更新了数据分析部分的文档
Showing
Day66-70/res/broadcast-1.png
0 → 100644
{kind=link}
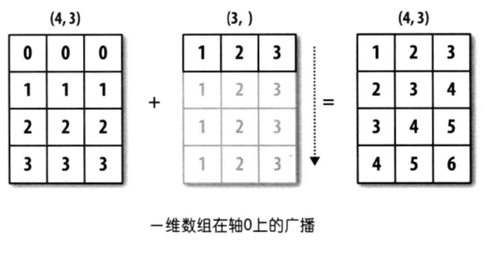
50.4 KB
Day66-70/res/broadcast-2.png
0 → 100644
{kind=link}
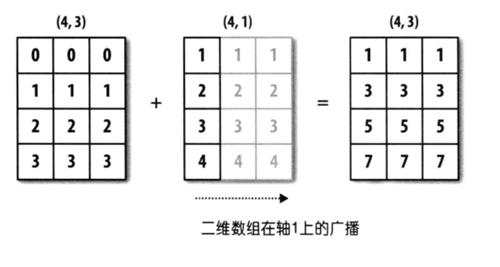
46.2 KB
Day66-70/res/broadcast-3.png
0 → 100644
{kind=link}
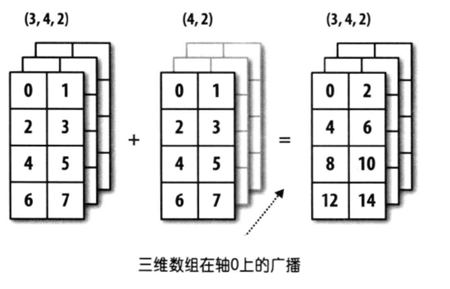
58.9 KB
Day66-70/res/image-flip-1.png
0 → 100644
{kind=link}

510.6 KB
Day66-70/res/image-flip-2.png
0 → 100644
{kind=link}
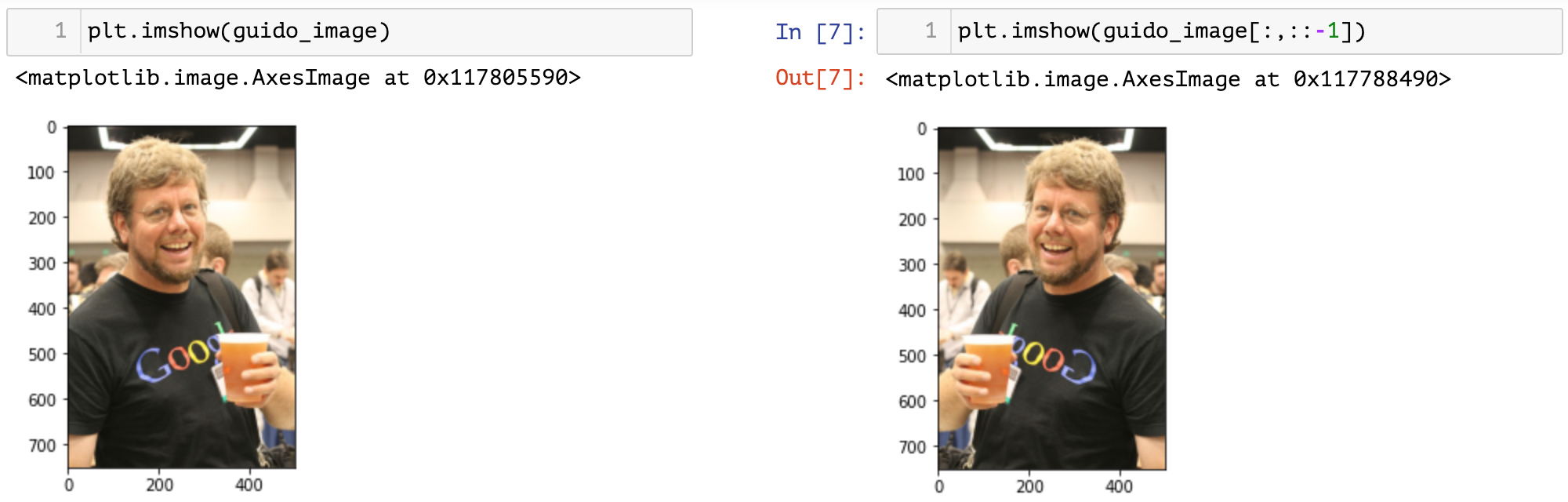
474.3 KB
Day66-70/res/image-flip-3.png
0 → 100644
{kind=link}
509.1 KB