Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
OAID
Tengine
提交
c2496176
T
Tengine
项目概览
OAID
/
Tengine
9 个月 前同步成功
通知
53
Star
4429
Fork
1032
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
DevOps
流水线
流水线任务
计划
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
T
Tengine
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
DevOps
DevOps
流水线
流水线任务
计划
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
流水线任务
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
未验证
提交
c2496176
编写于
1月 06, 2021
作者:
B
BUG1989
提交者:
GitHub
1月 07, 2021
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
update png (#526)
上级
60469908
变更
11
隐藏空白更改
内联
并排
Showing
11 changed file
with
42 addition
and
6 deletion
+42
-6
README.md
README.md
+7
-2
doc/architecture.png
doc/architecture.png
+0
-0
doc/roadmap.md
doc/roadmap.md
+2
-2
src/dev/cpu/op/conv/conv_dw_hcl_mips.c
src/dev/cpu/op/conv/conv_dw_hcl_mips.c
+4
-0
src/dev/cpu/op/conv/mips/conv_dw_kernel_mips.c
src/dev/cpu/op/conv/mips/conv_dw_kernel_mips.c
+7
-2
src/dev/cpu/op/conv/mips/conv_dw_kernel_mips.h
src/dev/cpu/op/conv/mips/conv_dw_kernel_mips.h
+4
-0
src/dev/cpu/op/conv/mips/conv_kernel_mips.c
src/dev/cpu/op/conv/mips/conv_kernel_mips.c
+4
-0
src/dev/cpu/op/conv/mips/conv_kernel_mips.h
src/dev/cpu/op/conv/mips/conv_kernel_mips.h
+4
-0
src/dev/cpu/op/conv/mips/wino_conv_kernel_mips.c
src/dev/cpu/op/conv/mips/wino_conv_kernel_mips.c
+5
-0
src/dev/cpu/op/conv/mips/wino_conv_kernel_mips.h
src/dev/cpu/op/conv/mips/wino_conv_kernel_mips.h
+4
-0
src/dev/cpu/op/conv/x86/conv_dw_kernel_x86.c
src/dev/cpu/op/conv/x86/conv_dw_kernel_x86.c
+1
-0
未找到文件。
README.md
浏览文件 @
c2496176
...
...
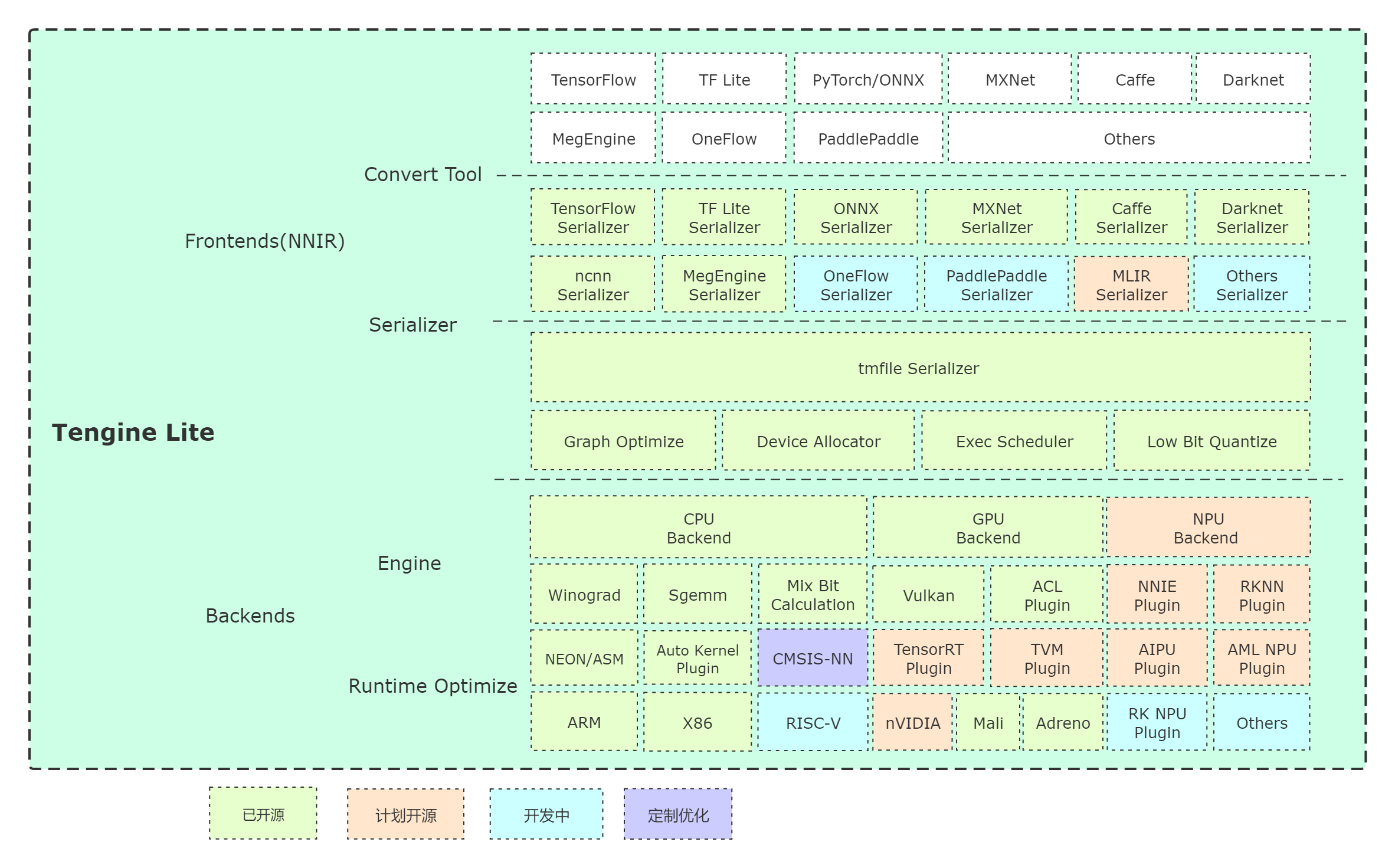
@@ -43,9 +43,13 @@ Tengine Lite 核心代码由 4 个模块组成:
### 转换工具
-
[
预编译版本
](
https://github.com/OAID/Tengine
-Convert-Tools/releases/download/v0.1/tm_convert_tool
)
:提供 Linux
系统上预编译好的模型转换工具;
-
[
预编译版本
](
https://github.com/OAID/Tengine
/releases/download/lite-v1.2/convert_tool.zip
)
:提供 Ubuntu 18.04
系统上预编译好的模型转换工具;
-
[
在线转换版本
](
https://convertmodel.com/
)
:基于 WebAssembly 实现(浏览器本地转换,模型不会上传);
-
[
源码编译
](
https://github.com/OAID/Tengine-Convert-Tools
)
:参考
**Tengine-Convert-Tools**
项目编译生成。
-
[
源码编译
](
https://github.com/OAID/Tengine-Convert-Tools
)
:参考
**Tengine-Convert-Tools**
项目编译生成,建议采用。
### 量化工具
-
[
预编译版本
](
tools/quantize/README.md
)
:提供 Ubuntu 18.04 系统上预编译好的模型量化工具,已支持uint8/int8;
### 速度评估
...
...
@@ -67,6 +71,7 @@ Tengine Lite 参考和借鉴了下列项目:
-
[
MegEngine
](
https://github.com/MegEngine/MegEngine
)
-
[
ONNX
](
https://github.com/onnx/onnx
)
-
[
ncnn
](
https://github.com/Tencent/ncnn
)
-
[
FeatherCNN
](
https://github.com/Tencent/FeatherCNN
)
-
[
MNN
](
https://github.com/alibaba/MNN
)
-
[
Paddle Lite
](
https://github.com/PaddlePaddle/Paddle-Lite
)
-
[
ACL
](
https://github.com/ARM-software/ComputeLibrary
)
...
...
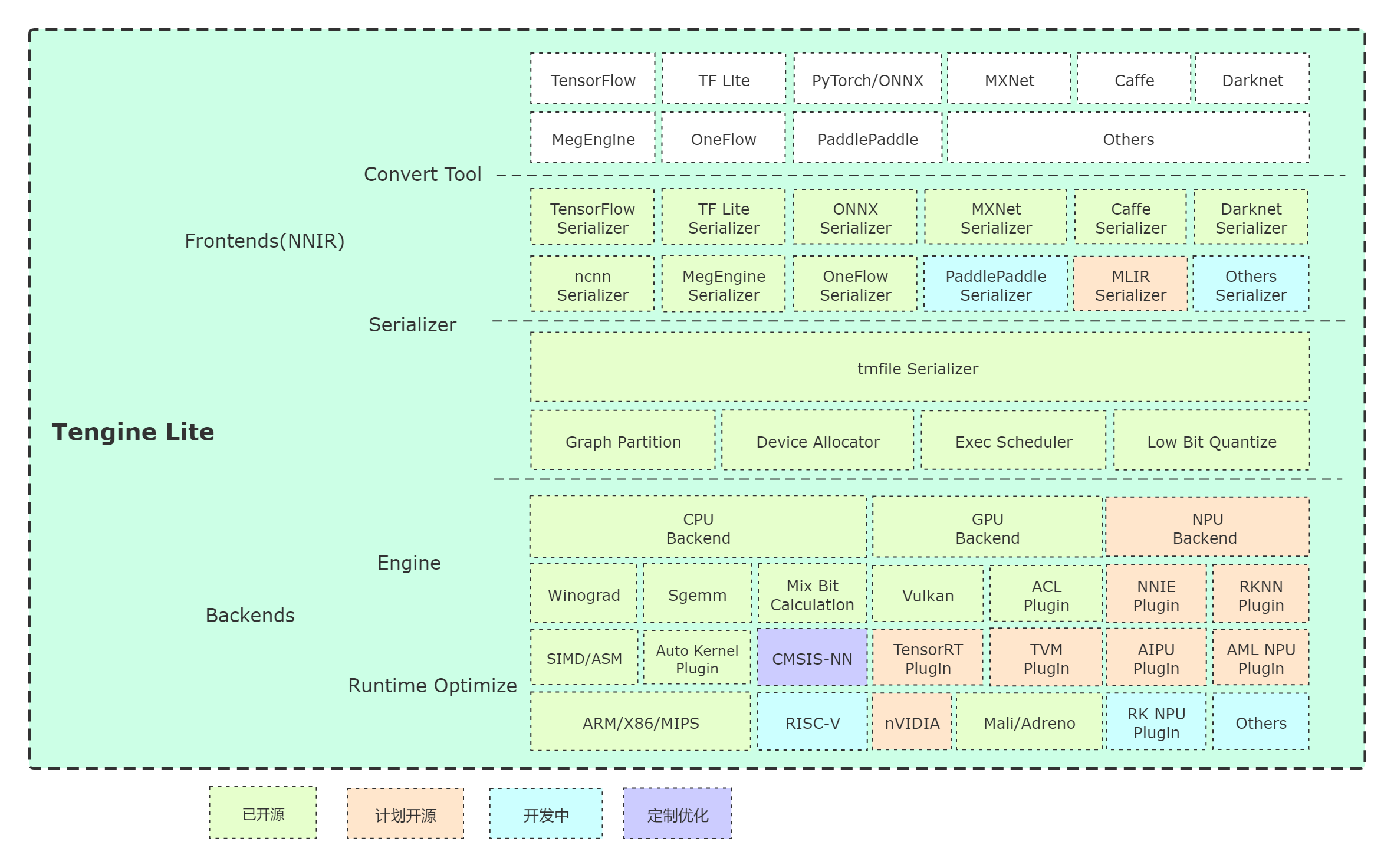
doc/architecture.png
查看替换文件 @
60469908
浏览文件 @
c2496176
315.6 KB
|
W:
|
H:
317.6 KB
|
W:
|
H:
2-up
Swipe
Onion skin
doc/roadmap.md
浏览文件 @
c2496176
...
...
@@ -6,6 +6,6 @@
-
[ ] optimize AutoKernel implement on x86
-
[ ] fix the Float32 bugs of Vulkan
-
[ ] support the mode type of PaddlePaddle
-
[
] support the mode type of OneFlow
-
[
x
] support the mode type of OneFlow
-
[ ] opensource the plugin implement of NPU
-
[
] add more test case
-
[
x
] add more test case
src/dev/cpu/op/conv/conv_dw_hcl_mips.c
浏览文件 @
c2496176
...
...
@@ -17,6 +17,10 @@
* under the License.
*/
/*
* Copyright (c) 2020, Martin Han
* Author: hansh-sz@hotmail.com
*/
#include "sys_port.h"
#include "module.h"
...
...
src/dev/cpu/op/conv/mips/conv_dw_kernel_mips.c
浏览文件 @
c2496176
...
...
@@ -17,6 +17,10 @@
* under the License.
*/
/*
* Copyright (c) 2020, Martin Han
* Author: hansh-sz@hotmail.com
*/
#include <stdint.h>
#include <stdlib.h>
...
...
@@ -52,7 +56,7 @@ void convdw3x3s1(float* output, float* input, float* _kernel, float* _bias, int
const
int
group
=
channel
;
const
float
*
kernel
=
_kernel
;
#pragma omp parallel for num_threads(num_thread)
#pragma omp parallel for num_threads(num_thread)
for
(
int
g
=
0
;
g
<
group
;
g
++
)
{
float
*
out
=
output
+
g
*
c_step_out
;
...
...
@@ -168,7 +172,7 @@ void convdw3x3s2(float* output, float* input, float* _kernel, float* _bias, int
const
int
tailstep
=
w
-
2
*
outw
+
w
;
const
float
*
kernel
=
_kernel
;
#pragma omp parallel for num_threads(num_thread)
#pragma omp parallel for num_threads(num_thread)
for
(
int
g
=
0
;
g
<
group
;
g
++
)
{
float
*
out
=
output
+
g
*
c_step_out
;
...
...
@@ -317,6 +321,7 @@ int conv_dw_run(struct ir_tensor* input_tensor, struct ir_tensor* weight_tensor,
else
{
input_tmp
=
(
float
*
)
sys_malloc
(
inh_tmp
*
inw_tmp
*
group
*
sizeof
(
float
));
#pragma omp parallel for num_threads(num_thread)
for
(
int
g
=
0
;
g
<
group
;
g
++
)
{
float
*
pad_in
=
input
+
g
*
inh
*
inw
;
...
...
src/dev/cpu/op/conv/mips/conv_dw_kernel_mips.h
浏览文件 @
c2496176
...
...
@@ -17,6 +17,10 @@
* under the License.
*/
/*
* Copyright (c) 2020, Martin Han
* Author: hansh-sz@hotmail.com
*/
#ifndef __CONV_DW_KERNEL_MIPS_H_
#define __CONV_DW_KERNEL_MIPS_H_
...
...
src/dev/cpu/op/conv/mips/conv_kernel_mips.c
浏览文件 @
c2496176
...
...
@@ -17,6 +17,10 @@
* under the License.
*/
/*
* Copyright (c) 2020, Martin Han
* Author: hansh-sz@hotmail.com
*/
#include <stdint.h>
#include <stdlib.h>
...
...
src/dev/cpu/op/conv/mips/conv_kernel_mips.h
浏览文件 @
c2496176
...
...
@@ -17,6 +17,10 @@
* under the License.
*/
/*
* Copyright (c) 2020, Martin Han
* Author: hansh-sz@hotmail.com
*/
#ifndef _CONV_KERNEL_MIPS_H_
#define _CONV_KERNEL_MIPS_H_
...
...
src/dev/cpu/op/conv/mips/wino_conv_kernel_mips.c
浏览文件 @
c2496176
...
...
@@ -17,6 +17,11 @@
* under the License.
*/
/*
* Copyright (c) 2020, Martin Han
* Author: hansh-sz@hotmail.com
*/
#include <stdint.h>
#include <stdlib.h>
#include <math.h>
...
...
src/dev/cpu/op/conv/mips/wino_conv_kernel_mips.h
浏览文件 @
c2496176
...
...
@@ -17,6 +17,10 @@
* under the License.
*/
/*
* Copyright (c) 2020, Martin Han
* Author: hansh-sz@hotmail.com
*/
#ifndef __WINO_CONV_KERNEL_MIPS_H_
#define __WINO_CONV_KERNEL_MIPS_H_
...
...
src/dev/cpu/op/conv/x86/conv_dw_kernel_x86.c
浏览文件 @
c2496176
...
...
@@ -2552,6 +2552,7 @@ int conv_dw_run(struct ir_tensor* input_tensor, struct ir_tensor* weight_tensor,
else
{
input_tmp
=
(
float
*
)
sys_malloc
(
inh_tmp
*
inw_tmp
*
group
*
sizeof
(
float
));
#pragma omp parallel for num_threads(num_thread)
for
(
int
g
=
0
;
g
<
group
;
g
++
)
{
float
*
pad_in
=
input
+
g
*
inh
*
inw
;
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}