Merge branch 'develop' of https://github.com/PaddlePaddle/Paddle into external
Showing
WORKSPACE
已删除
100644 → 0
demo/mnist/api_train.py
0 → 100644
demo/mnist/mnist_util.py
0 → 100644
demo/quick_start/cluster/env.sh
0 → 100644
doc/tutorials/gan/gan.png
0 → 100644
{kind=link}
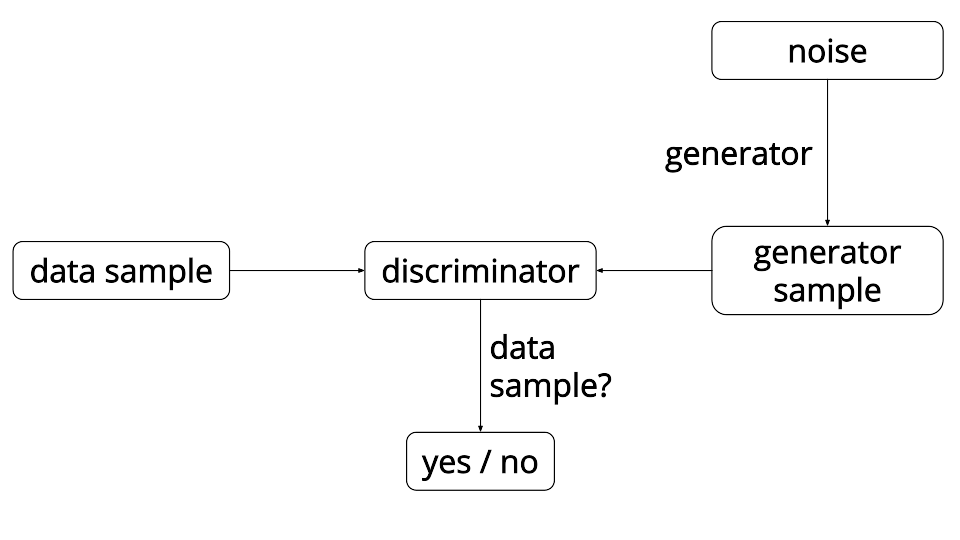
32.5 KB
doc/tutorials/gan/index_en.md
0 → 100644
{kind=link}
28.0 KB
{kind=link}
20.1 KB
paddle/api/ParameterUpdater.cpp
0 → 100644
文件已移动
third_party/gflags.BUILD
已删除
100644 → 0
third_party/gflags_test/BUILD
已删除
100644 → 0
third_party/glog.BUILD
已删除
100644 → 0
third_party/glog_test/BUILD
已删除
100644 → 0
third_party/gtest.BUILD
已删除
100644 → 0