
修复原来删除 nlp的内容,迁移到 docs/nlp_old 下面
Showing
docs/nlp_old/1.入门介绍.md
0 → 100644
docs/nlp_old/2.分词.md
0 → 100644
此差异已折叠。
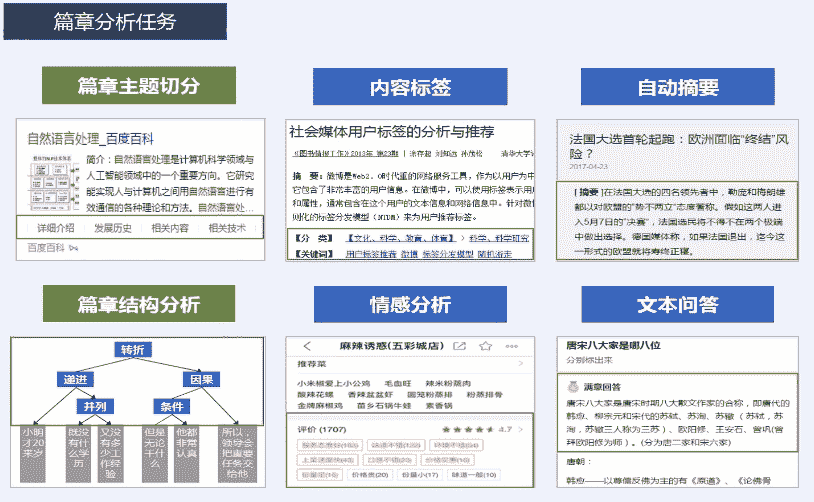
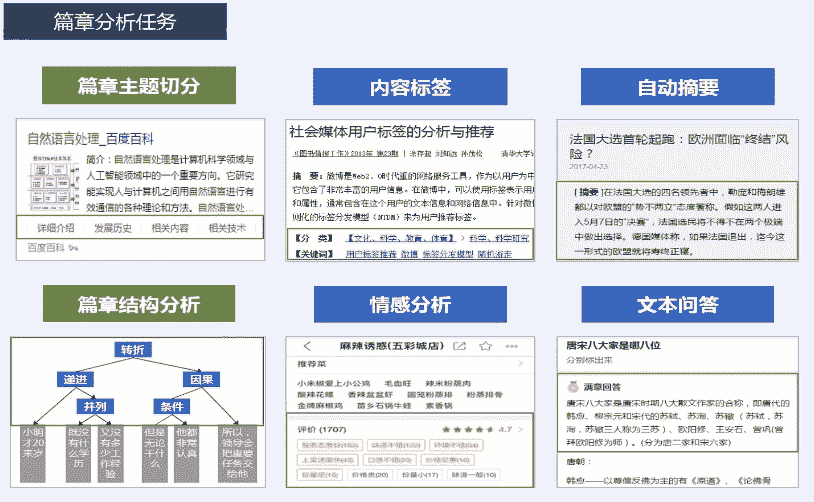
docs/nlp_old/3.1.篇章分析-内容概述.md
0 → 100644
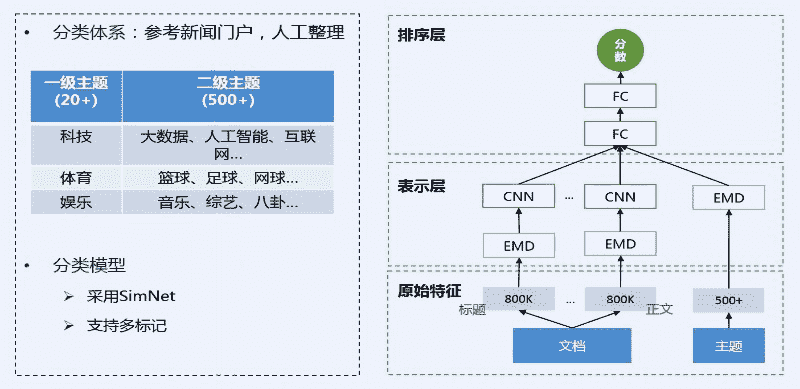
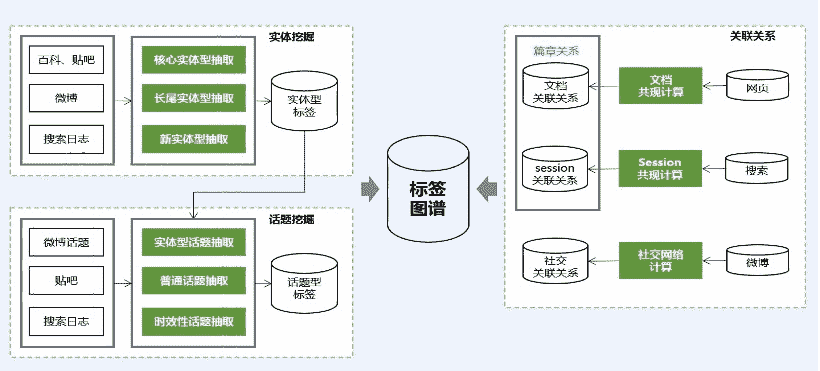
docs/nlp_old/3.2.篇章分析-内容标签.md
0 → 100644
docs/nlp_old/3.3.篇章分析-情感分析.md
0 → 100644
docs/nlp_old/3.4.篇章分析-自动摘要.md
0 → 100644
docs/nlp_old/3.命名实体识别.md
0 → 100644
docs/nlp_old/README.md
0 → 100644
docs/nlp_old/Word2Vec.md
0 → 100644
{kind=link}

67.7 KB
{kind=link}
36.3 KB
{kind=link}
36.3 KB
{kind=link}
29.6 KB
{kind=link}

31.4 KB
{kind=link}
17.8 KB
{kind=link}
24.8 KB
{kind=link}

15.3 KB
{kind=link}
12.7 KB
{kind=link}
14.6 KB
{kind=link}

12.9 KB
{kind=link}
21.6 KB
{kind=link}
30.1 KB
{kind=link}
20.3 KB
{kind=link}
17.3 KB
{kind=link}

21.7 KB
{kind=link}
17.3 KB
{kind=link}
24.7 KB
{kind=link}

32.2 KB
{kind=link}
8.3 KB
{kind=link}
29.2 KB
{kind=link}
29.7 KB
{kind=link}
31.7 KB
{kind=link}
28.3 KB
{kind=link}

25.9 KB
{kind=link}
20.3 KB
{kind=link}
45.0 KB
{kind=link}
2.8 KB
{kind=link}
2.8 KB
文件已添加
文件已添加
文件已移动
tutorials/test.ipynb
0 → 100644