Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
OpenDocCN
Ailearning
提交
be9532d2
A
Ailearning
项目概览
OpenDocCN
/
Ailearning
大约 1 年 前同步成功
通知
12
Star
36240
Fork
11272
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
DevOps
流水线
流水线任务
计划
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
A
Ailearning
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
DevOps
DevOps
流水线
流水线任务
计划
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
流水线任务
提交
Issue看板
体验新版 GitCode,发现更多精彩内容 >>
未验证
提交
be9532d2
编写于
12月 11, 2019
作者:
片刻小哥哥
提交者:
GitHub
12月 11, 2019
浏览文件
操作
浏览文件
下载
差异文件
Merge pull request #562 from jiangzhonglian/master
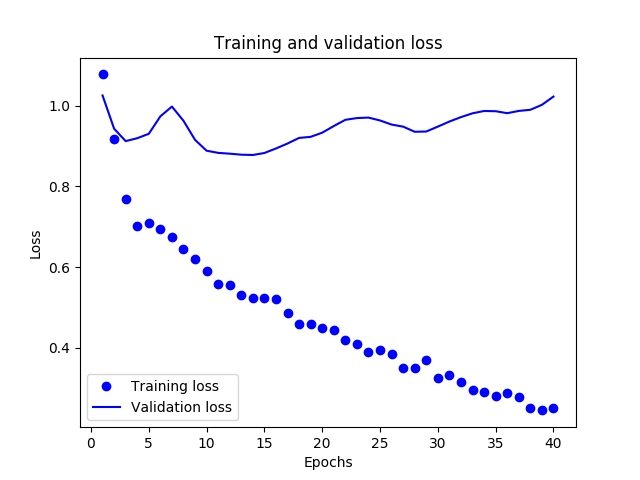
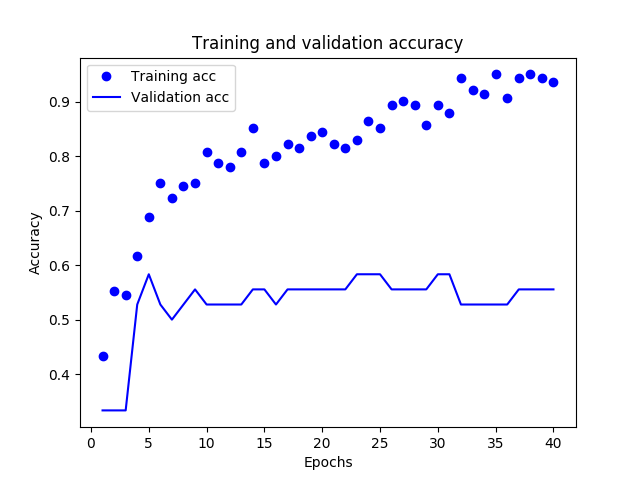
添加注释,画 loss 和 accuracy 相关图
上级
3671e656
c2dee93b
变更
4
隐藏空白更改
内联
并排
Showing
4 changed file
with
41 addition
and
4 deletion
+41
-4
src/py3.x/tensorflow2.x/Emotion_acc.png
src/py3.x/tensorflow2.x/Emotion_acc.png
+0
-0
src/py3.x/tensorflow2.x/Emotion_loss.png
src/py3.x/tensorflow2.x/Emotion_loss.png
+0
-0
src/py3.x/tensorflow2.x/config.py
src/py3.x/tensorflow2.x/config.py
+1
-1
src/py3.x/tensorflow2.x/text_Emotion.py
src/py3.x/tensorflow2.x/text_Emotion.py
+40
-3
未找到文件。
src/py3.x/tensorflow2.x/Emotion_acc.png
0 → 100644
浏览文件 @
be9532d2
25.9 KB
src/py3.x/tensorflow2.x/Emotion_loss.png
0 → 100644
浏览文件 @
be9532d2
24.5 KB
src/py3.x/tensorflow2.x/config.py
浏览文件 @
be9532d2
...
...
@@ -15,7 +15,7 @@ class Config(object):
# 根据前六个字预测第七个字
max_len
=
6
batch_size
=
512
learning_rate
=
0.00
1
learning_rate
=
0.00
05
pre_num
=
3
MAX_SEQUENCE_LENGTH
=
1000
# 每个文本或者句子的截断长度,只保留1000个单词
EMBEDDING_DIM
=
60
# 词向量维度
src/py3.x/tensorflow2.x/text_Emotion.py
浏览文件 @
be9532d2
...
...
@@ -25,6 +25,7 @@ from keras.utils.np_utils import to_categorical
from
keras.optimizers
import
Adam
from
config
import
Config
import
pickle
import
matplotlib.pyplot
as
plt
# 存储模型: 持久化
...
...
@@ -84,6 +85,37 @@ def load_embeding():
return
vocab_list
,
word_index
,
embeddings_matrix
def
plot_history
(
history
):
history_dict
=
history
.
history
print
(
history_dict
.
keys
())
acc
=
history_dict
[
'accuracy'
]
val_acc
=
history_dict
[
'val_accuracy'
]
loss
=
history_dict
[
'loss'
]
val_loss
=
history_dict
[
'val_loss'
]
epochs
=
range
(
1
,
len
(
acc
)
+
1
)
# “bo”代表 "蓝点"
plt
.
plot
(
epochs
,
loss
,
'bo'
,
label
=
'Training loss'
)
# b代表“蓝色实线”
plt
.
plot
(
epochs
,
val_loss
,
'b'
,
label
=
'Validation loss'
)
plt
.
title
(
'Training and validation loss'
)
plt
.
xlabel
(
'Epochs'
)
plt
.
ylabel
(
'Loss'
)
plt
.
legend
()
plt
.
savefig
(
'Emotion_loss.png'
)
# plt.show()
plt
.
clf
()
# 清除数字
plt
.
plot
(
epochs
,
acc
,
'bo'
,
label
=
'Training acc'
)
plt
.
plot
(
epochs
,
val_acc
,
'b'
,
label
=
'Validation acc'
)
plt
.
title
(
'Training and validation accuracy'
)
plt
.
xlabel
(
'Epochs'
)
plt
.
ylabel
(
'Accuracy'
)
plt
.
legend
()
plt
.
savefig
(
'Emotion_acc.png'
)
# plt.show()
class
EmotionModel
(
object
):
def
__init__
(
self
,
config
):
self
.
model
=
None
...
...
@@ -118,7 +150,6 @@ class EmotionModel(object):
# output_dim = EMBEDDING_DIM, # 设置词向量的维度
# input_length=MAX_SEQUENCE_LENGTH
# ) #设置句子的最大长度
print
(
"开始训练模型....."
)
sequence_input
=
Input
(
shape
=
(
self
.
MAX_SEQUENCE_LENGTH
,),
dtype
=
'int32'
)
# 返回一个张量,长度为1000,也就是模型的输入为batch_size*1000
embedded_sequences
=
embedding_layer
(
sequence_input
)
# 返回batch_size*1000*100
...
...
@@ -132,13 +163,14 @@ class EmotionModel(object):
preds
=
Dense
(
self
.
pre_num
,
activation
=
'softmax'
)(
x
)
self
.
model
=
Model
(
sequence_input
,
preds
)
# 设置优化器
optimizer
=
Adam
(
lr
=
self
.
config
.
learning_rate
)
optimizer
=
Adam
(
lr
=
self
.
config
.
learning_rate
,
beta_1
=
0.95
,
beta_2
=
0.999
,
epsilon
=
1e-08
)
self
.
model
.
compile
(
optimizer
=
optimizer
,
loss
=
'categorical_crossentropy'
,
metrics
=
[
'accuracy'
])
self
.
model
.
summary
()
def
load_word2jieba
(
self
):
vocab_list
=
load_pkl
(
self
.
vocab_list
)
if
vocab_list
!=
[]:
print
(
"加载词的总量: "
,
len
(
vocab_list
))
for
word
in
vocab_list
:
jieba
.
add_word
(
word
)
...
...
@@ -194,7 +226,12 @@ class EmotionModel(object):
print
(
x_test
[:
3
],
"
\n
"
,
y_test
[:
3
])
print
(
"---------"
)
self
.
build_model
(
embeddings_matrix
)
self
.
model
.
fit
(
x_train
,
y_train
,
batch_size
=
60
,
epochs
=
10
)
# 画相关的 loss 和 accuracy=(预测正确-正or负/总预测的)
history
=
self
.
model
.
fit
(
x_train
,
y_train
,
batch_size
=
60
,
epochs
=
40
,
validation_split
=
0.2
,
verbose
=
0
)
plot_history
(
history
)
# self.model.fit(x_train, y_train, batch_size=60, epochs=40)
self
.
model
.
evaluate
(
x_test
,
y_test
,
verbose
=
2
)
self
.
model
.
save
(
self
.
config
.
model_file
)
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录

{kind=link}
{kind=link}