Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
OpenDocCN
d2l-zh
提交
637ef927
D
d2l-zh
项目概览
OpenDocCN
/
d2l-zh
通知
2
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
D
d2l-zh
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
体验新版 GitCode,发现更多精彩内容 >>
提交
637ef927
编写于
9月 13, 2017
作者:
M
muli
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
change tiles
上级
c6c45ad0
变更
9
隐藏空白更改
内联
并排
Showing
9 changed file
with
13 addition
and
13 deletion
+13
-13
chapter02_supervised-learning/linear-regression-gluon.md
chapter02_supervised-learning/linear-regression-gluon.md
+1
-1
chapter02_supervised-learning/linear-regression-scratch.md
chapter02_supervised-learning/linear-regression-scratch.md
+1
-1
chapter02_supervised-learning/mlp-gluon.md
chapter02_supervised-learning/mlp-gluon.md
+1
-1
chapter02_supervised-learning/mlp-scratch.md
chapter02_supervised-learning/mlp-scratch.md
+2
-2
chapter02_supervised-learning/softmax-regression-gluon.md
chapter02_supervised-learning/softmax-regression-gluon.md
+1
-1
chapter02_supervised-learning/softmax-regression-scratch.md
chapter02_supervised-learning/softmax-regression-scratch.md
+1
-1
chapter04_convolutional-neural-networks/cnn-gluon.md
chapter04_convolutional-neural-networks/cnn-gluon.md
+1
-1
chapter04_convolutional-neural-networks/cnn-scratch.md
chapter04_convolutional-neural-networks/cnn-scratch.md
+4
-4
chapter05_recurrent-neural-networks/rnn-scratch.md
chapter05_recurrent-neural-networks/rnn-scratch.md
+1
-1
未找到文件。
chapter02_supervised-learning/linear-regression-gluon.md
浏览文件 @
637ef927
#
使用Gluon的线性回归
#
线性回归 --- 使用Gluon
[
前一章
](
linear-regression-scratch.md
)
我们仅仅使用了ndarray和autograd来实现线性回归,这一章我们仍然实现同样的模型,但是使用高层抽象包
`gluon`
。
...
...
chapter02_supervised-learning/linear-regression-scratch.md
浏览文件 @
637ef927
#
从0开始的线性回归
#
线性回归 --- 从0开始
虽然强大的深度学习框架可以减少很多重复性工作,但如果你过于依赖它提供的便利抽象,那么你可能不会很容易地理解到底深度学习是如何工作的。所以我们的第一个教程是如何只利用ndarray和autograd来实现一个线性回归的训练。
...
...
chapter02_supervised-learning/mlp-gluon.md
浏览文件 @
637ef927
#
使用Gluon的多层感知机
#
多层感知机 --- 使用Gluon
我们只需要稍微改动
[
多类Logistic回归
](
../chapter01_crashcourse/softmax-regression-gluon.md
)
来实现多层感知机。
...
...
chapter02_supervised-learning/mlp-scratch.md
浏览文件 @
637ef927
#
从0开始的多层感知机
#
多层感知机 --- 从0开始
前面我们介绍了包括线性回归和多类逻辑回归的数个模型,它们的一个共同点是全是只含有一个输入层,一个输出层。这一节我们将介绍多层神经网络,就是包含至少一个隐含层的网络。
...
...
@@ -45,7 +45,7 @@ for param in params:
## 激活函数
如果我们就用线性操作符来构造多层神经网络,那么整个模型仍然只是一个线性函数。这是因为
如果我们就用线性操作符来构造多层神经网络,那么整个模型仍然只是一个线性函数。这是因为
$$
\h
at{y} = X
\c
dot W_1
\c
dot W_2 = X
\c
dot W_3 $$
...
...
chapter02_supervised-learning/softmax-regression-gluon.md
浏览文件 @
637ef927
#
使用Gluon的多类逻辑回归
#
多类逻辑回归 --- 使用Gluon
现在让我们使用gluon来更快速地实现一个多类逻辑回归。
...
...
chapter02_supervised-learning/softmax-regression-scratch.md
浏览文件 @
637ef927
#
从0开始的多类逻辑回归
#
多类逻辑回归 --- 从0开始
如果你读过了
[
从0开始的线性回归
](
linear-regression-scratch.md
)
,那么最难的部分已经过去了。现在你知道如果读取和操作数据,如何构造目标函数和对它求导,如果定义损失函数,模型和求解。
...
...
chapter04_convolutional-neural-networks/cnn-gluon.md
浏览文件 @
637ef927
#
使用Gluon的卷积神经网络
#
卷积神经网络 --- 使用Gluon
现在我们使用Gluon来实现
[
上一章的卷积神经网络
](
cnn-scratch.md
)
。
...
...
chapter04_convolutional-neural-networks/cnn-scratch.md
浏览文件 @
637ef927
#
从0开始的卷积神经网络
#
卷积神经网络 --- 从0开始
之前的教程里,在输入神经网络前我们将输入图片直接转成了向量。这样做有两个不好的地方:
...
...
@@ -39,7 +39,7 @@ print('input:', data, '\n\nweight:', w, '\n\nbias:', b, '\n\noutput:', out)
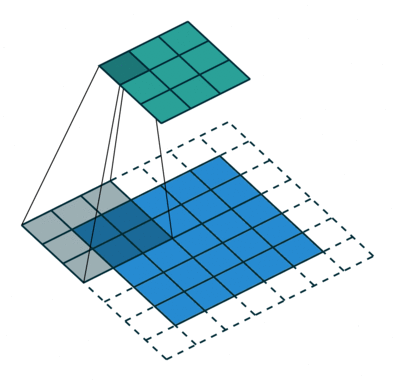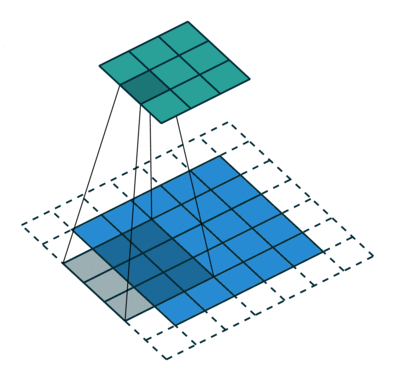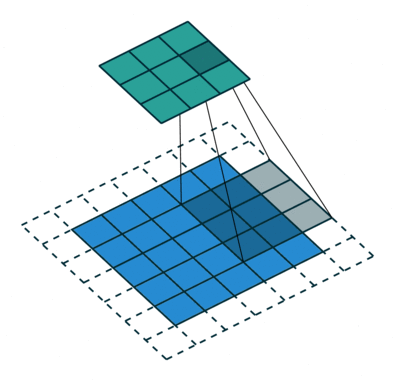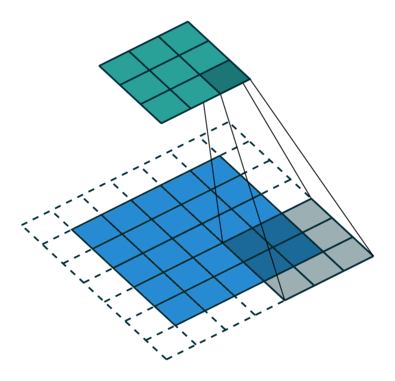
```
{.python .input n=48}
out = nd.Convolution(data, w, b, kernel=w.shape[2:], num_filter=w.shape[1],
out = nd.Convolution(data, w, b, kernel=w.shape[2:], num_filter=w.shape[1],
stride=(2,2), pad=(1,1))
print('input:', data, '\n\nweight:', w, '\n\nbias:', b, '\n\noutput:', out)
...
...
@@ -159,8 +159,8 @@ def net(X, verbose=False):
h2_conv = nd.Convolution(
data=h1, weight=W2, bias=b2, kernel=W2.shape[2:], num_filter=W2.shape[0])
h2_activation = nd.relu(h2_conv)
h2 = nd.Pooling(data=h2_activation, pool_type="max", kernel=(2,2), stride=(2,2))
h2 = nd.flatten(h2)
h2 = nd.Pooling(data=h2_activation, pool_type="max", kernel=(2,2), stride=(2,2))
h2 = nd.flatten(h2)
# 第一层全连接
h3_linear = nd.dot(h2, W3) + b3
h3 = nd.relu(h3_linear)
...
...
chapter05_recurrent-neural-networks/rnn-scratch.md
浏览文件 @
637ef927
#
从0开始的循环神经网络
#
循环神经网络 --- 从0开始
前面的教程里我们使用的网络都属于
**前馈神经网络**
。为什么叫前馈是整个网络是一条链(回想下
`gluon.nn.Sequential`
),每一层的结果都是反馈给下一层。这一节我们介绍
**循环神经网络**
,这里每一层不仅输出给下一层,同时还输出一个
**隐藏状态**
,给当前层在处理下一个样本时使用。下图展示这两种网络的区别。
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录