tex
Showing
{kind=link}
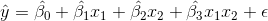
964 字节
{kind=link}
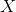
152 字节
{kind=link}
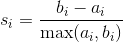
708 字节
{kind=link}
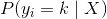
484 字节
{kind=link}
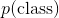
387 字节
{kind=link}

145 字节
{kind=link}
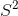
181 字节
{kind=link}

158 字节
{kind=link}
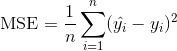
990 字节
{kind=link}
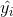
170 字节
{kind=link}
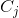
178 字节
{kind=link}

114 字节
{kind=link}
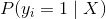
461 字节
{kind=link}
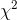
176 字节
{kind=link}
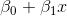
345 字节
{kind=link}
538 字节
{kind=link}

130 字节
{kind=link}
3.1 KB
{kind=link}

137 字节
{kind=link}

1.0 KB
{kind=link}
580 字节
{kind=link}

1.5 KB
{kind=link}
166 字节
{kind=link}
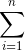
326 字节
{kind=link}
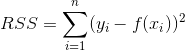
987 字节
{kind=link}
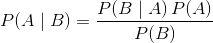
1.1 KB
{kind=link}
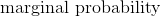
710 字节
{kind=link}
182 字节
{kind=link}
876 字节
{kind=link}
137 字节
{kind=link}
1.6 KB
{kind=link}
2.5 KB
{kind=link}
2.4 KB
{kind=link}
376 字节
{kind=link}

210 字节
{kind=link}

144 字节
{kind=link}
128 字节
{kind=link}
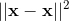
299 字节
{kind=link}
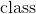
245 字节
{kind=link}
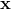
131 字节
{kind=link}
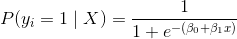
917 字节
{kind=link}

133 字节
{kind=link}
129 字节
{kind=link}

2.7 KB
{kind=link}
273 字节
{kind=link}

140 字节
{kind=link}
141 字节
{kind=link}

117 字节
{kind=link}
232 字节
{kind=link}
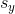
158 字节
{kind=link}
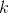
133 字节
{kind=link}
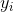
158 字节
{kind=link}
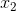
162 字节
{kind=link}
135 字节
{kind=link}
385 字节
{kind=link}
171 字节
{kind=link}
838 字节
{kind=link}
155 字节
{kind=link}
124 字节
{kind=link}
539 字节
{kind=link}
1.7 KB
{kind=link}

395 字节
{kind=link}
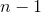
178 字节
{kind=link}
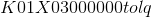
751 字节
{kind=link}
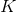
157 字节
{kind=link}
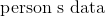
490 字节
{kind=link}
173 字节
{kind=link}

1.6 KB
{kind=link}
244 字节
{kind=link}
169 字节
{kind=link}
2.8 KB
{kind=link}
407 字节
{kind=link}
223 字节
{kind=link}
156 字节
{kind=link}
1.5 KB
{kind=link}
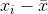
203 字节
{kind=link}
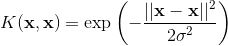
1.1 KB
{kind=link}
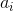
145 字节
{kind=link}
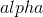
298 字节
{kind=link}
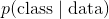
558 字节
{kind=link}
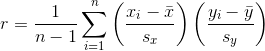
1.4 KB
{kind=link}
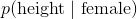
680 字节
{kind=link}
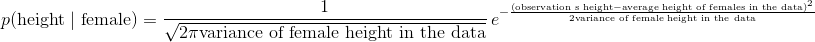
3.0 KB
{kind=link}

114 字节
{kind=link}

138 字节
{kind=link}
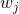
172 字节
{kind=link}
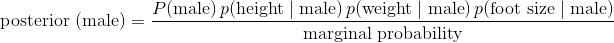
2.9 KB
{kind=link}
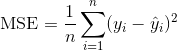
994 字节
{kind=link}
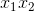
218 字节
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
src/process_tex.js
0 → 100644
此差异已折叠。