Commits (3)
Showing
cn/docs/adv_examples/bert.md
已删除
100644 → 0
cn/docs/adv_examples/dcgan.md
已删除
100644 → 0

23.0 KB
13.3 KB
13.5 KB
45.2 KB

144.5 KB
19.7 KB

79.2 KB
7.7 KB
7.6 KB
95.3 KB
8.4 KB
9.0 KB

203.2 KB
38.5 KB
此差异已折叠。
此差异已折叠。
en/docs/adv_examples/bert.md
已删除
100644 → 0
en/docs/adv_examples/dcgan.md
已删除
100644 → 0

23.0 KB
13.3 KB
13.5 KB
45.2 KB

144.5 KB
19.7 KB

79.2 KB
7.7 KB
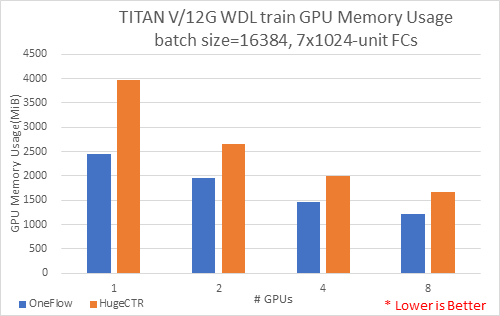
7.6 KB
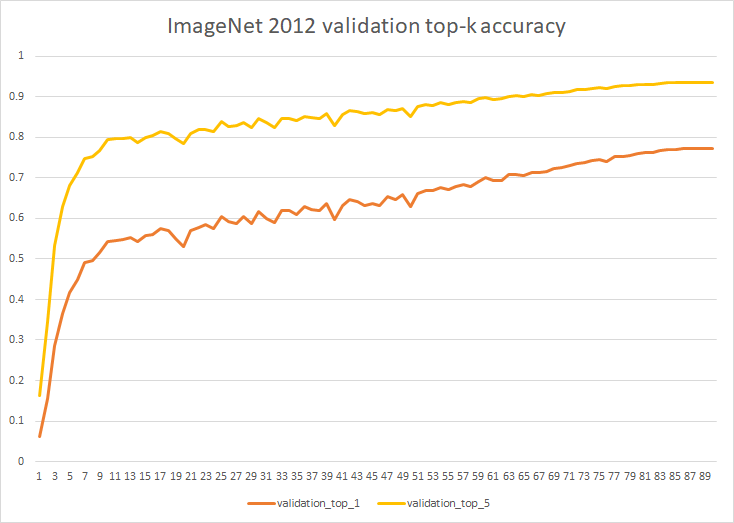
26.7 KB
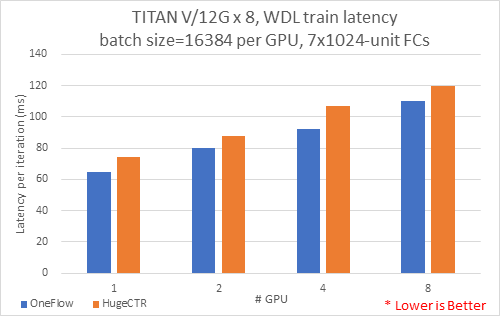
8.4 KB
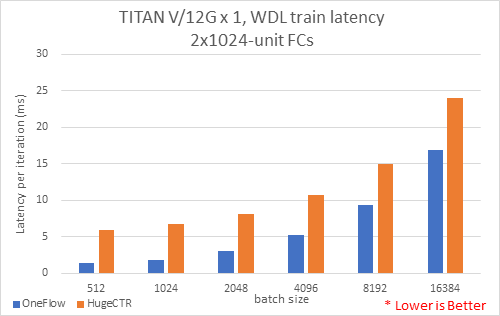
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
9.0 KB
{kind=link}

14.3 KB
{kind=link}
38.5 KB
此差异已折叠。
此差异已折叠。