Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
OpenDocCN
Developer Zero To Mastery
提交
16cc88de
D
Developer Zero To Mastery
项目概览
OpenDocCN
/
Developer Zero To Mastery
通知
0
Star
1
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
D
Developer Zero To Mastery
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
16cc88de
编写于
5月 25, 2019
作者:
王下邀月熊-WxChevalier
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
feat: update articles
上级
630533ef
变更
1
隐藏空白更改
内联
并排
Showing
1 changed file
with
55 addition
and
0 deletion
+55
-0
RoadMap/DataScienceAI-RoadMap.md
RoadMap/DataScienceAI-RoadMap.md
+55
-0
未找到文件。
RoadMap/DataScienceAI-RoadMap.md
浏览文件 @
16cc88de
# 数据科学与机器学习进阶指南
# 统计学基础
-
相关性分析(相关系数 r、皮尔逊相关系数、余弦相似度、互信息)
-
回归分析(线性回归、L1/L2 正则、PCA/LDA 降维)
-
聚类分析(K-Means)
-
分布(正态分布、t 分布、密度函数)
-
指标(协方差、ROC 曲线、AUC、变异系数、F1-Score)
-
显著性检验(t 检验、z 检验、卡方检验)
-
A/B 测试
# 机器学习
关联规则(Apriori、FP-Growth)
回归(Linear Regression、Logistics Regression)
决策树(ID3、C4.5、CART、GBDT、RandomForest)SVM(各种核函数)
推荐(User-CF、Item-CF)
推荐阅读:《集体智慧编程》、Andrew Ng — Machine Learning Coursera from Stanford
## 特征工程
可用性评估:获取难度、覆盖率、准确率
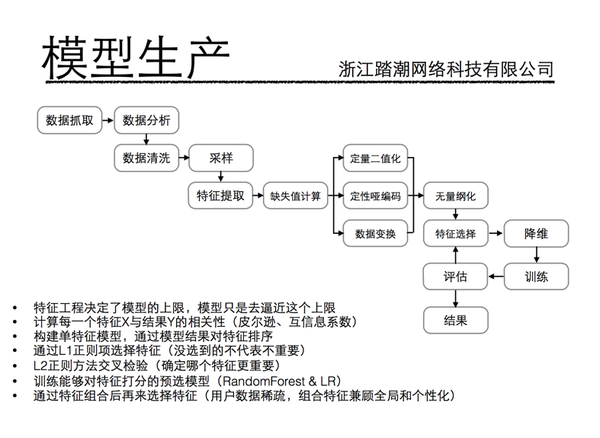
特征清洗:清洗异常样本采样:数据不均衡、样本权重单个特征:无量纲化(标准化、归一化)、二值化、离散化、缺失值(均值)、哑编码(一个定性特征扩展为 N 个定量特征)数据变换:log、指数、Box-Cox 降维:主成分分析 PCA、线性判别分析 LDA、SVD 分解特征选择:Filter(相关系数、卡方检验)、Wrapper(AUC、设计评价函数 A
\*
、Embedded(L1-Lasso、L2-Ridge、决策树、DL)衍生变量:组合特征特征监控:监控重要特征,fa 特征质量下降我放一张公司内部算法培训关于特征工程的 PPT,仅供学习参考:
再往后你就可以在技能树上点几个酷炫的了:
提升 Adaboost 加法模型 xgboostSVM
软间隔损失函数核函数 SMO 算法 libSVM 聚类
K-Means 并查集 K-Medoids 聚谱类 SCEM 算法
Jensen 不等式混合高斯分布 pLSA 主题模型
共轭先验分布贝叶斯停止词和高频词 TF-IDF 词向量
word2vecn-gramHMM
前向/后向算法 Baum-WelchViterbi 中文分词数据计算平台
SparkCaffeTensorFlow 推荐阅读:周志华——《机器学习》
可以看到,不管你是用 TensorFlow 还是用 Caffe 还是用 MXNET 等等一系列平台来做高大上的 Deep Learning,在我看来都是次要的。想要在这个行业长久地活下去,内功的修炼要比外功重要得多,不然会活得很累,也很难获得一个优秀的晋升空间。
最后,关注你所在行业的最新 paper,对最近的算法理论体系发展有一个大致印象,譬如计算广告领域的几大经典问题:

编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录