2020-07-13 23:19:18
Showing
此差异已折叠。
此差异已折叠。
{kind=link}

73.5 KB
{kind=link}
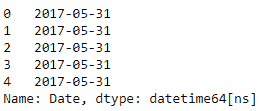
1.0 KB
{kind=link}

7.6 KB
{kind=link}
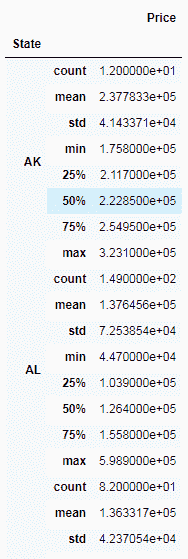
7.6 KB
{kind=link}

865 字节
{kind=link}

827 字节
{kind=link}
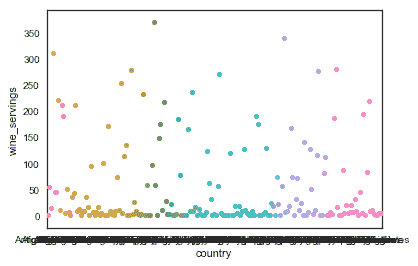
3.2 KB
{kind=link}
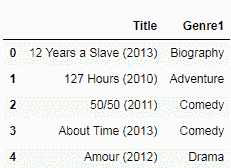
2.9 KB
{kind=link}
14.9 KB
{kind=link}
3.1 KB
{kind=link}
23.5 KB
{kind=link}
3.8 KB
{kind=link}
1.3 KB
{kind=link}

655 字节
{kind=link}
2.0 KB
{kind=link}
1.9 KB
{kind=link}

1.5 KB
{kind=link}
1.7 KB
{kind=link}

7.1 KB
{kind=link}
1.6 KB
{kind=link}
5.1 KB
{kind=link}
4.3 KB
{kind=link}
1.8 KB
{kind=link}

1.5 KB
{kind=link}

2.3 KB
{kind=link}
4.5 KB
{kind=link}
554 字节
{kind=link}
12.5 KB
{kind=link}
991 字节
{kind=link}

3.4 KB
{kind=link}
1.8 KB
{kind=link}
7.9 KB
{kind=link}
4.4 KB
{kind=link}
1.6 KB
{kind=link}
1.3 KB
{kind=link}
1.5 KB
{kind=link}
13.0 KB
{kind=link}
5.3 KB
{kind=link}
2.8 KB
{kind=link}

2.4 KB
{kind=link}

1.3 KB
{kind=link}
1.8 KB
{kind=link}
1.7 KB
{kind=link}

2.6 KB
{kind=link}
3.5 KB
{kind=link}
5.2 KB
{kind=link}
1.0 KB
{kind=link}

7.4 KB
{kind=link}

1.0 KB
{kind=link}
12.9 KB
{kind=link}
10.4 KB
{kind=link}
6.9 KB
{kind=link}

1.5 KB
{kind=link}
1.6 KB
{kind=link}
16.6 KB
{kind=link}
9.8 KB
{kind=link}

8.4 KB
{kind=link}
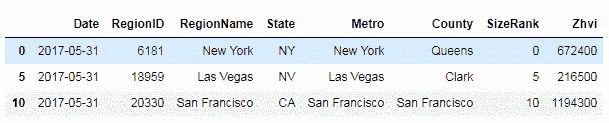
5.0 KB
{kind=link}
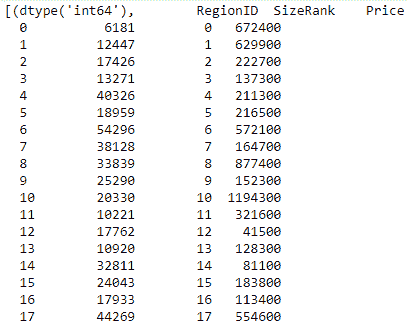
4.9 KB
{kind=link}

4.5 KB
{kind=link}

12.9 KB
{kind=link}

1.6 KB
{kind=link}

4.3 KB
{kind=link}
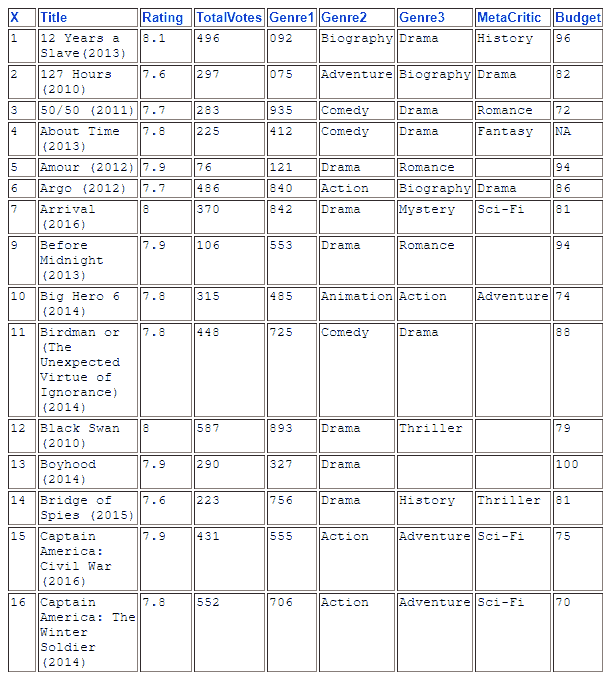
11.3 KB
{kind=link}
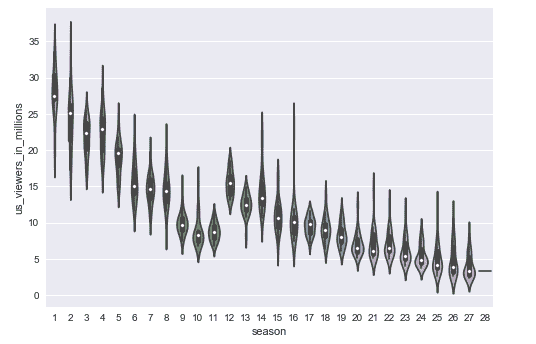
7.6 KB
{kind=link}

1.0 KB
{kind=link}
4.0 KB
{kind=link}
2.2 KB
{kind=link}

835 字节
{kind=link}

4.6 KB
{kind=link}
1.7 KB
{kind=link}
1.6 KB
{kind=link}
3.4 KB
{kind=link}

6.0 KB
{kind=link}
6.7 KB
{kind=link}

6.5 KB
{kind=link}
5.0 KB
{kind=link}

6.1 KB
{kind=link}
9.9 KB
{kind=link}
2.3 KB
{kind=link}

826 字节
{kind=link}

4.1 KB
{kind=link}
9.5 KB
{kind=link}
8.0 KB
{kind=link}

7.5 KB
{kind=link}
1.8 KB
{kind=link}

6.1 KB
{kind=link}
12.2 KB
{kind=link}

1.3 KB
{kind=link}
12.1 KB
{kind=link}
6.3 KB
{kind=link}

3.4 KB
{kind=link}
8.0 KB
{kind=link}

6.9 KB
{kind=link}
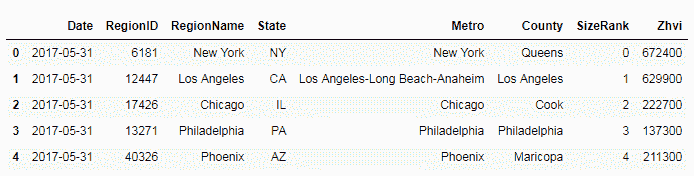
7.3 KB
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}