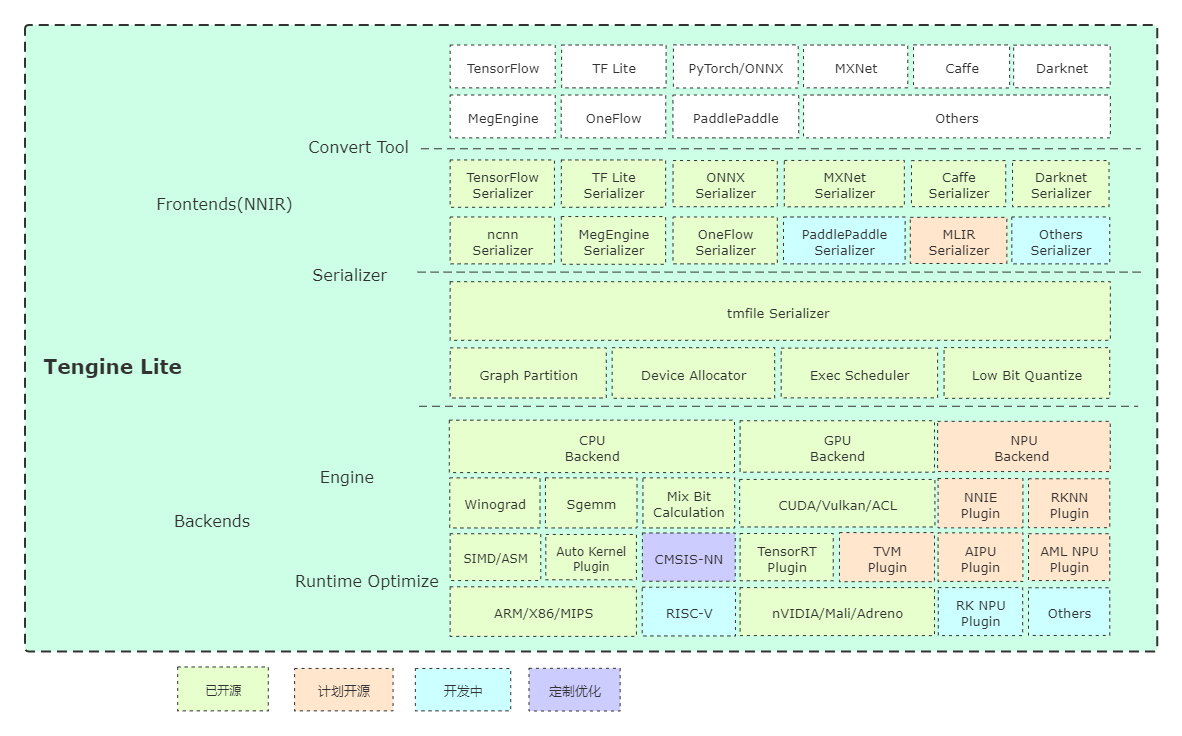
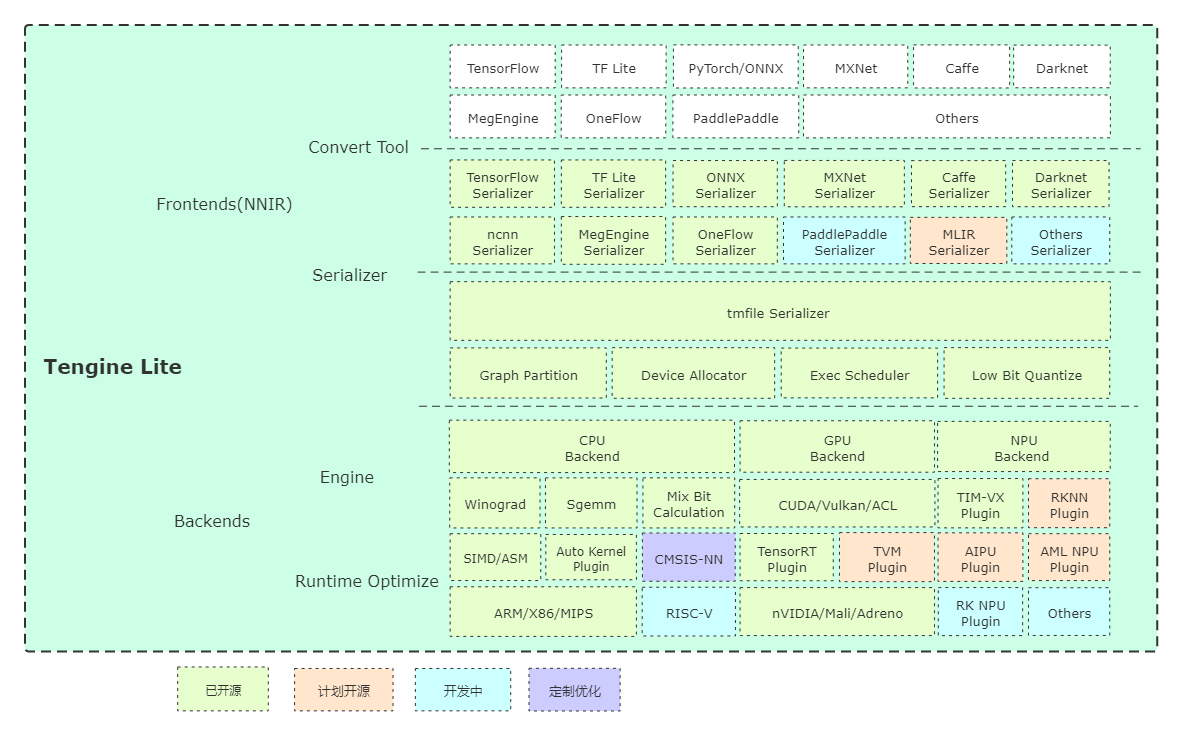
initial to support TIM-VX NPU backend
Showing
{kind=link}
{kind=link}
| W: | H:
| W: | H:
doc/npu_tim-vx_user_manual.md
0 → 100644
src/dev/tim-vx/op/timvx_add.cc
0 → 100644
src/dev/tim-vx/op/timvx_clip.cc
0 → 100644
src/dev/tim-vx/op/timvx_concat.cc
0 → 100644
src/dev/tim-vx/op/timvx_fc.cc
0 → 100644
src/dev/tim-vx/op/timvx_relu.cc
0 → 100644
src/dev/tim-vx/timvx_device.cc
0 → 100644
src/dev/tim-vx/timvx_device.hpp
0 → 100644
src/dev/tim-vx/timvx_executor.cc
0 → 100644
src/dev/tim-vx/timvx_executor.hpp
0 → 100644
src/dev/tim-vx/timvx_graph.cc
0 → 100644
src/dev/tim-vx/timvx_graph.hpp
0 → 100644
src/dev/tim-vx/timvx_helper.hpp
0 → 100644
src/dev/tim-vx/timvx_limit.hpp
0 → 100644