Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
OpenDocCN
Ailearning
提交
4609c0b2
A
Ailearning
项目概览
OpenDocCN
/
Ailearning
10 个月 前同步成功
通知
8
Star
36240
Fork
11272
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
DevOps
流水线
流水线任务
计划
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
A
Ailearning
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
DevOps
DevOps
流水线
流水线任务
计划
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
流水线任务
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
4609c0b2
编写于
5月 13, 2020
作者:
片刻小哥哥
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
更新链接信息
上级
5a311803
变更
6
隐藏空白更改
内联
并排
Showing
6 changed file
with
67 addition
and
63 deletion
+67
-63
docs/nlp/1.自然语言处理入门介绍.md
docs/nlp/1.自然语言处理入门介绍.md
+42
-38
docs/nlp/3.1.篇章分析-内容概述.md
docs/nlp/3.1.篇章分析-内容概述.md
+1
-1
docs/nlp/3.2.篇章分析-内容标签.md
docs/nlp/3.2.篇章分析-内容标签.md
+6
-6
docs/nlp/3.3.篇章分析-情感分析.md
docs/nlp/3.3.篇章分析-情感分析.md
+6
-6
docs/nlp/3.4.篇章分析-自动摘要.md
docs/nlp/3.4.篇章分析-自动摘要.md
+11
-11
docs/nlp/README.md
docs/nlp/README.md
+1
-1
未找到文件。
docs/nlp/1.自然语言处理入门介绍.md
浏览文件 @
4609c0b2
# 自然语言处理介绍
*
语言是知识和思维的载体
*
自然语言处理 (Natural Language Processing, NLP) 是计算机科学,人工智能,语言学关注计算机和人类
(自然)
语言之间的相互作用的领域。
*
自然语言处理 (Natural Language Processing, NLP) 是计算机科学,人工智能,语言学关注计算机和人类
(自然)
语言之间的相互作用的领域。
## NLP相关的技术
| 中文 | 英文 | 描述 |
| --- | --- | --- |
| 分词 | Word Segmentation | 将连续的自然语言文本,切分成具有语义合理性和完整性的词汇序列 |
| 命名实体识别 | Named Entity Recognition | 识别自然语言文本中具有特定意义的实体
(人、地、机构、时间、作品等)
|
| 词性标注 | Part-Speech Tagging | 为自然语言文本中的每个词汇赋予一个词性
(名词、动词、形容词等)
|
| 依存句法分析 | Dependency Parsing | 自动分析句子中的句法成分
(主语、谓语、宾语、定语、状语和补语等成分)
|
| 命名实体识别 | Named Entity Recognition | 识别自然语言文本中具有特定意义的实体
(人、地、机构、时间、作品等)
|
| 词性标注 | Part-Speech Tagging | 为自然语言文本中的每个词汇赋予一个词性
(名词、动词、形容词等)
|
| 依存句法分析 | Dependency Parsing | 自动分析句子中的句法成分
(主语、谓语、宾语、定语、状语和补语等成分)
|
| 词向量与语义相似度 | Word Embedding & Semantic Similarity | 依托全网海量数据和深度神经网络技术,实现了对词汇的向量化表示,并据此实现了词汇的语义相似度计算 |
| 文本语义相似度 | Text Semantic Similarity | 依托全网海量数据和深度神经网络技术,实现文本间的语义相似度计算的能力 |
| 篇章分析 | Document Analysis | 分析篇章级文本的内在结构,进而分析文本情感倾向,提取评论性观点,并生成反映文本关键信息的标签与摘要 |
...
...
@@ -18,66 +18,70 @@
## 场景案例
### 案例1
(解决交叉歧义)
### 案例1
(解决交叉歧义)
**分词
(Word Segmentation)**
:
将连续的自然语言文本,切分成具有语义合理性和完整性的词汇序列
**分词
(Word Segmentation)**
:
将连续的自然语言文本,切分成具有语义合理性和完整性的词汇序列
例句:致毕业和尚未毕业的同学。
例句: 致毕业和尚未毕业的同学。
分词:
分词:
1.
`致`
`毕业`
`和`
`尚未`
`毕业`
`的`
`同学`
2.
`致`
`毕业`
`和尚`
`未`
`毕业`
`的`
`同学`
推荐:
推荐:
1.
校友 和 老师 给 尚未 毕业 同学 的 一 封 信
2.
本科 未 毕业 可以 当 和尚 吗
### 案例2(从粒度整合未登录体词)
### 案例2(从粒度整合未登录体词)
**命名实体识别(Named Entity Recognition)**
: 识别自然语言文本中具有特定意义的实体(人、地、机构、时间、作品等)
例句: 天使爱美丽在线观看
**命名实体识别(Named Entity Recognition)**
:识别自然语言文本中具有特定意义的实体(人、地、机构、时间、作品等)
分词:
`天使`
`爱`
`美丽`
`在线`
`观看`
例句:天使爱美丽在线观看
实体: 天使爱美丽 -> 电影
分词:
`天使`
`爱`
`美丽`
`在线`
`观看`
推荐:
实体: 天使爱美丽 -> 电影
1.
网页: 天使爱美丽 土豆 高清视频
2.
网页: 在线直播爱美丽的天使
推荐:
1.
网页:天使爱美丽 土豆 高清视频
2.
网页:在线直播爱美丽的天使
### 案例3(结构歧义问题)
### 案例3(结构歧义问题)
*
**词性标注(Part-Speech Tagging)**
: 为自然语言文本中的每个词汇赋予一个词性(名词、动词、形容词等)
*
**依存句法分析(Dependency Parsing)**
: 自动分析句子中的句法成分(主语、谓语、宾语、定语、状语和补语等成分)
**词性标注(Part-Speech Tagging)**
: 为自然语言文本中的每个词汇赋予一个词性(名词、动词、形容词等)
**依存句法分析(Dependency Parsing)**
:自动分析句子中的句法成分(主语、谓语、宾语、定语、状语和补语等成分)
评论: 房间里还可以欣赏日出
评论:房间里还可以欣赏日出
歧义:
歧义:
1.
房间还可以
2.
可以欣赏日出
词性:(???)
房间里:
主语
还可以:
谓语
欣赏日出:
动宾短语
*
词性: (???)
*
房间里:
主语
*
还可以:
谓语
*
欣赏日出:
动宾短语
### 案例4
(词汇语言相似度)
### 案例4
(词汇语言相似度)
**词向量与语义相似度
(Word Embedding & Semantic Similarity)**
:
对词汇进行向量化表示,并据此实现词汇的语义相似度计算。
**词向量与语义相似度
(Word Embedding & Semantic Similarity)**
:
对词汇进行向量化表示,并据此实现词汇的语义相似度计算。
例如
:西瓜 与 (呆瓜/草莓)
,哪个更接近?
例如
: 西瓜 与 (呆瓜/草莓)
,哪个更接近?
向量化表示:
西瓜(0.1222, 0.22333, .. )
相似度计算: 呆瓜(0.115) 草莓(0.325)
向量化表示:(-0.333, 0.1223 .. )
(0.333, 0.3333, .. )
*
向量化表示:
西瓜(0.1222, 0.22333, .. )
*
相似度计算: 呆瓜(0.115) 草莓(0.325)
*
向量化表示: (-0.333, 0.1223 .. )
(0.333, 0.3333, .. )
### 案例5
(文本语义相似度)
### 案例5
(文本语义相似度)
**文本语义相似度
(Text Semantic Similarity)**
:
依托全网海量数据和深度神经网络技术,实现文本间的语义相似度计算的能力
**文本语义相似度
(Text Semantic Similarity)**
:
依托全网海量数据和深度神经网络技术,实现文本间的语义相似度计算的能力
例如
:车头如何防止车牌 与 (前牌照怎么装/如何办理北京牌照)
,哪个更接近?
例如
: 车头如何防止车牌 与 (前牌照怎么装/如何办理北京牌照)
,哪个更接近?
向量化表示:
车头如何防止车牌(0.1222, 0.22333, .. )
相似度计算: 前牌照怎么装(0.762) 如何办理北京牌照(0.486)
向量化表示: (-0.333, 0.1223 .. )
(0.333, 0.3333, .. )
*
向量化表示:
车头如何防止车牌(0.1222, 0.22333, .. )
*
相似度计算: 前牌照怎么装(0.762) 如何办理北京牌照(0.486)
*
向量化表示: (-0.333, 0.1223 .. )
(0.333, 0.3333, .. )
docs/nlp/3.1.篇章分析-内容概述.md
浏览文件 @
4609c0b2
...
...
@@ -27,4 +27,4 @@
## 篇章分析任务
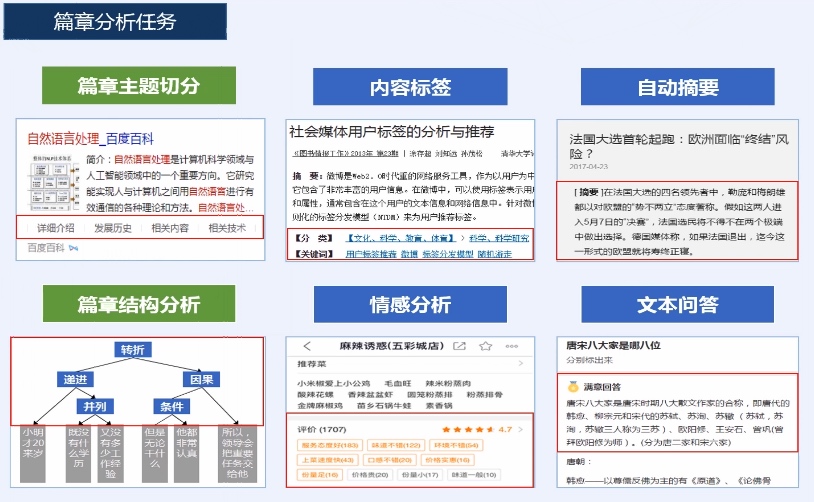
docs/nlp/3.2.篇章分析-内容标签.md
浏览文件 @
4609c0b2
...
...
@@ -30,7 +30,7 @@
## 百度内容标签
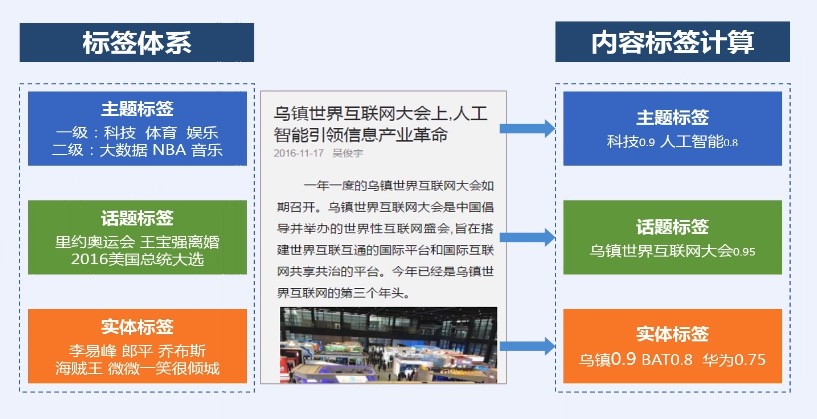
## 标签体系:面向推荐的标签图谱
...
...
@@ -39,14 +39,14 @@
*
包括3种节点:主题标签-绿色,话题标签-紫色,实体标签-蓝色。
*
有了关联关系,我们可以进行一定程度的探索和泛化。(例如:无人驾驶和人工智能关联很强,如果有人看了无人驾驶,我们就给他推荐人工智能)
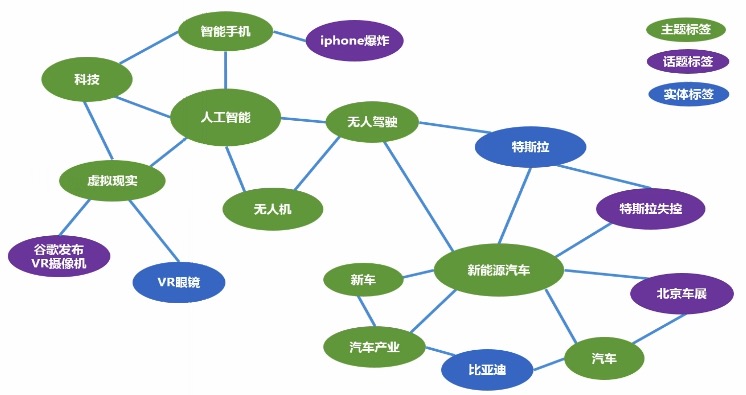
## 标签体系:基于大数据分析的图谱构建
*
用户信息来源:贴吧、微博
*
标签的相关性分析:通过关联规则,发现2个标签总同时出现,我们觉得这是高相关的。
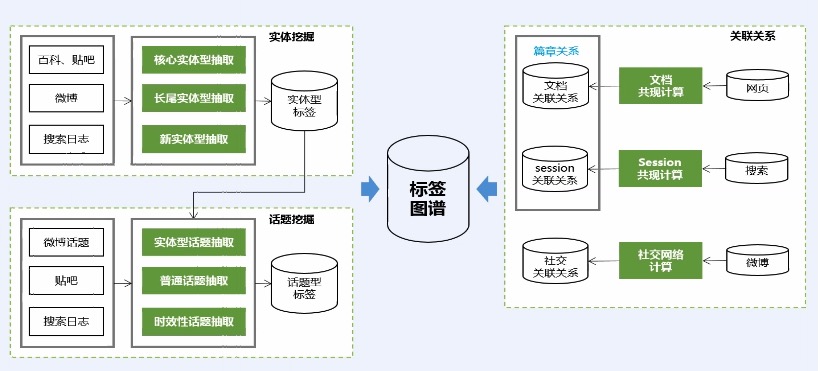
## 标签计算
...
...
@@ -59,7 +59,7 @@
*
第二层 表示层:通过一些 embedding的算法、CNN、LSTM的方法
*
第三层 排序层:计算文章与主题之间的相似度,具体会计算每个主题与文章的相似度,并将相似度作为最终的一个主题分类的结果。这种计算的好处能够天然的支持多标记,也就是一篇文章可以同时计算出多个主题标签。
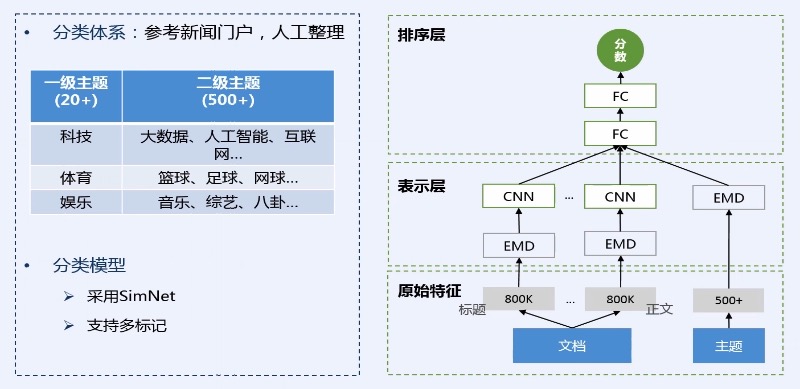
> 通用标签
...
...
@@ -72,11 +72,11 @@
*
比如:这个标签在文章中出现的频率 或 出现的位置;如果出现在标题,那么它可能就会比较重要。
*
通过融合这2种策略,形成我们通用标签的结果。
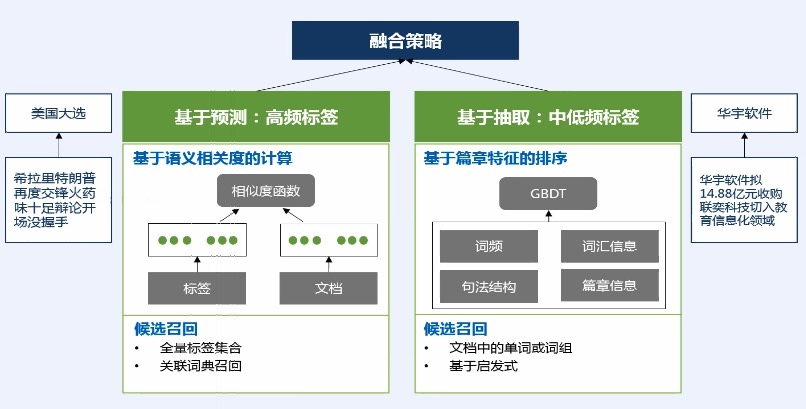
## 内容标签在Feed流中的应用
1.
标签可以用来话题聚合:比如表示人工智能的标签全部都会集合到同一个话题下面。这样用户可以对人工智能这个话题进行非常充分的浏览。
2.
话题频道划分:比如我们在手机百度上面就可以看到,Feed流上面有多个栏目,用户可以点击
`体育`
`时尚`
等频道
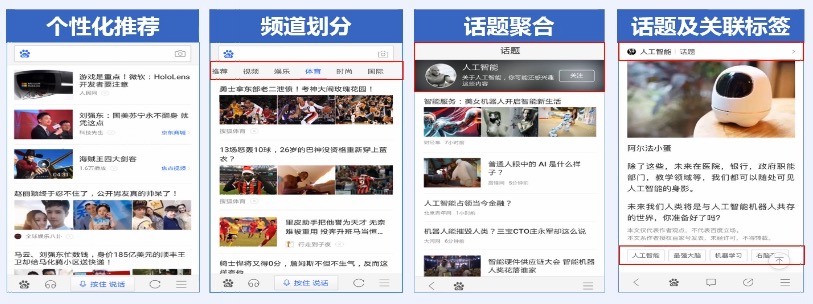
docs/nlp/3.3.篇章分析-情感分析.md
浏览文件 @
4609c0b2
...
...
@@ -12,14 +12,14 @@
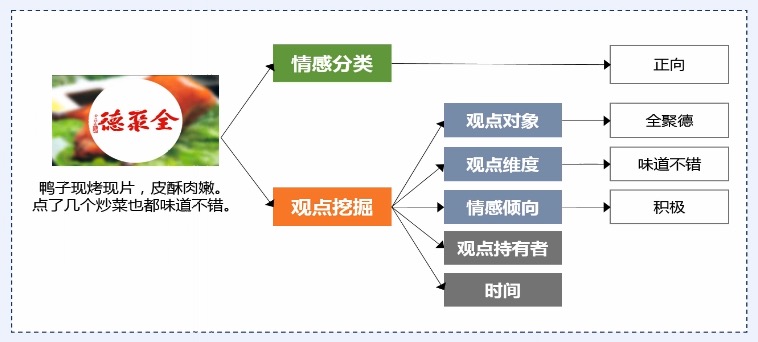
*
对(文本的)观点、情感、情绪和评论进行分析计算
> 情感分类
*
给定一个文本判断其情感的极性,包括积极、中性、消极。
*
LSTM 对文本进行语义表示,进而基于语义表示进行情感分类。
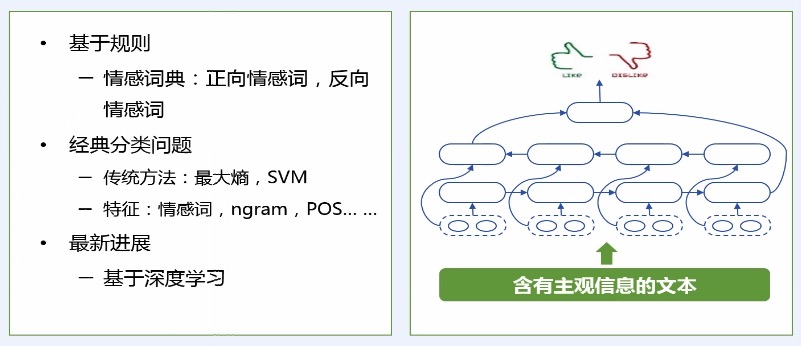
> 观点挖掘
...
...
@@ -28,18 +28,18 @@
*
观点抽取一种简单的做法是直接通过标签匹配的方式得到,比如:服务不错这个情感搭配,恰好在文本中出现,我们就可以把它抽取出来。
*
但是这种简单的抽取方法,其实上只能从字面上抽取情感搭配,而无法解决字面不一致的,但是意思一样的情感搭配抽取,因此我们还引入了语义相似度的方法。这种方法主要是通过神经网络进行计算的。它能解决这种字面不一致,语义一样的抽取问题。
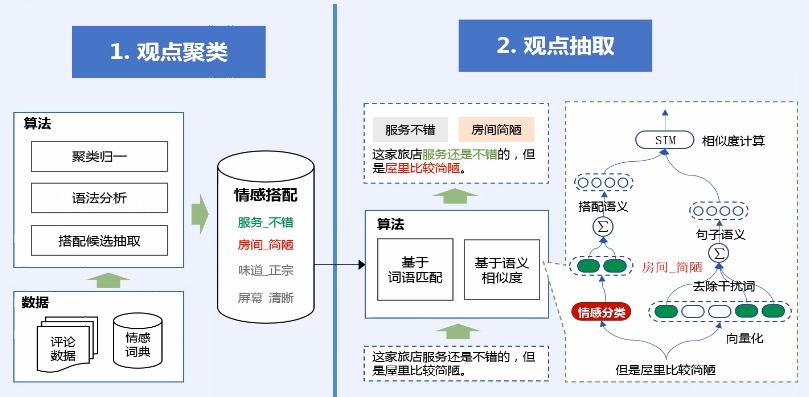
> 观点摘要
综合了情感分类和观点挖掘的一些技术,而获得的一个整体的应用技术
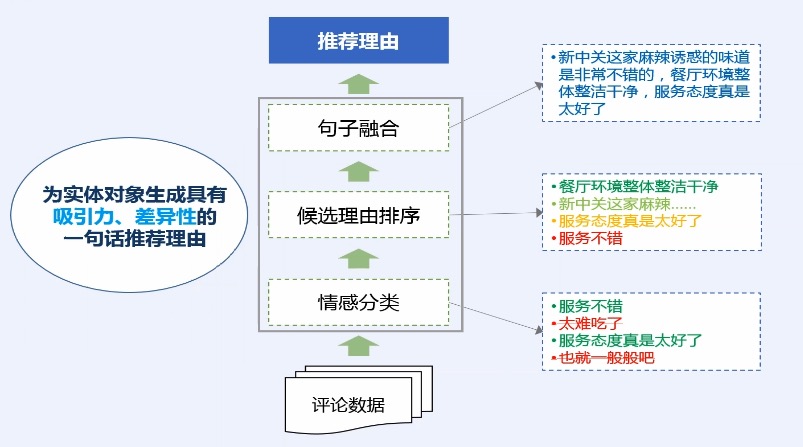
## 百度应用:评论观点
## 百度应用:推荐理由
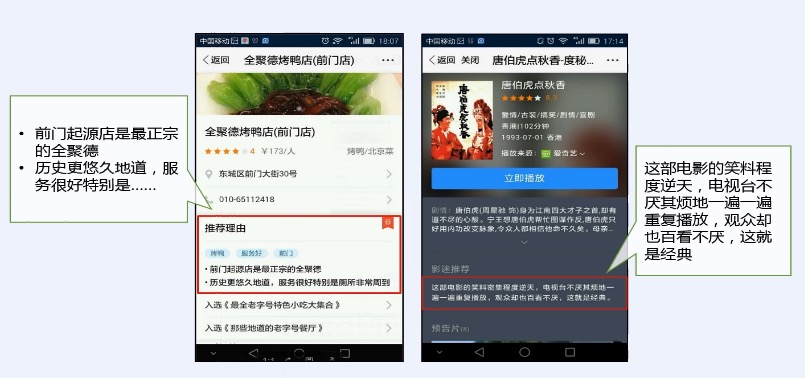
docs/nlp/3.4.篇章分析-自动摘要.md
浏览文件 @
4609c0b2
...
...
@@ -2,7 +2,7 @@
## 信息爆炸与移动化

## 自动摘要应用
...
...
@@ -21,42 +21,42 @@
*
以简洁、直观的摘要来概括用户所关注的主要内容
*
方便用户快速了解与浏览海量内容
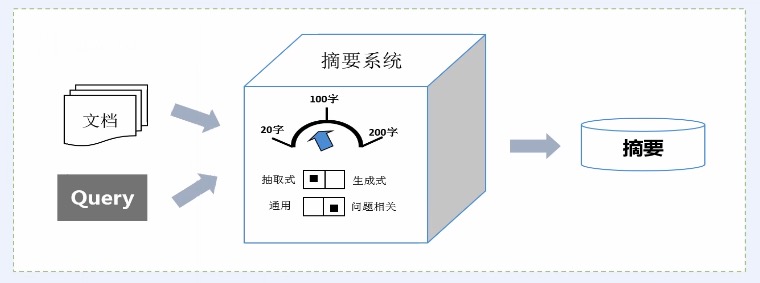
*
自动摘要分类

*
典型摘要计算流程
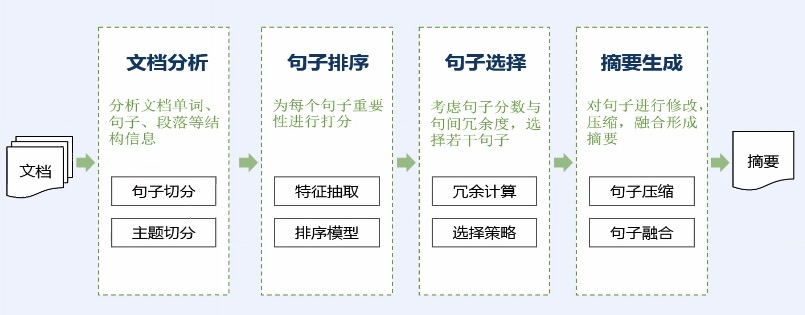
> 基于篇章信息的通用新闻摘要
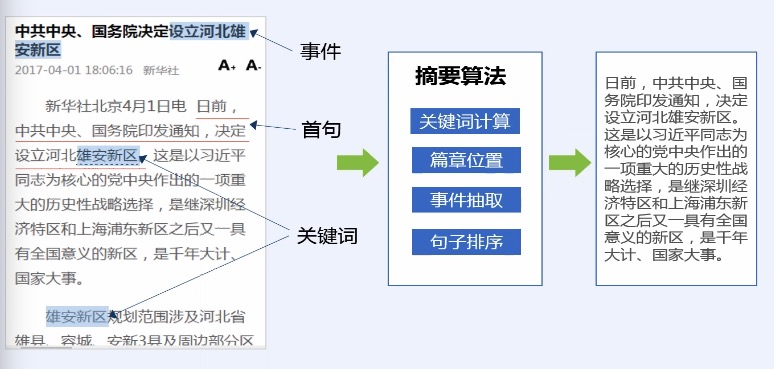
> 篇章主题摘要
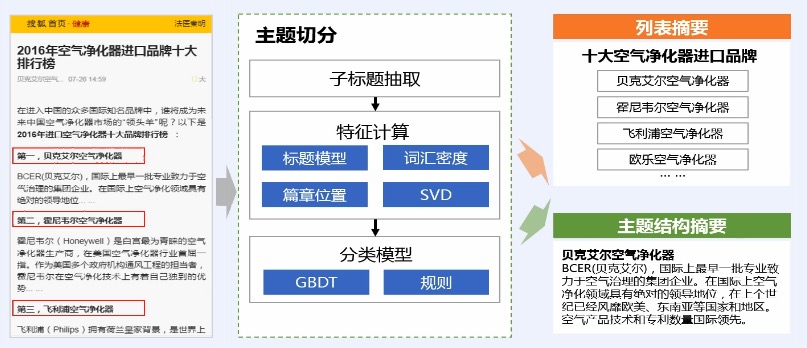
> 问答摘要
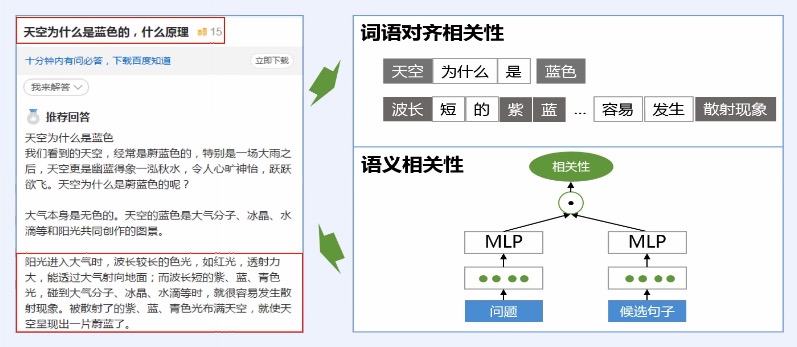
## 百度应用
> 文本和语言摘要
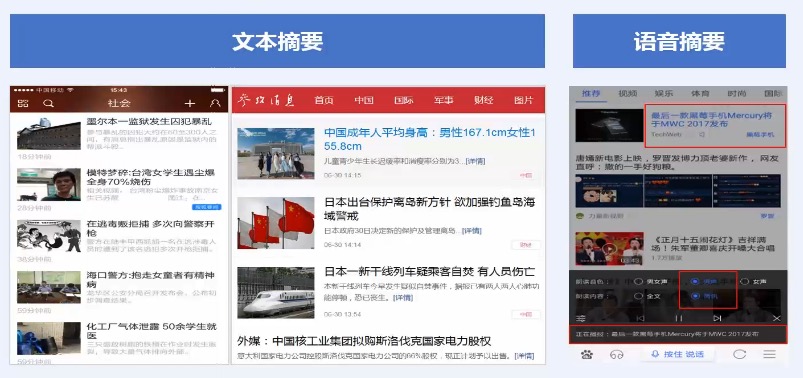
> 问答摘要
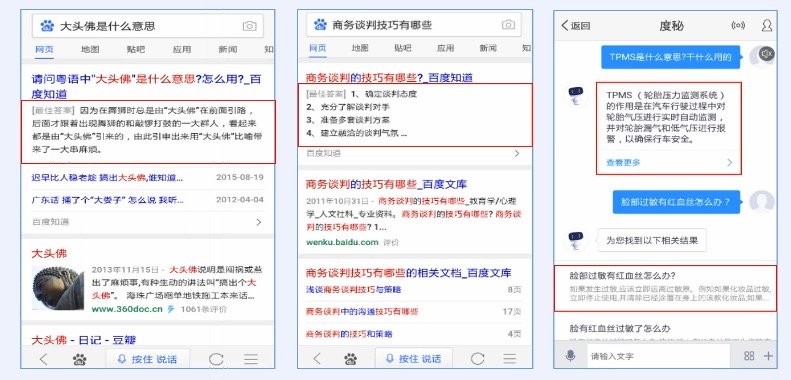
> 搜索播报摘要和图像摘要
## 总结

docs/nlp/README.md
浏览文件 @
4609c0b2
...
...
@@ -8,7 +8,7 @@
## nlp 学习书籍和工具:
*
百度搜索:Python自然语言处理
*
读书笔记:
https://wnma3mz.github.io/hexo_blog/2018/05/13/《Python自然语言处理》阅读笔记(一)
*
读书笔记:
<https://wnma3mz.github.io/hexo_blog/2018/05/13/《Python自然语言处理》阅读笔记(一)>
*
Python自然语言处理工具汇总:
<https://blog.csdn.net/sa14023053/article/details/51823122>
## nlp 全局介绍视频:(简单做了解就行)
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
