Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
OpenDocCN
d2l-zh
提交
95b828be
D
d2l-zh
项目概览
OpenDocCN
/
d2l-zh
通知
2
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
D
d2l-zh
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
体验新版 GitCode,发现更多精彩内容 >>
提交
95b828be
编写于
9月 13, 2017
作者:
A
Aston Zhang
提交者:
Mu Li
9月 13, 2017
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
Revise fitting tutorial (#37)
* Minor typo * Revise fitting tutorial
上级
c86112db
变更
2
隐藏空白更改
内联
并排
Showing
2 changed file
with
19 addition
and
15 deletion
+19
-15
chapter02_supervised-learning/underfit-overfit.md
chapter02_supervised-learning/underfit-overfit.md
+19
-15
img/error_model_complexity.png
img/error_model_complexity.png
+0
-0
未找到文件。
chapter02_supervised-learning/underfit-overfit.md
浏览文件 @
95b828be
...
...
@@ -24,7 +24,7 @@
之所以要了解训练误差和泛化误差,是因为统计学习理论基于这两个概念可以科学解释本节教程一开始提到的模型不同的测试效果。我们知道,理论的研究往往需要基于一些假设。而统计学习理论的一个假设是:
> 训练数据集和测试数据集里的每一个数据样本都是
独立同分布
。
> 训练数据集和测试数据集里的每一个数据样本都是
从同一个概率分布中相互独立地生成出的(独立同分布假设)
。
基于以上独立同分布假设,给定任意一个机器学习模型及其参数,它的训练误差的期望值和泛化误差都是一样的。然而从之前的章节中我们了解到,在机器学习的过程中,模型的参数并不是事先给定的,而是通过训练数据学习得出的:模型的参数在训练中使训练误差不断降低。所以,如果模型参数是通过训练数据学习得出的,那么训练误差的期望值无法高于泛化误差。换句话说,通常情况下,由训练数据学到的模型参数会使模型在训练数据上的表现不差于在测试数据上的表现。
...
...
@@ -43,12 +43,14 @@
### 模型的选择
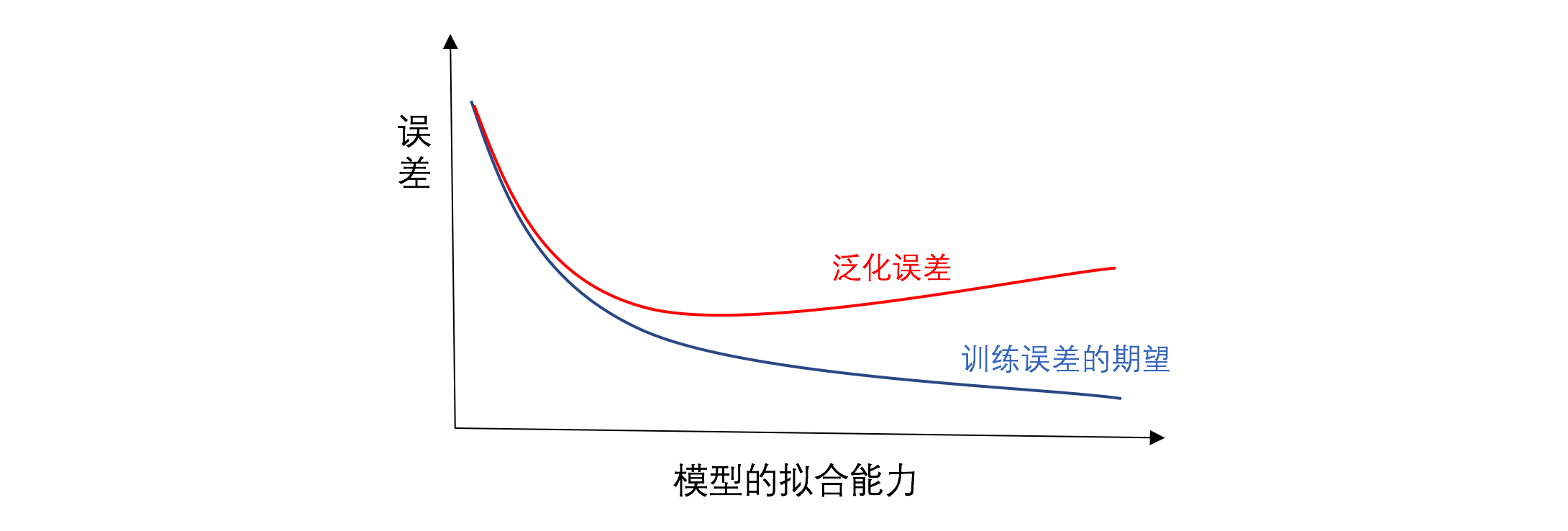
在本节的开头,我们提到一个学生可以有特定的学习能力。类似地,一个机器学习模型也有特定的拟合能力。拿多项式函数举例,一般来说高阶多项式函数比低阶多项式函数更容易在相同的训练数据集上得到较低的训练误差。
在本节的开头,我们提到一个学生可以有特定的学习能力。类似地,一个机器学习模型也有特定的拟合能力。拿多项式函数举例,一般来说,高阶多项式函数(拟合能力较强)比低阶多项式函数(拟合能力较弱)更容易在相同的训练数据集上得到较低的训练误差。需要指出的是,给定数据集,过低拟合能力的模型更容易欠拟合,而过高拟合能力的模型更容易过拟合。模型拟合能力和误差之间的关系如下图。

### 训练数据集的大小
在本节的开头,我们同样提到一个学生可以有特定的训练量。类似地,一个机器学习模型的训练数据集的样本数也可大可小。一般来说,如果训练数据集过小,特别是比模型参数数量更小时,过拟合更容易发生。除此之外,
统计学习理论中有个结论是:
泛化误差不会随训练数据集里样本数量增加而增大。
在本节的开头,我们同样提到一个学生可以有特定的训练量。类似地,一个机器学习模型的训练数据集的样本数也可大可小。一般来说,如果训练数据集过小,特别是比模型参数数量更小时,过拟合更容易发生。除此之外,泛化误差不会随训练数据集里样本数量增加而增大。
为了理解这两个因素对拟合和过拟合的影响,下面让我们来动手学习。
...
...
@@ -68,15 +70,15 @@ $$y = 1.2x - 3.4x^2 + 5.6x^3 + 5.0 + \text{noise}$$
这里噪音服从均值0和标准差为0.1的正态分布。
需要注意的是,我们用以上相同的数据生成函数来生成训练数据集和测试数据集。两个数据集的样本数都是100
0
。
需要注意的是,我们用以上相同的数据生成函数来生成训练数据集和测试数据集。两个数据集的样本数都是100。
```
{.python .input}
from mxnet import ndarray as nd
from mxnet import autograd
from mxnet import gluon
num_train = 100
0
num_test = 100
0
num_train = 100
num_test = 100
true_w = [1.2, -3.4, 5.6]
true_b = 5.0
```
...
...
@@ -100,11 +102,12 @@ square_loss = gluon.loss.L2Loss()
下面定义模型和数据读取器。
```
{.python .input}
def get
NetAndI
ter(X_train, y_train, batch_size):
def get
_net_and_i
ter(X_train, y_train, batch_size):
dataset_train = gluon.data.ArrayDataset(X_train, y_train)
data_iter_train = gluon.data.DataLoader(dataset_train, batch_size, shuffle=True)
net = gluon.nn.Sequential()
net.add(gluon.nn.Dense(1))
with net.name_scope():
net.add(gluon.nn.Dense(1))
return net, data_iter_train
```
...
...
@@ -147,11 +150,12 @@ def test(X_test, y_test, net, cur_loss):
```
{.python .input}
def learn(X_train, X_test, y_train, y_test, lr, cur_loss):
epochs =
5
0
verbose_epoch =
4
5
epochs =
10
0
verbose_epoch =
9
5
batch_size = min(10, X_train.shape[0])
net, data_iter_train = getNetAndIter(X_train, y_train, batch_size)
net_trained = train(net, data_iter_train, lr, cur_loss, epochs, verbose_epoch, batch_size)
net, data_iter_train = get_net_and_iter(X_train, y_train, batch_size)
net_trained = train(net, data_iter_train, lr, cur_loss, epochs,
verbose_epoch, batch_size)
test(X_test, y_test, net_trained, cur_loss)
```
...
...
@@ -162,7 +166,7 @@ def learn(X_train, X_test, y_train, y_test, lr, cur_loss):
```
{.python .input}
X_train_ord3, X_test_ord3 = X[:num_train, :], X[num_train:, :]
learning_rate = 0.0
1
learning_rate = 0.0
25
learn(X_train_ord3, X_test_ord3, y_train, y_test, learning_rate, square_loss)
```
...
...
@@ -173,7 +177,7 @@ learn(X_train_ord3, X_test_ord3, y_train, y_test, learning_rate, square_loss)
```
{.python .input}
x_train_ord1, x_test_ord1 = x[:num_train, :], x[num_train:, :]
learning_rate = 0.0
1
learning_rate = 0.0
25
learn(x_train_ord1, x_test_ord1, y_train, y_test, learning_rate, square_loss)
```
...
...
@@ -185,7 +189,7 @@ learn(x_train_ord1, x_test_ord1, y_train, y_test, learning_rate, square_loss)
y_train, y_test = y[0:2], y[num_train:]
X_train_ord3, X_test_ord3 = X[0:2, :], X[num_train:, :]
learning_rate = 0.0
1
learning_rate = 0.0
25
learn(X_train_ord3, X_test_ord3, y_train, y_test, learning_rate, square_loss)
```
...
...
img/error_model_complexity.png
0 → 100644
浏览文件 @
95b828be
93.5 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}