Auto Commit
Showing
.idea/.gitignore
0 → 100644
此差异已折叠。
.idea/misc.xml
0 → 100644
.idea/modules.xml
0 → 100644
.idea/test.iml
0 → 100644
__pycache__/model2.cpython-37.pyc
0 → 100644
文件已添加
datasets/evaluate/Evaluating.csv
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
datasets/train/Training.csv
0 → 100644
此差异已折叠。
model/1/140.png
0 → 100644
{kind=link}
81.6 KB
model/1/20.png
0 → 100644
{kind=link}
51.5 KB
model/1/2023-06-07_11_28_16.pth
0 → 100644
文件已添加
model/1/30.png
0 → 100644
{kind=link}
62.9 KB
model/1/320.png
0 → 100644
{kind=link}
100.6 KB
model/1/50.png
0 → 100644
{kind=link}
89.0 KB
model/1/500.png
0 → 100644
{kind=link}
48.6 KB
model/1/90.png
0 → 100644
{kind=link}
85.4 KB
{kind=link}
100.6 KB
model/2023-06-11_10_40_12.pth
0 → 100644
文件已添加
model/2023-06-11_10_50_15.pth
0 → 100644
文件已添加
model/2023-06-11_10_54_59.pth
0 → 100644
文件已添加
model/GRU/2023-06-10_10_55_23.pth
0 → 100644
文件已添加
{kind=link}
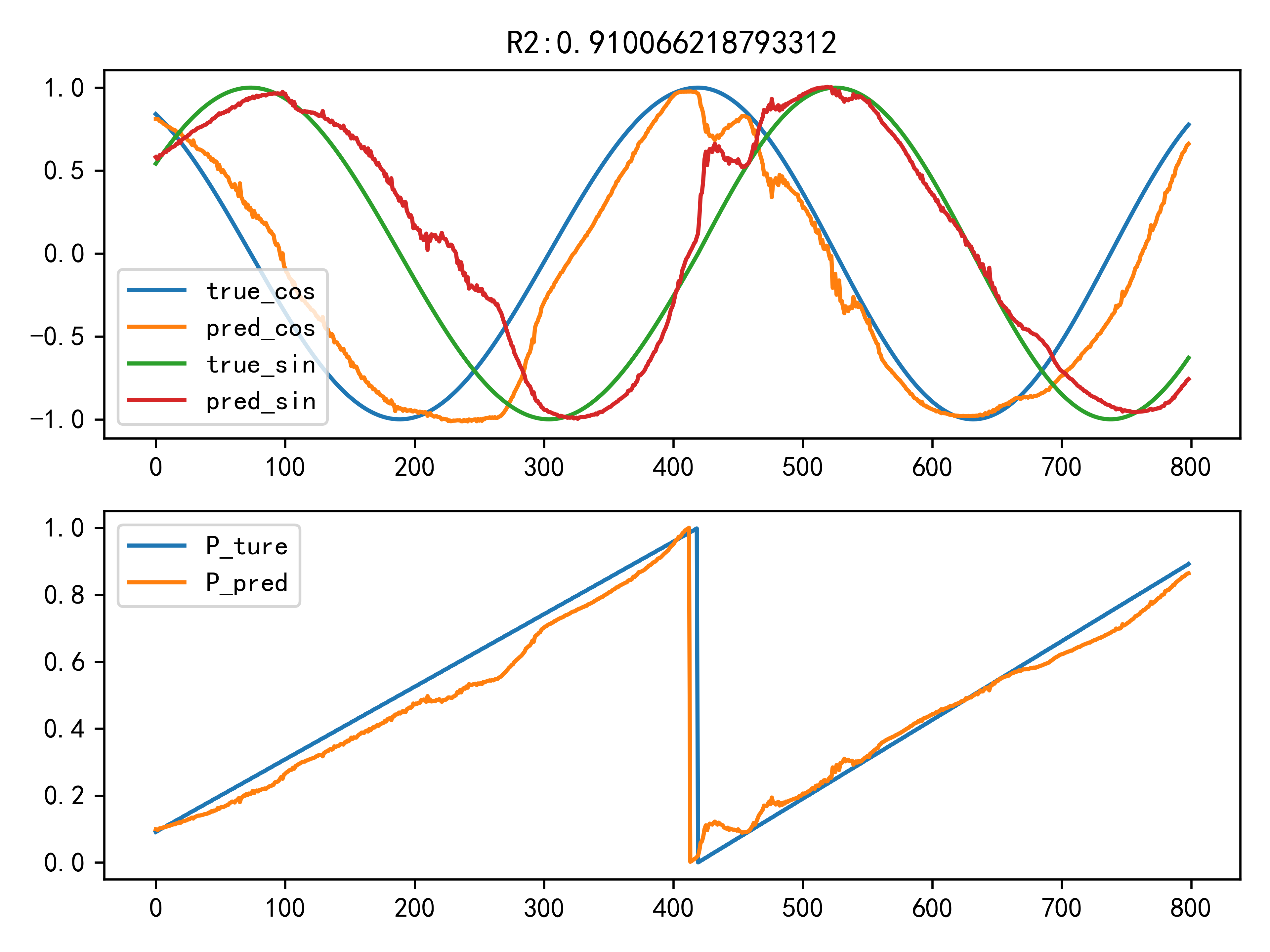
600.2 KB
model/GRU/新建 文本文档.txt
0 → 100644
文件已添加
{kind=link}
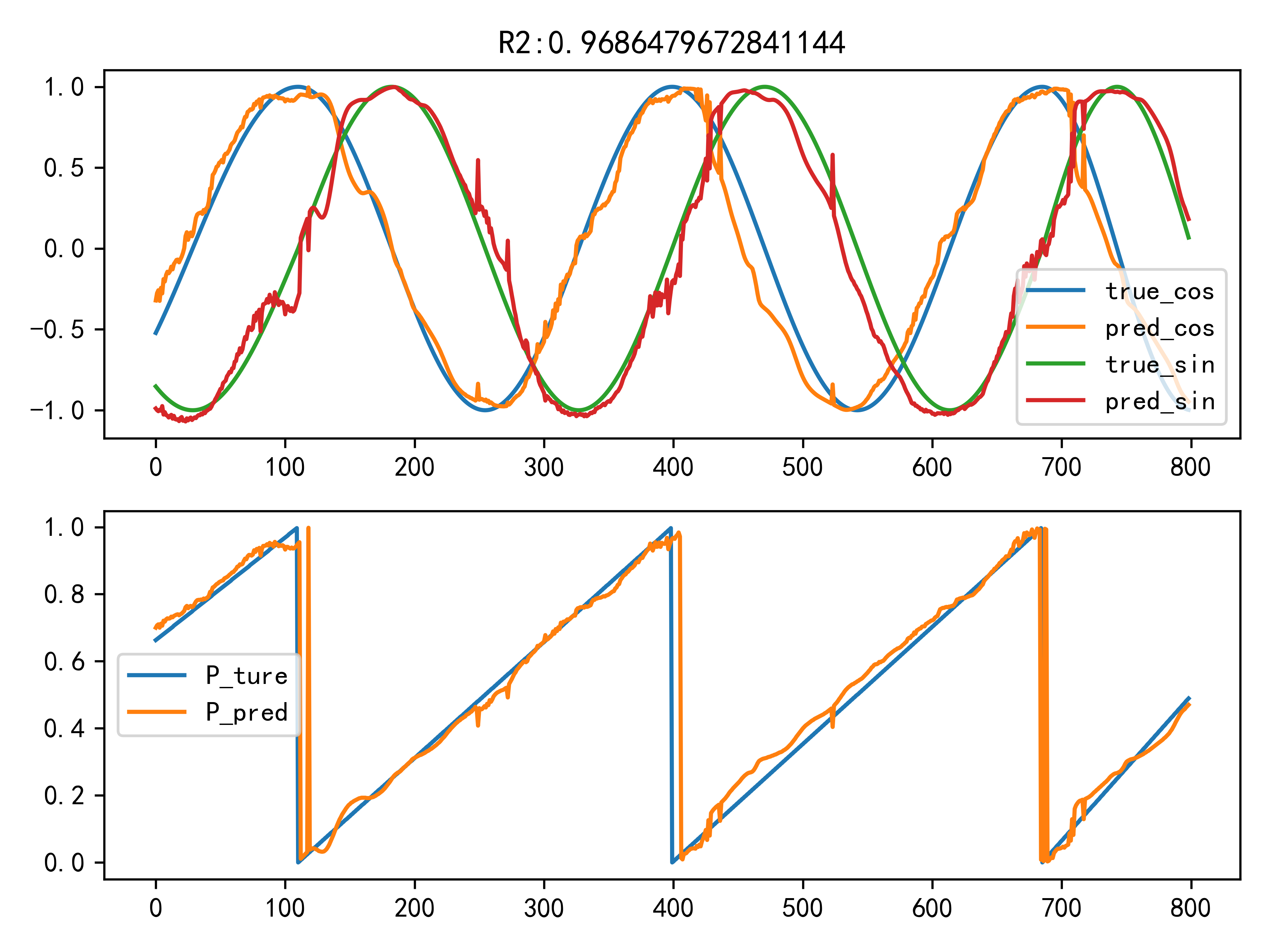
674.8 KB
model/LSTM/新建 文本文档.txt
0 → 100644
model/LSTM/训练图.png
0 → 100644
{kind=link}
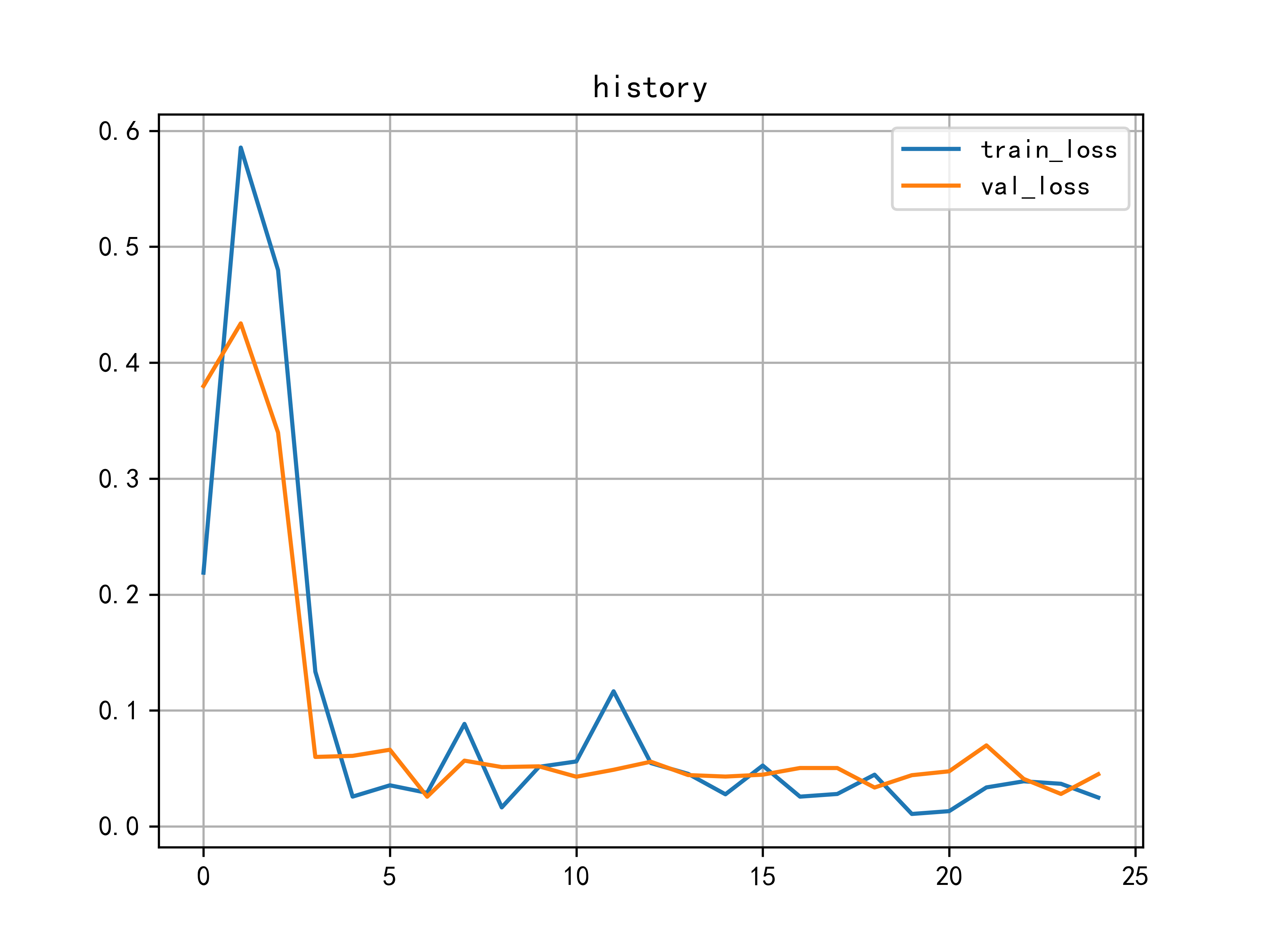
234.1 KB
{kind=link}
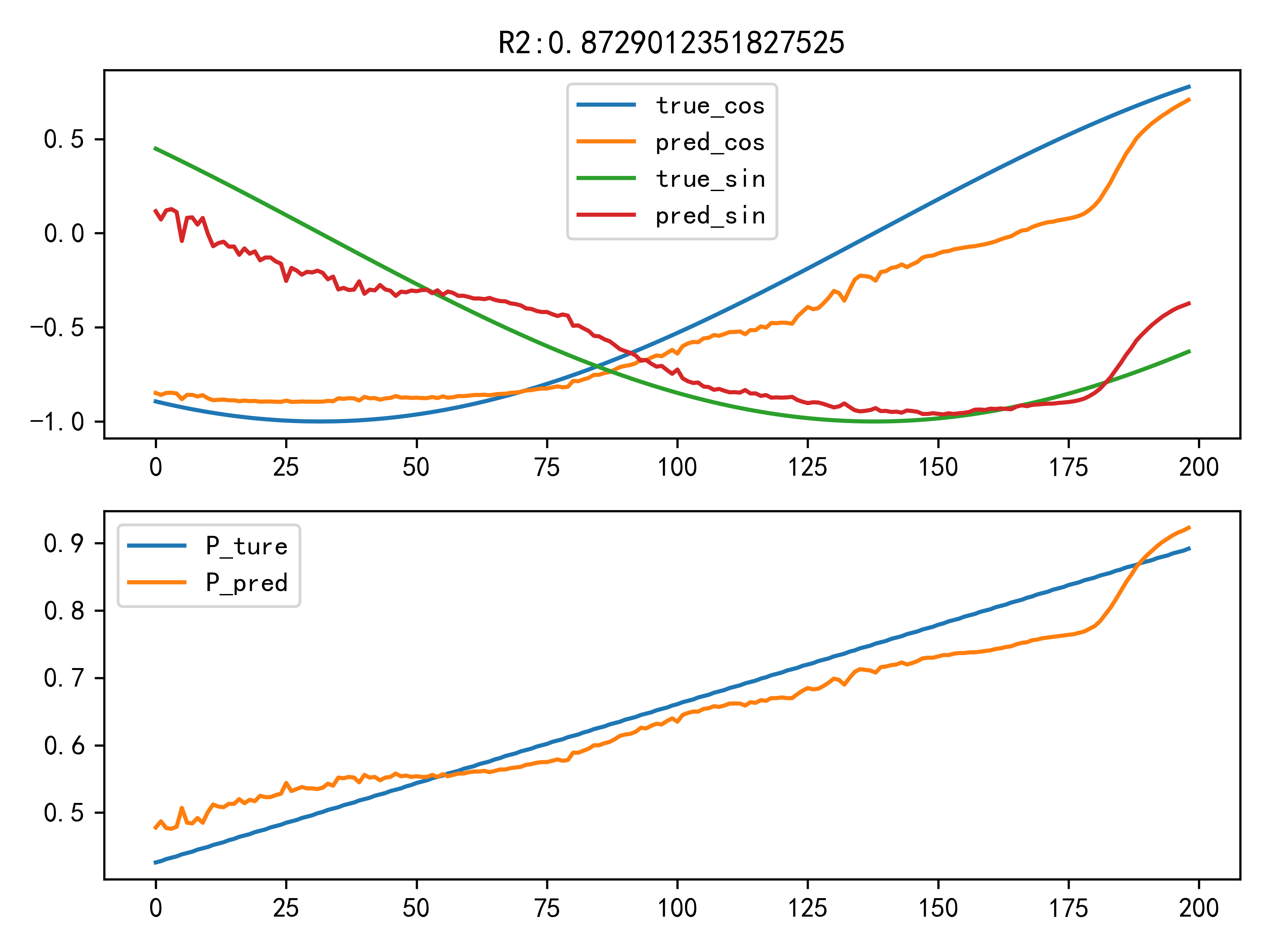
433.8 KB
model/多头/多头注意力.pth
0 → 100644
文件已添加
model/多头/训练图.png
0 → 100644
{kind=link}
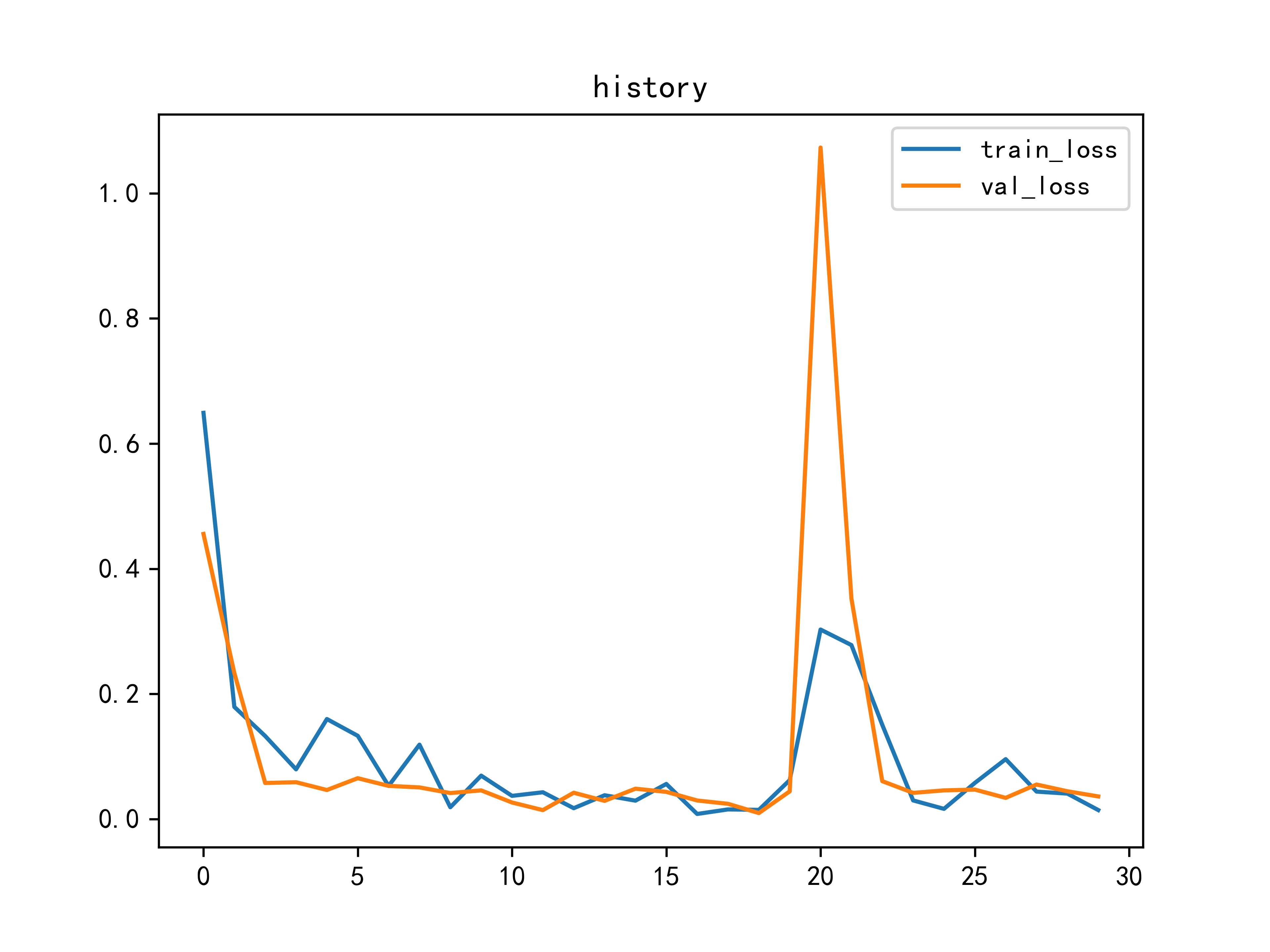
230.9 KB
文件已添加
{kind=link}
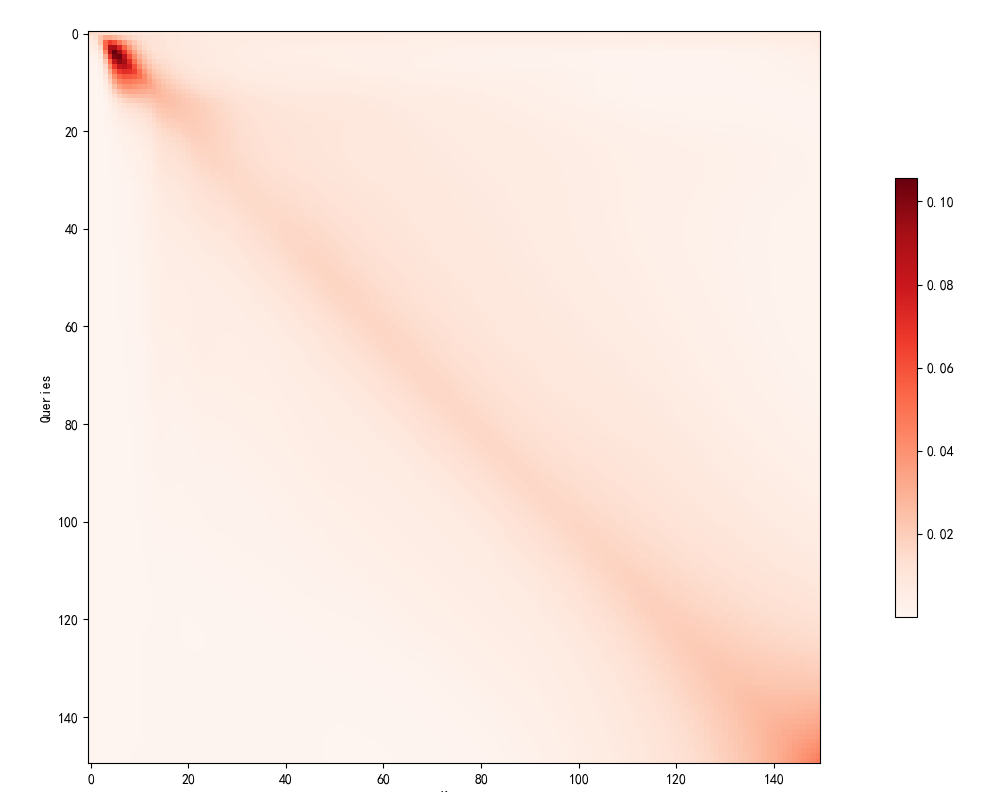
105.3 KB
{kind=link}
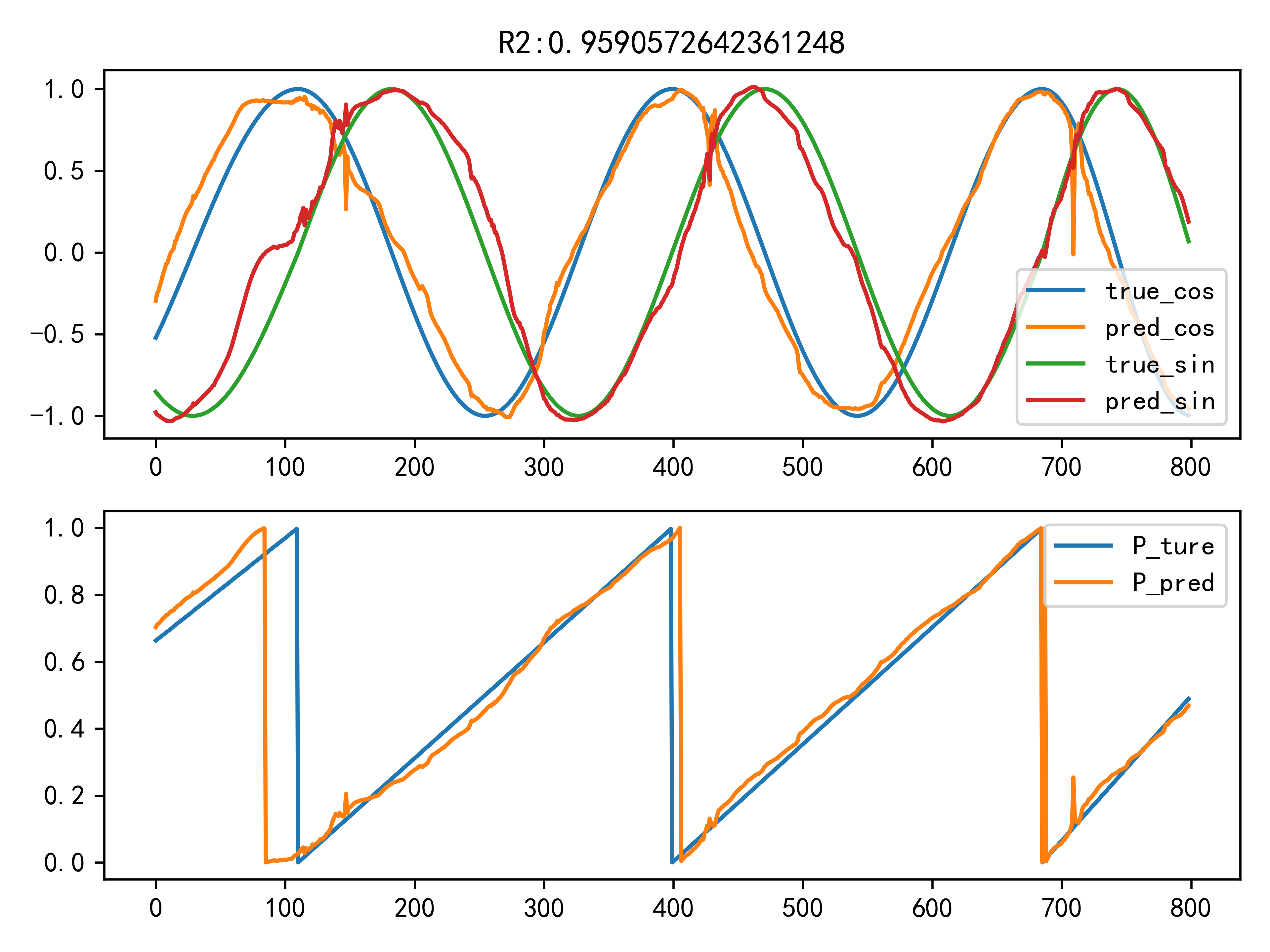
678.2 KB
model/缩放点积注意力/算力.txt
0 → 100644
model/缩放点积注意力/训练图.png
0 → 100644
{kind=link}
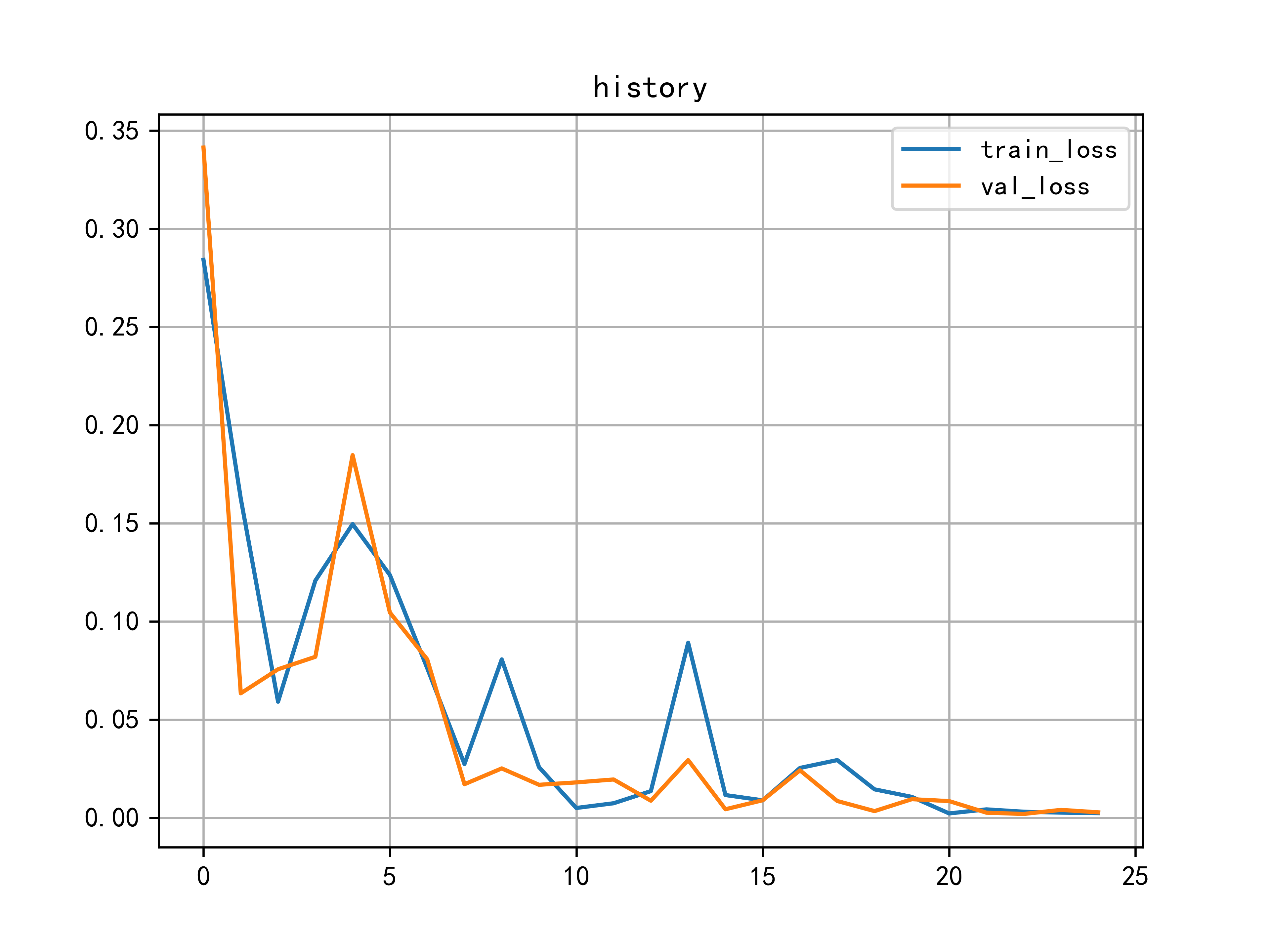
261.3 KB
model2.py
0 → 100644