2020-10-19 21:22:54
Showing
{kind=link}
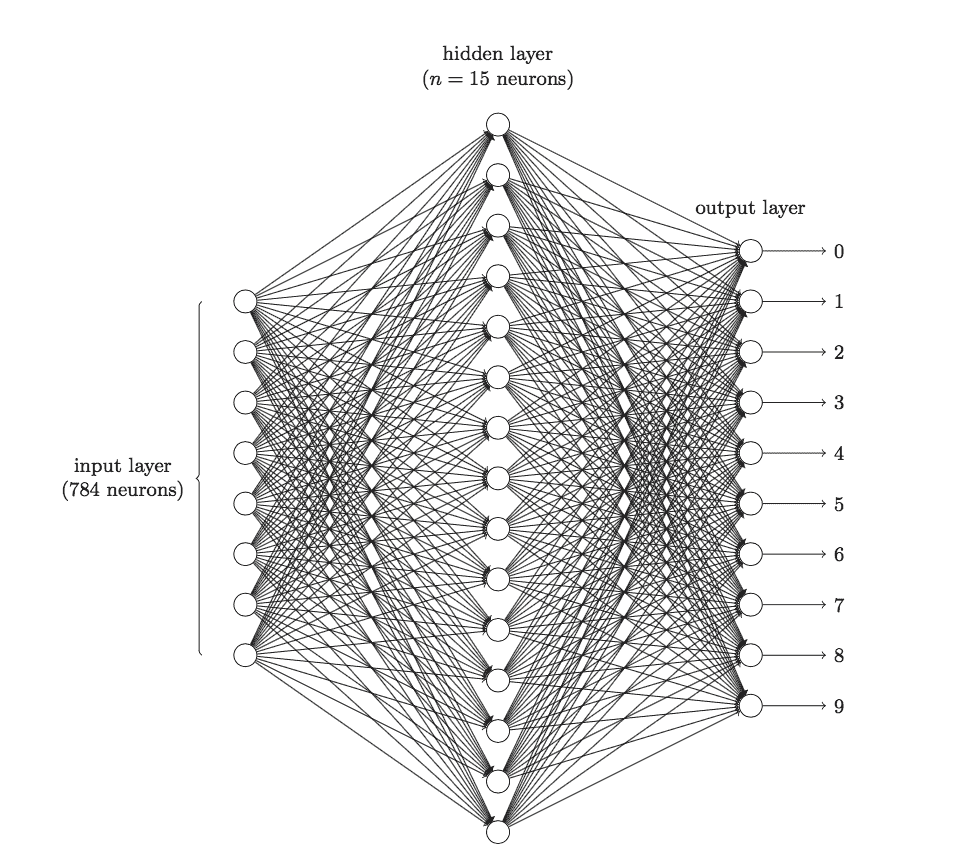
79.6 KB
{kind=link}
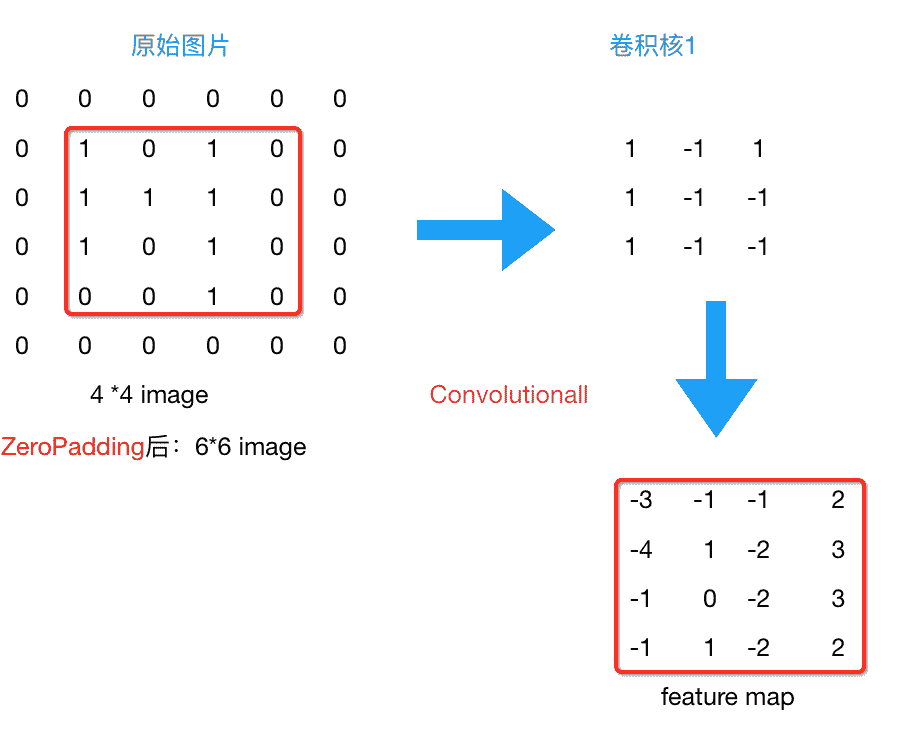
7.5 KB
{kind=link}

411 字节
{kind=link}
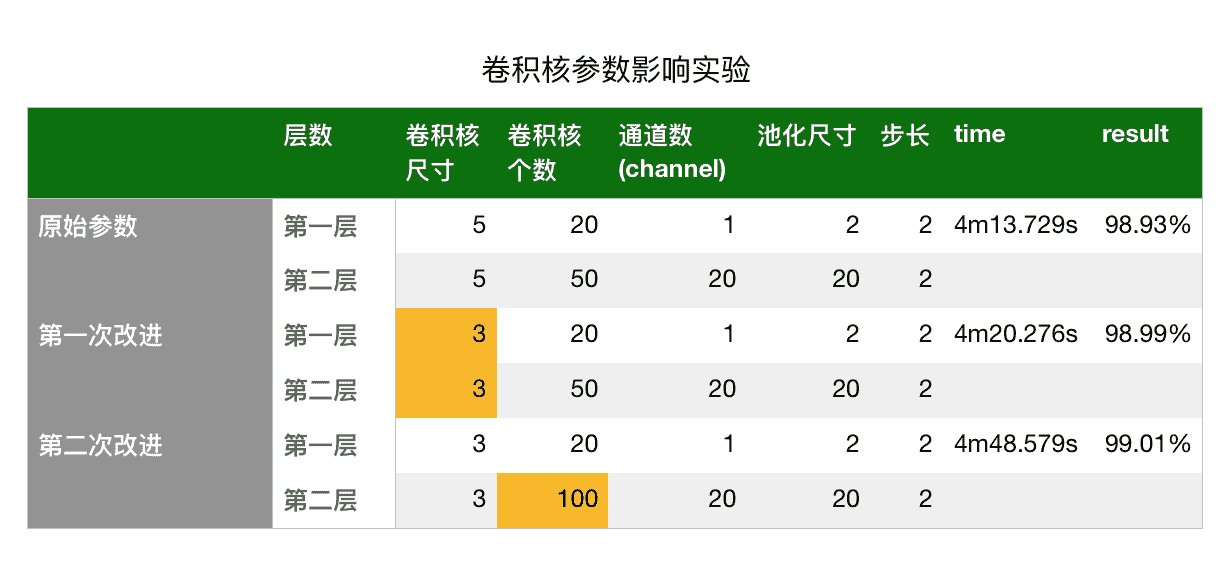
15.6 KB
{kind=link}

1.0 KB
{kind=link}
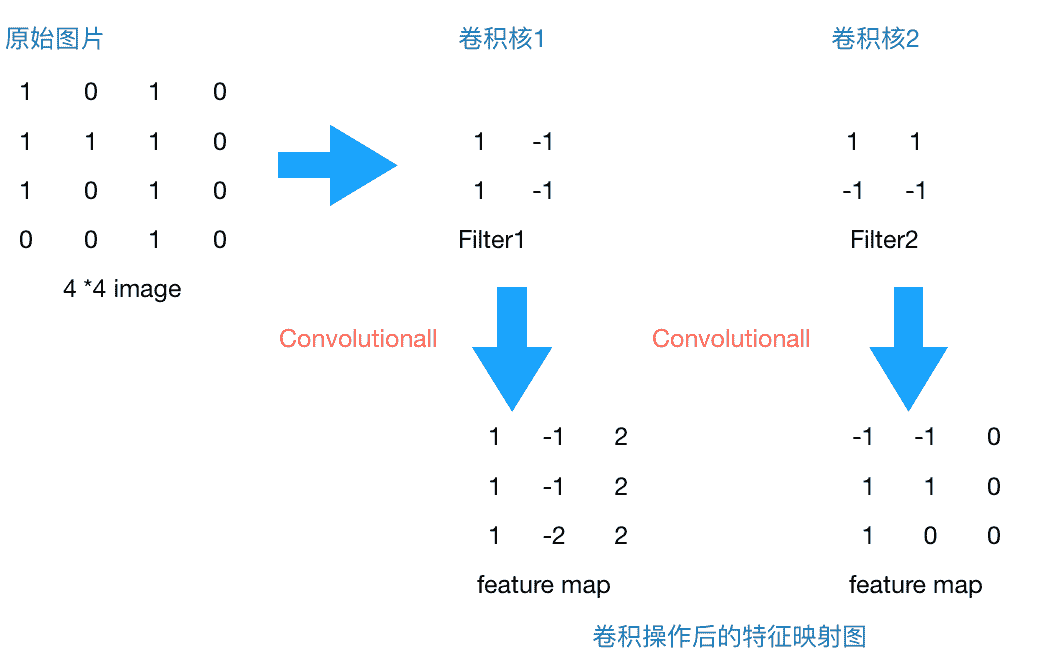
8.0 KB
{kind=link}
6.3 KB
{kind=link}
7.2 KB
{kind=link}
12.3 KB
{kind=link}
8.9 KB
{kind=link}
1.0 KB
{kind=link}
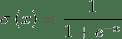
423 字节
{kind=link}
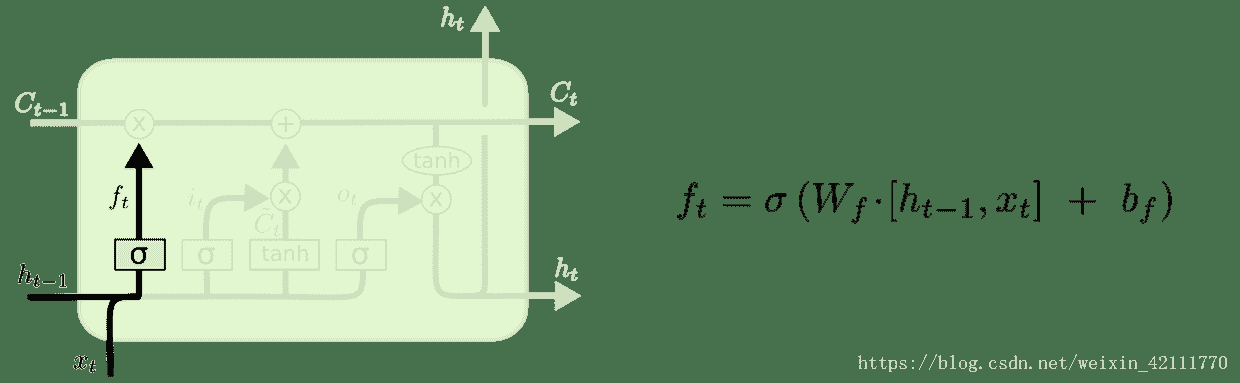
8.3 KB
{kind=link}
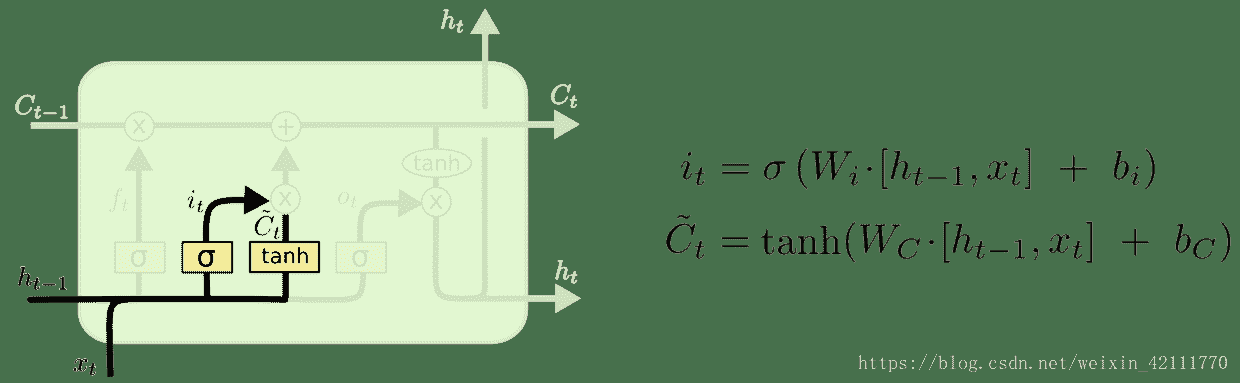
11.1 KB
{kind=link}
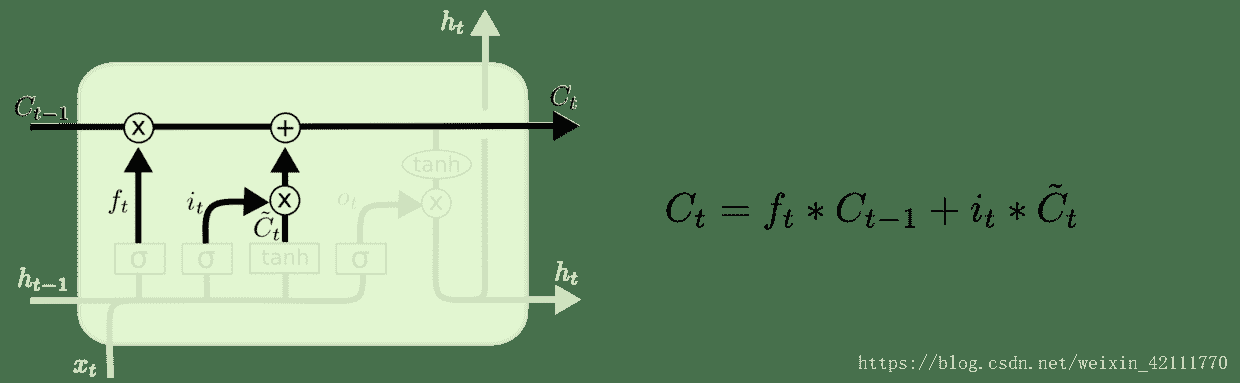
8.2 KB
{kind=link}
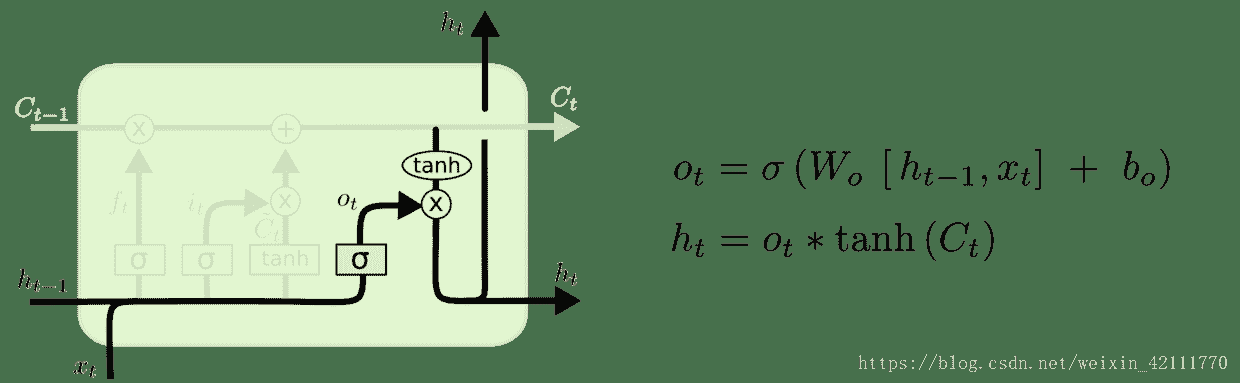
10.2 KB
{kind=link}
238 字节
{kind=link}
194 字节
{kind=link}
207 字节
{kind=link}
207 字节
{kind=link}
191 字节
{kind=link}
232 字节
{kind=link}
232 字节
{kind=link}
191 字节
{kind=link}

309 字节
{kind=link}
232 字节
{kind=link}
207 字节
{kind=link}
245 字节
{kind=link}
309 字节
{kind=link}
218 字节
{kind=link}
191 字节
{kind=link}
218 字节
{kind=link}
191 字节
{kind=link}
205 字节
{kind=link}
13.5 KB
{kind=link}
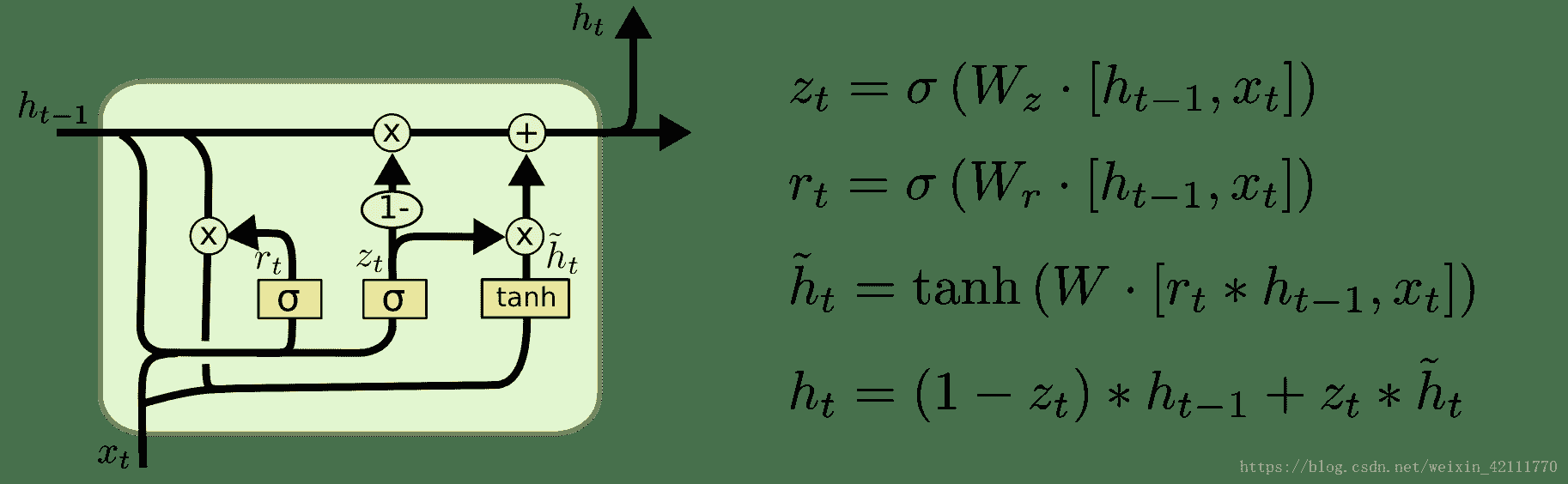
19.6 KB
{kind=link}
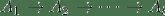
434 字节
{kind=link}
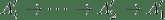
465 字节
{kind=link}

268 字节
{kind=link}
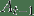
241 字节
{kind=link}
194 字节
{kind=link}
194 字节
{kind=link}
268 字节
{kind=link}
188 字节
{kind=link}
190 字节
{kind=link}
220 字节
{kind=link}
238 字节
{kind=link}
238 字节
{kind=link}
766 字节
{kind=link}
554 字节
{kind=link}
379 字节
{kind=link}

3.5 KB
{kind=link}
1.4 KB
{kind=link}
1.2 KB
{kind=link}
283 字节
{kind=link}
6.7 KB
{kind=link}
748 字节
{kind=link}
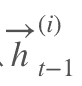
800 字节
{kind=link}
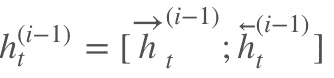
2.7 KB
{kind=link}
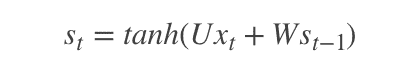
1.3 KB
{kind=link}
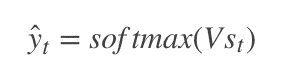
1.2 KB
{kind=link}
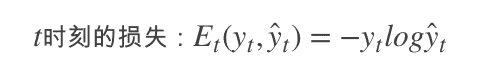
2.0 KB
{kind=link}
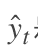
348 字节
{kind=link}
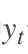
379 字节
{kind=link}
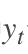
296 字节
{kind=link}
3.4 KB
{kind=link}
385 字节
{kind=link}
1.5 KB
{kind=link}
2.1 KB
{kind=link}
1.3 KB
{kind=link}
1.6 KB
{kind=link}
1.9 KB
{kind=link}
18.6 KB
{kind=link}
11.9 KB
{kind=link}
42.5 KB
{kind=link}
8.0 KB
{kind=link}
8.8 KB
{kind=link}

5.0 KB
{kind=link}
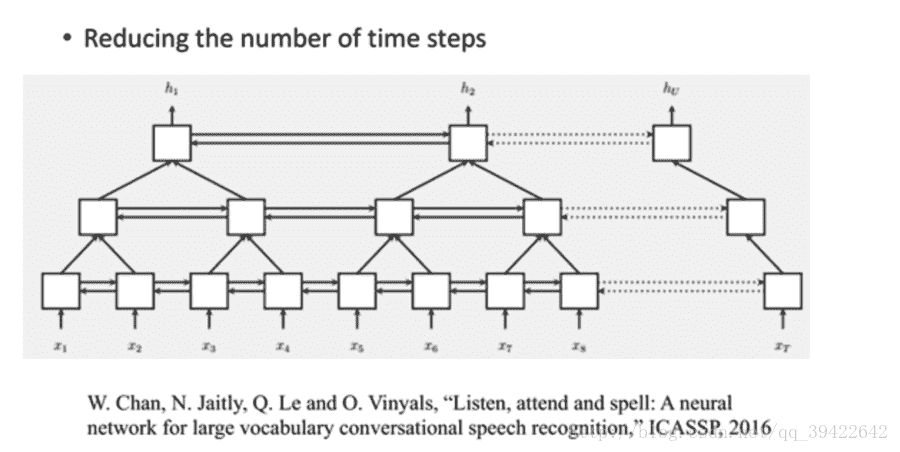
21.7 KB
{kind=link}
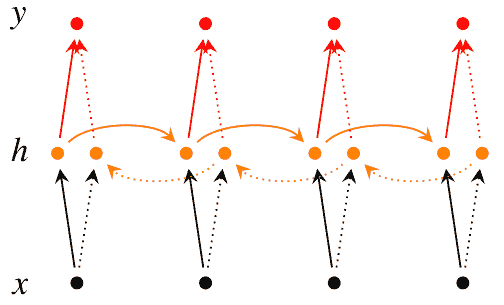
4.4 KB
{kind=link}
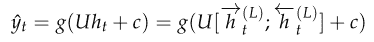
1.3 KB
{kind=link}
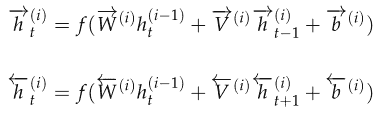
3.0 KB
{kind=link}
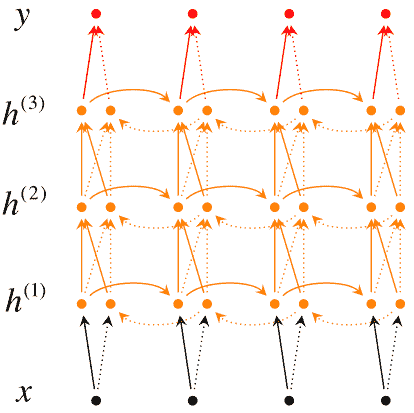
8.6 KB
{kind=link}
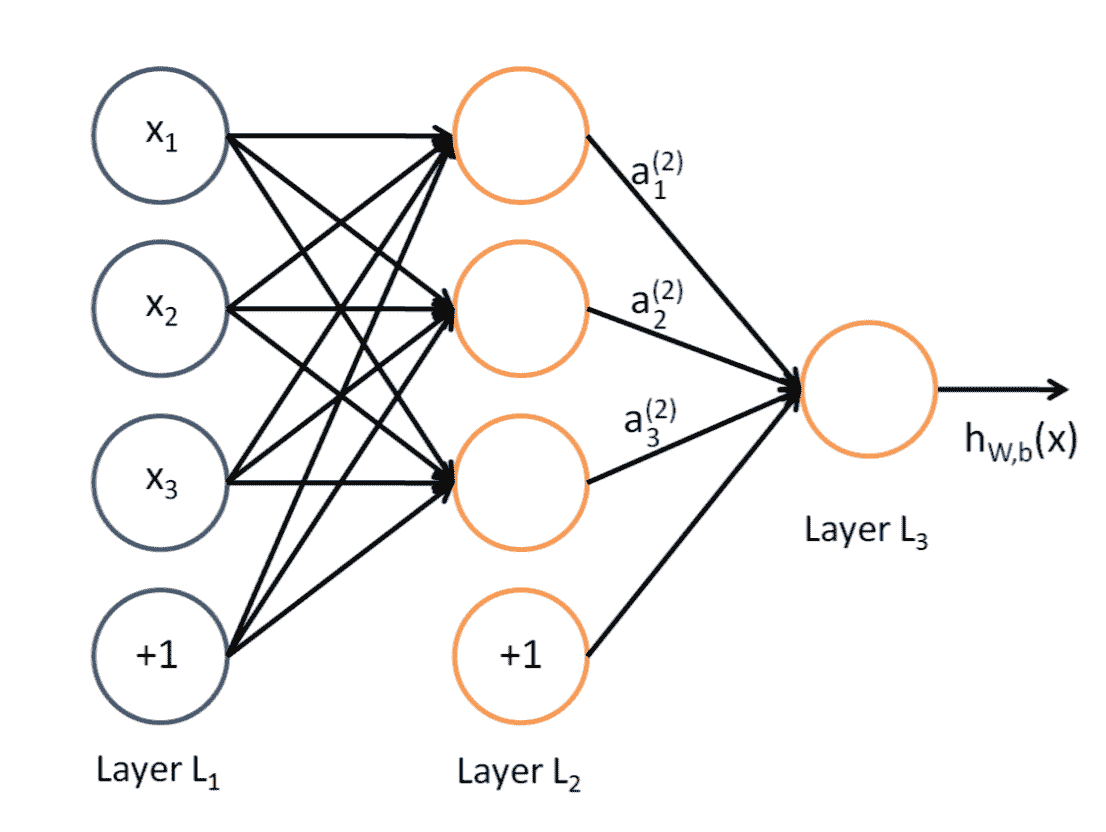
23.4 KB
{kind=link}
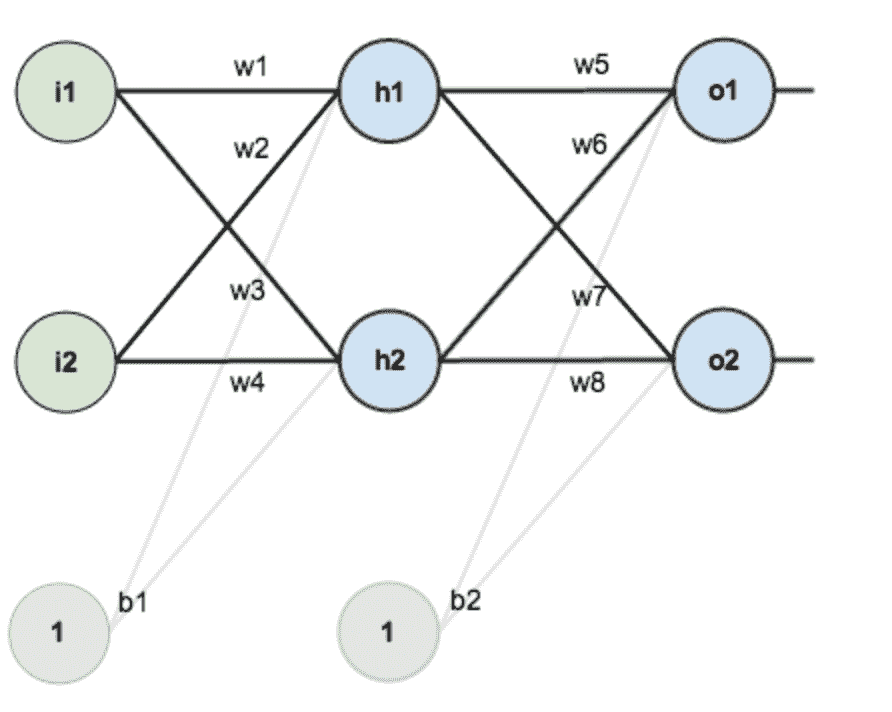
19.3 KB
{kind=link}
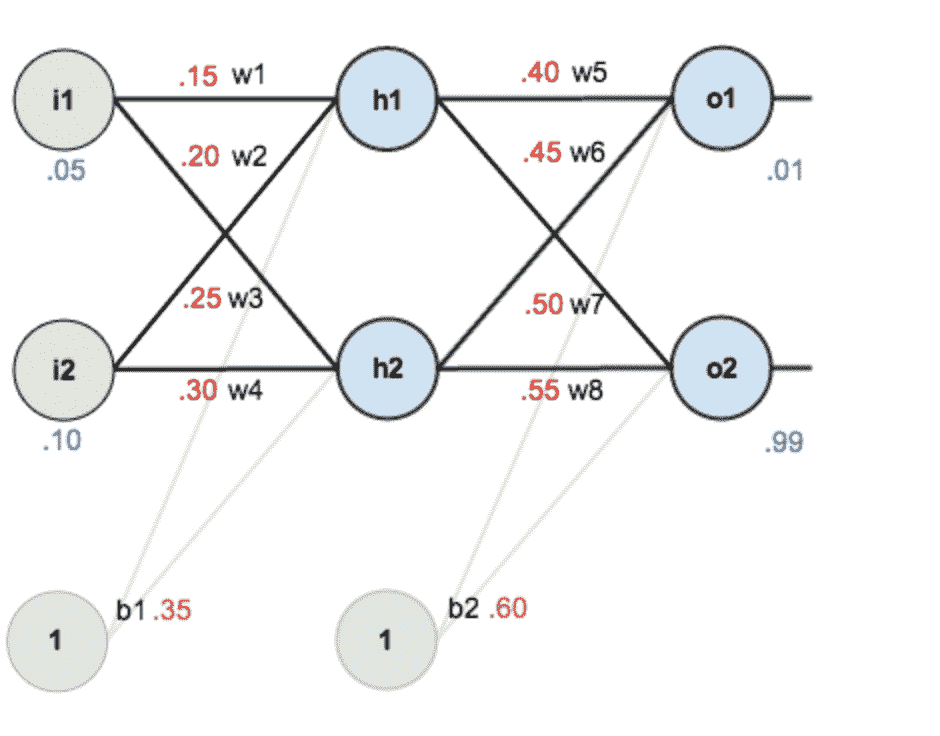
21.1 KB
{kind=link}
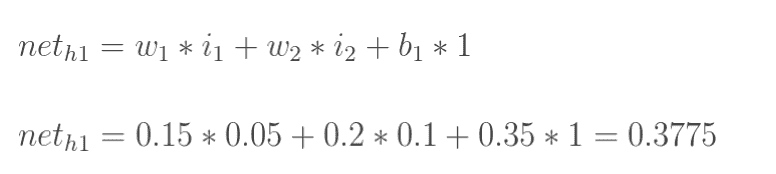
4.3 KB
{kind=link}
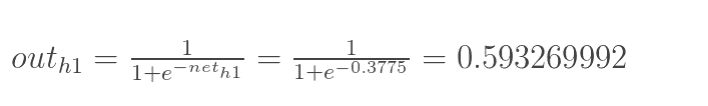
2.2 KB
{kind=link}
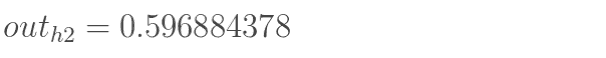
1.6 KB
{kind=link}

8.4 KB
{kind=link}
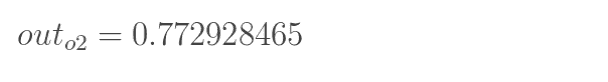
1.5 KB
{kind=link}
2.0 KB
{kind=link}
4.2 KB
{kind=link}

1.5 KB
{kind=link}
3.9 KB
{kind=link}
4.4 KB
{kind=link}
14.5 KB
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。