将其视为零维数组):
```
py
a
+
5
# array([5, 6, 7])
```
我们可以将此视为一个操作,将值
`5`
拉伸或复制为数组
`[5,5,5]`
,并将结果相加。
NumPy 广播的优势在于,这种值的重复实际上并没有发生,但是当我们考虑广播时,它是一种有用的心理模型。
我们可以类似地,将其扩展到更高维度的数组。 将两个二维数组相加时观察结果:
```
py
M
=
np
.
ones
((
3
,
3
))
M
'''
array([[ 1., 1., 1.],
[ 1., 1., 1.],
[ 1., 1., 1.]])
'''
M
+
a
'''
array([[ 1., 2., 3.],
[ 1., 2., 3.],
[ 1., 2., 3.]])
'''
```
这里,一维数组
`a`
被拉伸,或者在第二维上广播,来匹配
`M`
的形状。
虽然这些示例相对容易理解,但更复杂的情况可能涉及两个数组的广播。请考虑以下示例:
```
py
a
=
np
.
arange
(
3
)
b
=
np
.
arange
(
3
)[:,
np
.
newaxis
]
print
(
a
)
print
(
b
)
'''
[0 1 2]
[[0]
[1]
[2]]
'''
a
+
b
'''
array([[0, 1, 2],
[1, 2, 3],
[2, 3, 4]])
'''
```
就像之前我们拉伸或广播一个值来匹配另一个的形状,这里我们拉伸
``a```和``b``来匹配一个共同的形状,结果是二维数组!
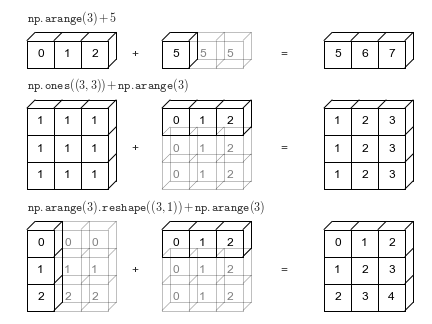
这些示例的几何图形为下图(产生此图的代码可以在“附录”中找到,并改编自 [astroML](http://astroml.org) 中发布的源码,经许可而使用)。

浅色方框代表广播的值:同样,这个额外的内存实际上并没有在操作过程中分配,但是在概念上想象它是有用的。
### 广播规则
NumPy 中的广播遵循一套严格的规则来确定两个数组之间的交互:
- 规则 1:如果两个数组的维数不同,则维数较少的数组的形状,将在其左侧填充。
- 规则 2:如果两个数组的形状在任何维度上都不匹配,则该维度中形状等于 1 的数组将被拉伸来匹配其他形状。
- 规则 3:如果在任何维度中,大小不一致且都不等于 1,则会引发错误。
为了讲清楚这些规则,让我们详细考虑几个例子。
#### 广播示例 1
让我们看一下将二维数组和一维数组相加:
```py
M = np.ones((2, 3))
a = np.arange(3)
```
让我们考虑这两个数组上的操作。数组的形状是。
- ``M.shape = (2, 3)``
- ``a.shape = (3,)``
我们在规则 1 中看到数组``a``的维数较少,所以我们在左边填充它:
- ``M.shape -> (2, 3)``
- ``a.shape -> (1, 3)``
根据规则 2,我们现在看到第一个维度不一致,因此我们将此维度拉伸来匹配:
- ``M.shape -> (2, 3)``
- ``a.shape -> (2, 3)``
形状匹配了,我们看到最终的形状将是``(2, 3)``
```py
M + a
'''
array([[ 1., 2., 3.],
[ 1., 2., 3.]])
'''
```
#### 广播示例 2
我们来看一个需要广播两个数组的例子:
```py
a = np.arange(3).reshape((3, 1))
b = np.arange(3)
```
同样,我们将首先写出数组的形状:
- ``a.shape = (3, 1)``
- ``b.shape = (3,)``
规则 1 说我们必须填充`
b
`的形状:
- ``a.shape -> (3, 1)``
- ``b.shape -> (1, 3)``
规则 2 告诉我们,我们更新这些中的每一个,来匹配另一个数组的相应大小:
- ``a.shape -> (3, 3)``
- ``b.shape -> (3, 3)``
因为结果匹配,所以这些形状是兼容的。我们在这里可以看到:
```py
a + b
'''
array([[0, 1, 2],
[1, 2, 3],
[2, 3, 4]])
'''
```
#### 广播示例 3
现在让我们来看一个两个数组不兼容的例子:
```py
M = np.ones((3, 2))
a = np.arange(3)
```
这与第一个例子略有不同:矩阵`
M
`是转置的。这对计算有何影响?数组的形状是
- ``M.shape = (3, 2)``
- ``a.shape = (3,)``
同样,规则 1 告诉我们必须填充`
a
`的形状:
- ``M.shape -> (3, 2)``
- ``a.shape -> (1, 3)``
根据规则 2,`
a
`的第一个维度被拉伸来匹配`
M
`:
- ``M.shape -> (3, 2)``
- ``a.shape -> (3, 3)``
现在我们到了规则 3 - 最终的形状不匹配,所以这两个数组是不兼容的,正如我们可以通过尝试此操作来观察:
```py
M + a
'''
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-13-9e16e9f98da6> in <module>()
----> 1 M + a
ValueError: operands could not be broadcast together with shapes (3,2) (3,)
'''
```
注意这里潜在的混淆:你可以想象使``a``和``M``兼容,比如在右边填充``a``的形状,而不是在左边。但这不是广播规则的运作方式!
在某些情况下,这种灵活性可能会有用,但这会导致潜在的二义性。如果在右侧填充是你想要的,你可以通过数组的形状调整,来明确地执行此操作(我们将使用“NumPy 数组基础”中介绍的``np.newaxis``关键字):
```py
a[:, np.newaxis].shape
# (3, 1)
M + a[:, np.newaxis]
'''
array([[ 1., 1.],
[ 2., 2.],
[ 3., 3.]])
'''
```
还要注意,虽然我们一直专注于``+``运算符,但这些广播规则适用于任何二元``ufunc``。
例如,这里是``logaddexp(a, b)``函数,它比原始方法更精确地计算``log(exp(a) + exp(b))``:
```py
np.logaddexp(M, a[:, np.newaxis])
'''
array([[ 1.31326169, 1.31326169],
[ 1.69314718, 1.69314718],
[ 2.31326169, 2.31326169]])
'''
```
对于可用的通用函数的更多信息,请参阅“NumPy 数组上的计算:通用函数”。
### 实战中的广播
广播操作是我们将在本书中看到的许多例子的核心。我们现在来看一些它们可能有用的简单示例。
#### 数组中心化
在上一节中,我们看到`
ufunc
`允许 NumPy 用户不再需要显式编写慢速 Python 循环。广播扩展了这种能力。一个常见的例子是数据数组的中心化。
想象一下,你有一组 10 个观测值,每个观测值由 3 个值组成。使用标准约定(参见“Scikit-Learn 中的数据表示”),我们将其存储在`
10x3
`数组中:
```py
X = np.random.random((10, 3))
```
我们可以使用第一维上的“均值”聚合,来计算每个特征的平均值:
```py
Xmean = X.mean(0)
Xmean
# array([ 0.53514715, 0.66567217, 0.44385899])
```
现在我们可以通过减去均值(这是一个广播操作)来中心化``X``数组:
```py
X_centered = X - Xmean
```
要仔细检查我们是否已正确完成此操作,我们可以检查中心化的数组是否拥有接近零的均值:
```py
X_centered.mean(0)
# array([ 2.22044605e-17, -7.77156117e-17, -1.66533454e-17])
```
在机器精度范围内,平均值现在为零。
#### 绘制二维函数
广播非常有用的一个地方是基于二维函数展示图像。如果我们想要定义一个函数`
z = f(x, y)
`,广播可用于在网格中计算函数:
```py
# x 和 y 是从 0 到 5 的 50 步
x = np.linspace(0, 5, 50)
y = np.linspace(0, 5, 50)[:, np.newaxis]
z = np.sin(x) ** 10 + np.cos(10 + y * x) * np.cos(x)
```
我们将使用 Matplotlib 绘制这个二维数组(这些工具将在“密度和等高线图”中完整讨论):
```py
%matplotlib inline
import matplotlib.pyplot as plt
plt.imshow(z, origin='lower', extent=[0, 5, 0, 5],
cmap='viridis')
plt.colorbar();
``
`

结果是引人注目的二维函数的图形。
img/
6_41_0
.png
→
img/
9-6-1
.png
浏览文件 @
d94289bf
文件已移动
img/9-7-1.png
0 → 100644
浏览文件 @
d94289bf
16.6 KB
img/
7_54_0
.png
→
img/
9-7-2
.png
浏览文件 @
d94289bf
文件已移动
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}
{kind=link}