Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
风灵Erick
Python-100-Days
提交
395d37d4
P
Python-100-Days
项目概览
风灵Erick
/
Python-100-Days
与 Fork 源项目一致
从无法访问的项目Fork
通知
1
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
Python-100-Days
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
395d37d4
编写于
10月 19, 2020
作者:
J
jackfrued
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
更新了部分文档
上级
e0218119
变更
14
隐藏空白更改
内联
并排
Showing
14 changed file
with
344 addition
and
20 deletion
+344
-20
Day41-55/49.RESTful架构和DRF入门.md
Day41-55/49.RESTful架构和DRF入门.md
+9
-1
Day41-55/50.RESTful架构和DRF进阶.md
Day41-55/50.RESTful架构和DRF进阶.md
+62
-0
Day41-55/51.使用缓存.md
Day41-55/51.使用缓存.md
+145
-1
Day41-55/52.接入三方平台.md
Day41-55/52.接入三方平台.md
+100
-1
Day41-55/53.异步任务和定时任务.md
Day41-55/53.异步任务和定时任务.md
+9
-1
Day41-55/54.单元测试.md
Day41-55/54.单元测试.md
+2
-1
Day41-55/55.项目上线.md
Day41-55/55.项目上线.md
+1
-9
Day41-55/res/luosimao-pay-onlinebuy.png
Day41-55/res/luosimao-pay-onlinebuy.png
+0
-0
Day41-55/res/luosimao-sms-apikey.png
Day41-55/res/luosimao-sms-apikey.png
+0
-0
Day41-55/res/luosimao-sms-signature.png
Day41-55/res/luosimao-sms-signature.png
+0
-0
Day41-55/res/luosimao-sms-whitelist.png
Day41-55/res/luosimao-sms-whitelist.png
+0
-0
Day41-55/res/redis-cache-service.png
Day41-55/res/redis-cache-service.png
+0
-0
Day91-100/93.MySQL性能优化.md
Day91-100/93.MySQL性能优化.md
+15
-5
README.md
README.md
+1
-1
未找到文件。
Day41-55/49.RESTful架构和DRF入门.md
浏览文件 @
395d37d4
...
...
@@ -80,6 +80,9 @@ REST_FRAMEWORK = {
前后端分离的开发需要后端为前端、移动端提供API数据接口,而API接口通常情况下都是返回JSON格式的数据,这就需要对模型对象进行序列化处理。DRF中封装了
`Serializer`
类和
`ModelSerializer`
类用于实现序列化操作,通过继承
`Serializer`
类或
`ModelSerializer`
类,我们可以自定义序列化器,用于将对象处理成字典,代码如下所示。
```
Python
from rest_framework import serializers
class SubjectSerializer(serializers.ModelSerializer):
class Meta:
...
...
@@ -94,6 +97,10 @@ class SubjectSerializer(serializers.ModelSerializer):
DRF框架支持两种实现数据接口的方式,一种是FBV(基于函数的视图),另一种是CBV(基于类的视图)。我们先看看FBV的方式如何实现数据接口,代码如下所示。
```
Python
from rest_framework.decorators import api_view
from rest_framework.response import Response
@api_view(('GET', ))
def show_subjects(request: HttpRequest) -> HttpResponse:
subjects = Subject.objects.all().order_by('no')
...
...
@@ -343,4 +350,4 @@ except InvalidTokenError:
raise AuthenticationFailed('无效的令牌或令牌已经过期')
```
相信通过上面的讲解,大家已经可以自行完成对投票项目用户登录功能的修改,如果有什么疑惑,可以参考我的代码,点击
[
地址一
](
https://github.com/jackfrued/vote
)
或
[
地址二
](
https://gitee.com/jackfrued/vote
)
可以打开项目仓库的页面
。
如果不清楚JWT具体的使用方式,可以先看看第55天的内容,里面提供了完整的投票项目代码的地址
。
\ No newline at end of file
Day41-55/50.RESTful架构和DRF进阶.md
浏览文件 @
395d37d4
...
...
@@ -9,6 +9,9 @@
修改之前项目中的
`polls/views.py`
,去掉
`show_subjects`
视图函数,添加一个名为
`SubjectView`
的类,该类继承自
`ListAPIView`
,
`ListAPIView`
能接收GET请求,它封装了获取数据列表并返回JSON数据的
`get`
方法。
`ListAPIView`
是
`APIView`
的子类,
`APIView`
还有很多的子类,例如
`CreateAPIView`
可以支持POST请求,
`UpdateAPIView`
可以支持PUT和PATCH请求,
`DestoryAPIView`
可以支持DELETE请求。
`SubjectView`
的代码如下所示。
```
Python
from rest_framework.generics import ListAPIView
class SubjectView(ListAPIView):
# 通过queryset指定如何获取学科数据
queryset = Subject.objects.all()
...
...
@@ -31,6 +34,9 @@ urlpatterns = [
如果学科对应的数据接口需要支持GET、POST、PUT、PATCH、DELETE请求来支持对学科资源的获取、新增、更新、删除操作,更为简单的做法是继承
`ModelViewSet`
来编写学科视图类。再次修改
`polls/views.py`
文件,去掉
`SubjectView`
类,添加一个名为
`SubjectViewSet`
的类,代码如下所示。
```
Python
from rest_framework.viewsets import ModelViewSet
class SubjectViewSet(ModelViewSet):
queryset = Subject.objects.all()
serializer_class = SubjectSerializer
...
...
@@ -55,6 +61,8 @@ class ModelViewSet(mixins.CreateModelMixin,
要使用上面的
`SubjectViewSet`
,需要在
`urls.py`
文件中进行URL映射。由于
`ModelViewSet`
相当于是多个视图函数的汇总,所以不同于之前映射URL的方式,我们需要先创建一个路由器并通过它注册
`SubjectViewSet`
,然后将注册成功后生成的URL一并添加到
`urlspattern`
列表中,代码如下所示。
```
Python
from rest_framework.routers import DefaultRouter
router = DefaultRouter()
router.register('api/subjects', SubjectViewSet)
urlpatterns += router.urls
...
...
@@ -64,5 +72,58 @@ urlpatterns += router.urls
### 数据分页
在使用GET请求获取资源列表时,我们通常不会一次性的加载所有的数据,除非数据量真的很小。大多数获取资源列表的操作都支持数据分页展示,也就说我们可以通过指定页码(或类似于页码的标识)和页面大小(一次加载多少条数据)来获取不同的数据。我们可以通过对
`QuerySet`
对象的切片操作来实现分页,也可以利用Django框架封装的
`Paginator`
和
`Page`
对象来实现分页。使用DRF时,可以在Django配置文件中修改
`REST_FRAMEWORK`
并配置默认的分页类和页面大小来实现分页,如下所示。
```
Python
REST_FRAMEWORK = {
'PAGE_SIZE': 10,
'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.PageNumberPagination'
}
```
除了上面配置的
`PageNumberPagination`
分页器之外,DRF还提供了
`LimitOffsetPagination`
和
`CursorPagination`
分页器,值得一提的是
`CursorPagination`
,它可以避免使用页码分页时暴露网站的数据体量,有兴趣的读者可以自行了解。如果不希望使用配置文件中默认的分页设定,可以在视图类中添加一个
`pagination_class`
属性来重新指定分页器,通常可以将该属性指定为自定义的分页器,如下所示。
```
Python
from rest_framework.pagination import PageNumberPagination
class CustomizedPagination(PageNumberPagination):
# 默认页面大小
page_size = 5
# 页面大小对应的查询参数
page_size_query_param = 'size'
# 页面大小的最大值
max_page_size = 50
```
```
Python
class SubjectView(ListAPIView):
# 指定如何获取数据
queryset = Subject.objects.all()
# 指定如何序列化数据
serializer_class = SubjectSerializer
# 指定如何分页
pagination_class = CustomizedPagination
```
如果不希望数据分页,可以将
`pagination_class`
属性设置为
`None`
来取消默认的分页器。
### 数据筛选
如果希望使用CBV定制获取老师信息的数据接口,也可以通过继承
`ListAPIView`
来实现。但是因为要通过指定的学科来获取对应的老师信息,因此需要对老师数据进行筛选而不是直接获取所有老师的数据。如果想从请求中获取学科编号并通过学科编号对老师进行筛选,可以通过重写
`get_queryset`
方法来做到,代码如下所示。
```
Python
class TeacherView(ListAPIView):
serializer_class = TeacherSerializer
def get_queryset(self):
queryset = Teacher.objects.defer('subject')
try:
sno = self.request.GET.get('sno', '')
queryset = queryset.filter(subject__no=sno)
return queryset
except ValueError:
raise Http404('No teachers found.')
```
除了上述方式之外,还可以使用三方库
`django-filter`
来配合DRF实现对数据的筛选,使用
`django-filter`
后,可以通过为视图类配置
`filter-backends`
属性并指定使用
`DjangoFilterBackend`
来支持数据筛选。在完成上述配置后,可以使用
`filter_fields`
属性或
`filterset_class`
属性来指定如何筛选数据,有兴趣的读者可以自行研究。
\ No newline at end of file
Day41-55/51.使用缓存.md
浏览文件 @
395d37d4
## 使用缓存
通常情况下,Web应用的性能瓶颈都会出现在关系型数据库上,当并发访问量较大时,如果所有的请求都需要通过关系型数据库完成数据持久化操作,那么数据库一定会不堪重负。优化Web应用性能最为重要的一点就是使用缓存,
就是把哪些数据体量不大但访问频率非常高的数据提前加载到缓存服务器中,这又是典型的空间换时间的方法。通常缓存服务器都是直接将数据置于内存中而且使用了非常高效的数据存取策略(例如:键值对方式),在读写性能上是远远优于传统的关系型数据库的,因此我们可以让Web应用接入缓存服务器来优化其性能,
一个非常好的选择就是使用Redis。
通常情况下,Web应用的性能瓶颈都会出现在关系型数据库上,当并发访问量较大时,如果所有的请求都需要通过关系型数据库完成数据持久化操作,那么数据库一定会不堪重负。优化Web应用性能最为重要的一点就是使用缓存,
把那些数据体量不大但访问频率非常高的数据提前加载到缓存服务器中,这又是典型的空间换时间的方法。通常缓存服务器都是直接将数据置于内存中而且使用了非常高效的数据存取策略(哈希存储、键值对方式等),在读写性能上远远优于关系型数据库的,因此我们可以让Web应用接入缓存服务器来优化其性能,其中
一个非常好的选择就是使用Redis。
Web应用的缓存架构大致如下图所示。

### Django项目接入Redis
在此前的课程中,我们介绍过Redis的安装和使用,此处不再进行赘述。如果需要在Django项目中接入Redis,可以使用三方库
`django-redis`
,这个三方库又依赖了一个名为
`redis`
的三方库,它封装了对Redis的各种操作。
安装
`django-redis`
。
```
Bash
pip install django-redis
```
修改Django配置文件中关于缓存的配置。
```
Python
CACHES = {
'default': {
# 指定通过django-redis接入Redis服务
'BACKEND': 'django_redis.cache.RedisCache',
# Redis服务器的URL
'LOCATION': ['redis://1.2.3.4:6379/0', ],
# Redis中键的前缀(解决命名冲突)
'KEY_PREFIX': 'vote',
# 其他的配置选项
'OPTIONS': {
'CLIENT_CLASS': 'django_redis.client.DefaultClient',
# 连接池(预置若干备用的Redis连接)参数
'CONNECTION_POOL_KWARGS': {
# 最大连接数
'max_connections': 512,
},
# 连接Redis的用户口令
'PASSWORD': 'foobared',
}
},
}
```
至此,我们的Django项目已经可以接入Redis,接下来我们修改项目代码,用Redis为之写的获取学科数据的接口提供缓存服务。
### 为视图提供缓存服务
#### 声明式缓存
所谓声明式缓存是指不修改原来的代码,通过Python中的装饰器(代理)为原有的代码增加缓存功能。对于FBV,代码如下所示。
```
Python
from django.views.decorators.cache import cache_page
@api_view(('GET', ))
@cache_page(timeout=86400, cache='default')
def show_subjects(request):
"""获取学科数据"""
queryset = Subject.objects.all()
data = SubjectSerializer(queryset, many=True).data
return Response({'code': 20000, 'subjects': data})
```
上面的代码通过Django封装的
`cache_page`
装饰器缓存了视图函数的返回值(响应对象),
`cache_page`
的本意是缓存视图函数渲染的页面,对于返回JSON数据的视图函数,相当于是缓存了JSON数据。在使用
`cache_page`
装饰器时,可以传入
`timeout`
参数来指定缓存过期时间,还可以使用
`cache`
参数来指定需要使用哪一组缓存服务来缓存数据。Django项目允许在配置文件中配置多组缓存服务,上面的
`cache='default'`
指定了使用默认的缓存服务(因为之前的配置文件中我们也只配置了名为
`default`
的缓存服务)。视图函数的返回值会被序列化成字节串放到Redis中(Redis中的str类型可以接收字节串),缓存数据的序列化和反序列化也不需要我们自己处理,因为
`cache_page`
装饰器会调用
`django-redis`
库中的
`RedisCache`
来对接Redis,该类使用了
`DefaultClient`
来连接Redis并使用了
[
pickle序列化
](
https://python3-cookbook.readthedocs.io/zh_CN/latest/c05/p21_serializing_python_objects.html
)
,
`django_redis.serializers.pickle.PickleSerializer`
是默认的序列化类。
如果缓存中没有学科的数据,那么通过接口访问学科数据时,我们的视图函数会通过执行
`Subject.objects.all()`
向数据库发出SQL语句来获得数据,视图函数的返回值会被缓存,因此下次请求该视图函数如果缓存没有过期,可以直接从缓存中获取视图函数的返回值,无需再次查询数据库。如果想了解缓存的使用情况,可以配置数据库日志或者使用Django-Debug-Toolbar来查看,第一次访问学科数据接口时会看到查询学科数据的SQL语句,再次获取学科数据时,不会再向数据库发出SQL语句,因为可以直接从缓存中获取数据。
对于CBV,可以利用Django中名为
`method_decorator`
的装饰器将
`cache_page`
这个装饰函数的装饰器放到类中的方法上,效果跟上面的代码是一样的。需要提醒大家注意的是,
`cache_page`
装饰器不能直接放在类上,因为它是装饰函数的装饰器,所以Django框架才提供了
`method_decorator`
来解决这个问题,很显然,
`method_decorator`
是一个装饰类的装饰器。
```
Python
from django.utils.decorators import method_decorator
from django.views.decorators.cache import cache_page
@method_decorator(decorator=cache_page(timeout=86400, cache='default'), name='get')
class SubjectView(ListAPIView):
"""获取学科数据的视图类"""
queryset = Subject.objects.all()
serializer_class = SubjectSerializer
```
#### 编程式缓存
所谓编程式缓存是指通过自己编写的代码来使用缓存服务,这种方式虽然代码量会稍微大一些,但是相较于声明式缓存,它对缓存的操作和使用更加灵活,在实际开发中使用得更多。下面的代码去掉了之前使用的
`cache_page`
装饰器,通过
`django-redis`
提供的
`get_redis_connection`
函数直接获取Redis连接来操作Redis。
```
Python
def show_subjects(request):
"""获取学科数据"""
redis_cli = get_redis_connection()
# 先尝试从缓存中获取学科数据
data = redis_cli.get('vote:polls:subjects')
if data:
# 如果获取到学科数据就进行反序列化操作
data = json.loads(data)
else:
# 如果缓存中没有获取到学科数据就查询数据库
queryset = Subject.objects.all()
data = SubjectSerializer(queryset, many=True).data
# 将查到的学科数据序列化后放到缓存中
redis_cli.set('vote:polls:subjects', json.dumps(data), ex=86400)
return Response({'code': 20000, 'subjects': data})
```
需要说明的是,Django框架提供了
`cache`
和
`caches`
两个现成的变量来支持缓存操作,前者访问的是默认的缓存(名为
`default`
的缓存),后者可以通过索引运算获取指定的缓存服务(例如:
`caches['default']`
)。向
`cache`
对象发送
`get`
和
`set`
消息就可以实现对缓存的读和写操作,但是这种方式能做的操作有限,不如上面代码中使用的方式灵活。还有一个值得注意的地方,由于可以通过
`get_redis_connection`
函数获得的Redis连接对象向Redis发起各种操作,包括
`FLUSHDB`
、
`SHUTDOWN`
等危险的操作,所以在实际商业项目开发中,一般都会对
`django-redis`
再做一次封装,例如封装一个工具类,其中只提供了项目需要用到的缓存操作的方法,从而避免了直接使用
`get_redis_connection`
的潜在风险。当然,自己封装对缓存的操作还可以使用“Read Through”和“Write Through”的方式实现对缓存的更新,这个在下面会介绍到。
### 缓存相关问题
#### 缓存数据的更新
在使用缓存时,一个必须搞清楚的问题就是,当数据改变时,如何更新缓存中的数据。通常更新缓存有如下几种套路,分别是:
1.
Cache Aside Pattern
2.
Read/Write Through Pattern
3.
Write Behind Caching Pattern
第1种方式的具体做法就是,当数据更新时,先更新数据库,再删除缓存。注意,不能够使用先更新数据库再更新缓存的方式,也不能够使用先删除缓存再更新数据库的方式,大家可以自己想一想为什么(考虑一下有并发的读操作和写操作的场景)。当然,先更新数据库再删除缓存的做法在理论上也存在风险,但是发生问题的概率是极低的,所以不少的项目都使用了这种方式。
第1种方式相当于编写业务代码的开发者要自己负责对两套存储系统(缓存和关系型数据库)的操作,代码写起来非常的繁琐。第2种方式的主旨是将后端的存储系统变成一套代码,对缓存的维护封装在这套代码中。其中,Read Through指在查询操作中更新缓存,也就是说,当缓存失效的时候,由缓存服务自己负责对数据的加载,从而对应用方是透明的;而Write Through是指在更新数据时,如果没有命中缓存,直接更新数据库,然后返回。如果命中了缓存,则更新缓存,然后再由缓存服务自己更新数据库(同步更新)。刚才我们说过,如果自己对项目中的Redis操作再做一次封装,就可以实现“Read Through”和“Write Through”模式,这样做虽然会增加工作量,但无疑是一件“一劳永逸”且“功在千秋”的事情。
第3种方式是在更新数据的时候,只更新缓存,不更新数据库,而缓存服务这边会
**异步的批量更新**
数据库。这种做法会大幅度提升性能,但代价是牺牲数据的
**强一致性**
。第3种方式的实现逻辑比较复杂,因为他需要追踪有哪数据是被更新了的,然后再批量的刷新到持久层上。
#### 缓存穿透
缓存是为了缓解数据库压力而添加的一个中间层,如果恶意的访问者频繁的访问缓存中没有的数据,那么缓存就失去了存在的意义,瞬间所有请求的压力都落在了数据库上,这样会导致数据库承载着巨大的压力甚至连接异常,类似于分布式拒绝服务攻击(DDoS)的做法。解决缓存穿透的一个办法是约定如果查询返回为空值,把这个空值也缓存起来,但是需要为这个空值的缓存设置一个较短的超时时间,毕竟缓存这样的值就是对缓存空间的浪费。另一个解决缓存穿透的办法是使用布隆过滤器,具体的做法大家可以自行了解。
#### 缓存击穿
在实际的项目中,可能存在某个缓存的key某个时间点过期,但恰好在这个时间点对有对该key的大量的并发请求过来,这些请求没有从缓存中找到key对应的数据,就会直接从数据库中获取数据并写回到缓存,这个时候大并发的请求可能会瞬间把数据库压垮,这种现象称为缓存击穿。比较常见的解决缓存击穿的办法是使用互斥锁,简单的说就是在缓存失效的时候,不是立即去数据库加载数据,而是先设置互斥锁(例如:Redis中的setnx),只有设置互斥锁的操作成功的请求,才能执行查询从数据库中加载数据并写入缓存,其他设置互斥锁失败的请求,可以先执行一个短暂的休眠,然后尝试重新从缓存中获取数据,如果缓存还没有数据,则重复刚才的设置互斥锁的操作,大致的参考代码如下所示。
```
Python
data = redis_cli.get(key)
while not data:
if redis_cli.setnx('mutex', 'x'):
redis.expire('mutex', timeout)
data = db.query(...)
redis.set(key, data)
redis.delete('mutex')
else:
time.sleep(0.1)
data = redis_cli.get(key)
```
#### 缓存雪崩
缓存雪崩是指在将数据放入缓存时采用了相同的过期时间,这样就导致缓存在某一时刻同时失效,请求全部转发到数据库,导致数据库瞬时压力过大而崩溃。解决缓存雪崩问题的方法也比较简单,可以在既定的缓存过期时间上加一个随机时间,这样可以从一定程度上避免不同的key在同一时间集体失效。还有一种办法就是使用多级缓存,每一级缓存的过期时间都不一样,这样的话即便某个级别的缓存集体失效,但是其他级别的缓存还能够提供数据,避免所有的请求都落到数据库上。
\ No newline at end of file
Day41-55/52.接入三方平台.md
浏览文件 @
395d37d4
## 接入三方平台
在Web应用的开发过程中,有一些任务并不是我们自己能够完成的。
在Web应用的开发过程中,有一些任务并不是我们自己能够完成的。例如,我们的Web项目中需要做个人或企业的实名认证,很显然我们并没有能力判断用户提供的认证信息的真实性,这个时候我们就要借助三方平台提供的服务来完成该项操作。再比如说,我们的项目中需要提供在线支付功能,这类业务通常也是借助支付网关来完成而不是自己去实现,我们只需要接入像微信、支付宝、银联这样的三方平台即可。
在项目中接入三方平台基本上就两种方式:API接入和SDK接入。
1.
API接入指的是通过访问三方提供的URL来完成操作或获取数据。国内有很多这样的平台提供了大量常用的服务,例如
[
聚合数据
](
https://www.juhe.cn/
)
上提供了生活服务类、金融科技类、交通地理类、充值缴费类等各种类型的API。我们可以通过Python程序发起网络请求,通过访问URL获取数据,这些API接口跟我们项目中提供的数据接口是一样的,只不过我们项目中的API是供自己使用的,而这类三方平台提供的API是开放的。当然开放并不代表免费,大多数能够提供有商业价值的数据的API都是需要付费才能使用的。
2.
SDK接入指的是通过安装三方库并使用三方库封装的类、函数来使用三方平台提供的服务的方式。例如我们刚才说到的接入支付宝,就需要先安装支付宝的SDK,然后通过支付宝封装的类和方法完成对支付服务的调用。
下面我们通过具体的例子来讲解如何接入三方平台。
### 接入短信网关
一个Web项目有很多地方都可以用到短信服务,例如:手机验证码登录、重要消息提醒、产品营销短信等。要实现发送短信的功能,可以通过接入短信网关来实现,国内比较有名的短信网关包括:云片短信、网易云信、螺丝帽、SendCloud等,这些短信网关一般都提供了免费试用功能。下面我们以
[
螺丝帽
](
https://luosimao.com/
)
平台为例,讲解如何在项目中接入短信网关,其他平台操作基本类似。
1.
注册账号,新用户可以免费试用。
2.
登录到管理后台,进入短信版块。
3.
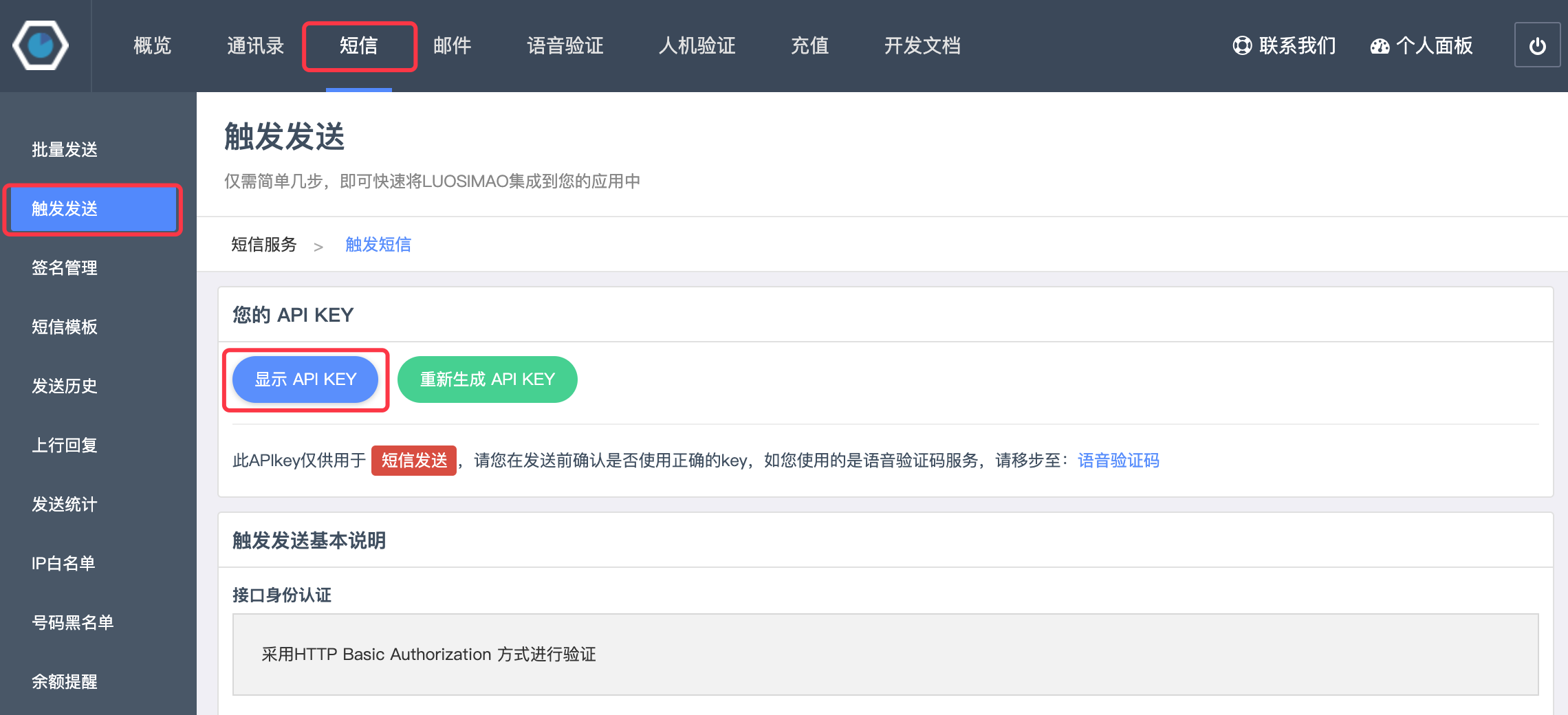
点击“触发发送”可以找到自己专属的API Key(身份标识)。

4.
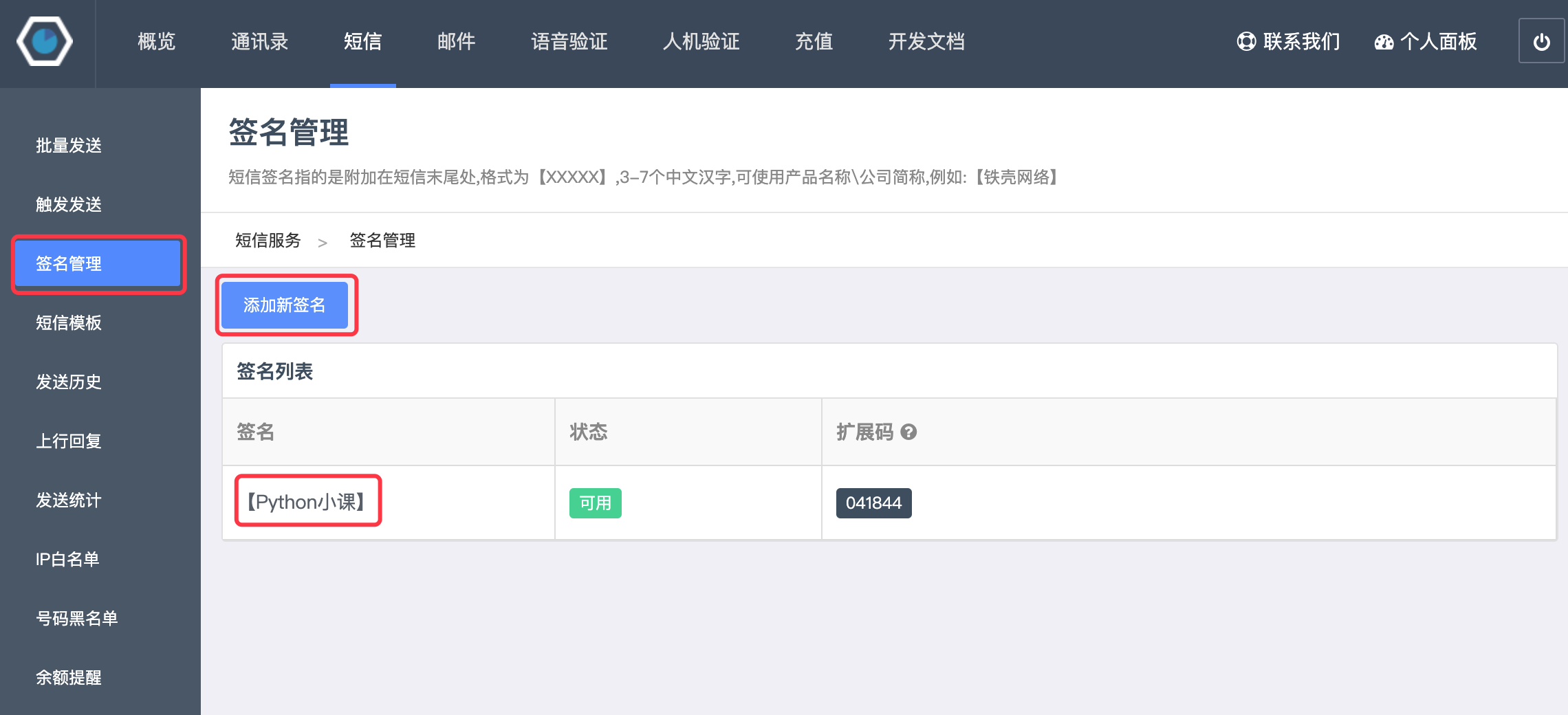
点击“签名管理”可以添加短信签名,短信都必须携带签名,免费试用的短信要在短信中添加“【铁壳测试】”这个签名,否则短信无法发送。

5.
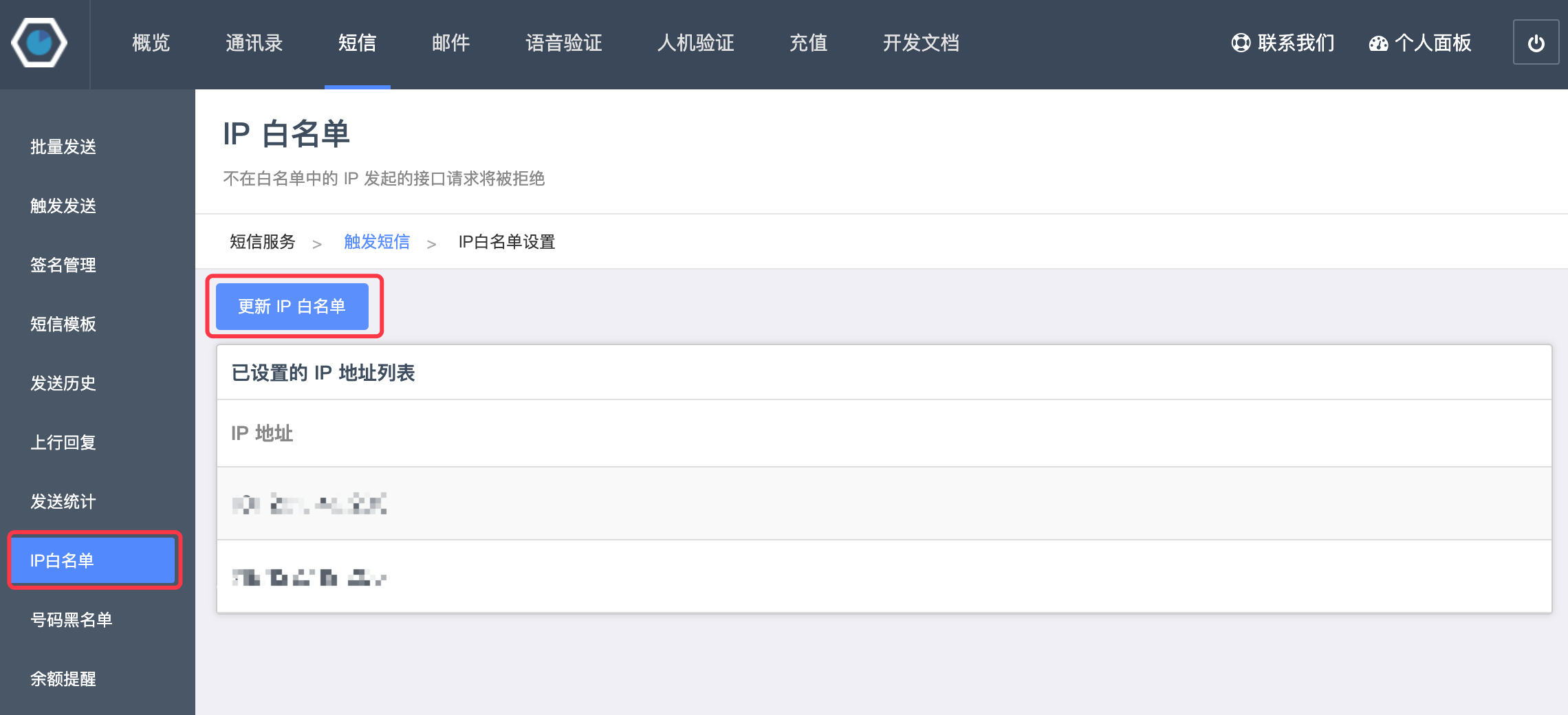
点击“IP白名单”将运行Django项目的服务器地址(公网IP地址,本地运行可以打开
[
xxx
](
)网站查看自己本机的公网IP地址)填写到白名单中,否则短信无法发送。

6.
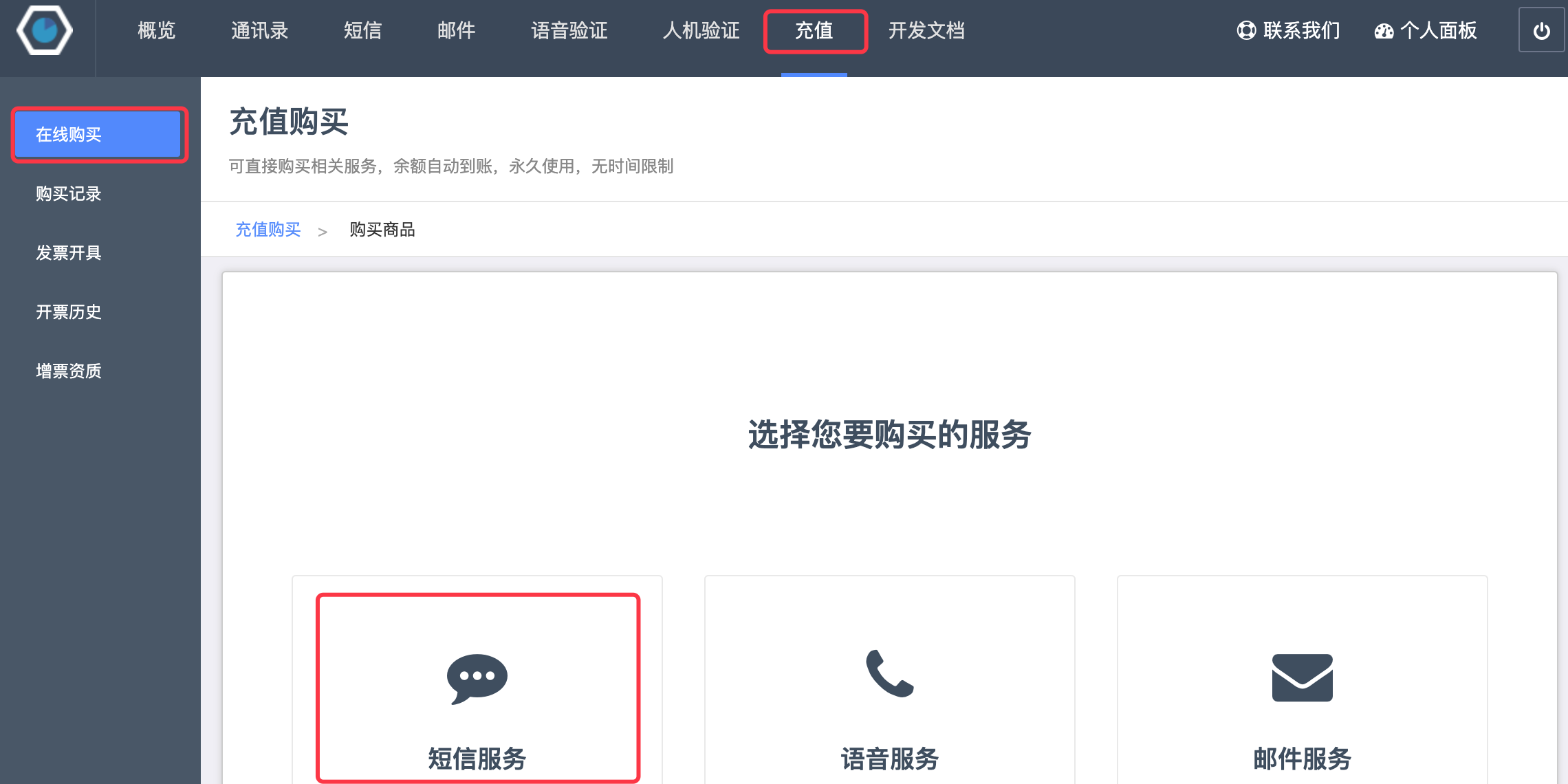
如果没有剩余的短信条数,可以到“充值”页面选择“短信服务”进行充值。

接下来,我们可以通过调用螺丝帽短信网关实现发送短信验证码的功能,代码如下所示。
```
Python
def send_mobile_code(tel, code):
"""发送短信验证码"""
resp = requests.post(
url='http://sms-api.luosimao.com/v1/send.json',
auth=('api', 'key-自己的APIKey'),
data={
'mobile': tel,
'message': f'您的短信验证码是{code},打死也不能告诉别人哟。【Python小课】'
},
verify=False
)
return resp.json()
```
运行上面的代码需要先安装
`requests`
三方库,这个三方库封装了HTTP网络请求的相关功能,使用起来非常的简单,我们在之前的内容中也讲到过这个三方库。
`send_mobile_code`
函数有两个参数,第一个参数是手机号,第二个参数是短信验证码的内容,第5行代码需要提供自己的API Key,就是上面第2步中查看到的自己的API Key。请求螺丝帽的短信网关会返回JSON格式的数据,对于上面的代码如果返回
`{'err': 0, 'msg': 'ok'}`
,则表示短信发送成功,如果
`err`
字段的值不为
`0`
而是其他值,则表示短信发送失败,可以在螺丝帽官方的
[
开发文档
](
https://luosimao.com/docs/api/
)
页面上查看到不同的数值代表的含义,例如:
`-20`
表示余额不足,
`-32`
表示缺少短信签名。
可以在视图函数中调用上面的函数来完成发送短信验证码的功能,稍后我们可以把这个功能跟用户注册结合起来。
生成随机验证码和验证手机号的函数。
```
Python
import random
import re
TEL_PATTERN = re.compile(r'1[3-9]\d{9}')
def check_tel(tel):
"""检查手机号"""
return TEL_PATTERN.fullmatch(tel) is not None
def random_code(length=6):
"""生成随机短信验证码"""
return ''.join(random.choices('0123456789', k=length))
```
发送短信验证码的视图函数。
```
Python
@api_view(('GET', ))
def get_mobilecode(request, tel):
"""获取短信验证码"""
if check_tel(tel):
redis_cli = get_redis_connection()
if redis_cli.exists(f'vote:block-mobile:{tel}'):
data = {'code': 30001, 'message': '请不要在60秒内重复发送短信验证码'}
else:
code = random_code()
send_mobile_code(tel, code)
# 通过Redis阻止60秒内容重复发送短信验证码
redis_cli.set(f'vote:block-mobile:{tel}', 'x', ex=60)
# 将验证码在Redis中保留10分钟(有效期10分钟)
redis_cli.set(f'vote2:valid-mobile:{tel}', code, ex=600)
data = {'code': 30000, 'message': '短信验证码已发送,请注意查收'}
else:
data = {'code': 30002, 'message': '请输入有效的手机号'}
return Response(data)
```
> **说明**:上面的代码利用Redis实现了两个额外的功能,一个是阻止用户60秒内重复发送短信验证码,一个是将用户的短信验证码保留10分钟,也就是说这个短信验证码的有效期只有10分钟,我们可以要求用户在注册时提供该验证码来验证用户手机号的真实性。
### 接入云存储服务
Day41-55/53.异步任务和定时任务.md
浏览文件 @
395d37d4
## 异步任务和定时任务
在Web应用中,如果一个请求执行了耗时间的操作或者该请求的执行时间无法确定,而且对于用户来说只需要知道服务器接收了他的请求,并不需要马上得到请求的执行结果,这样的操作我们就应该对其进行异步化处理。如果说
**使用缓存是优化网站性能的第一要义**
,那么将耗时间或执行时间不确定的任务
**异步化则是网站性能优化的第二要义**
,简单的说就是
**能推迟做的事情都不要马上做**
。
上一章节中讲到的发短信和上传文件到云存储为例,这两个操作前者属于时间不确定的操作(因为作为调用者,我们不能确定三方平台响应的时间),后者属于耗时间的操作(如果文件较大或者三方平台不稳定,都可能导致上传的时间较长),很显然,这两个操作都可以做异步化处理。
在Python项目中实现异步化处理可以使用多线程或借助三方库Celery来完成。
### 使用Celery实现异步化
### 使用多线程实现异步化
Day41-55/54.单元测试.md
浏览文件 @
395d37d4
## 单元测试
和项目上线
## 单元测试
Python标准库中提供了名为
`unittest`
的模块来支持我们对代码进行单元测试。所谓单元测试是指针对程序中最小的功能单元(在Python中指函数或类中的方法)进行的测试。
Day41-55/55.项目上线.md
浏览文件 @
395d37d4
## 项目上线
### 上线前的检查工作
### 同步代码到云服务器
### WSGI服务器的应用
### Nginx的相关配置
请各位读者移步到
[
《项目部署上线和性能调优》
](
../Day91-100/98.项目部署上线和性能调优.md
)
一文。
Day41-55/res/luosimao-pay-onlinebuy.png
0 → 100644
浏览文件 @
395d37d4
164.7 KB
Day41-55/res/luosimao-sms-apikey.png
0 → 100644
浏览文件 @
395d37d4
209.8 KB
Day41-55/res/luosimao-sms-signature.png
0 → 100644
浏览文件 @
395d37d4
173.9 KB
Day41-55/res/luosimao-sms-whitelist.png
0 → 100644
浏览文件 @
395d37d4
159.0 KB
Day41-55/res/redis-cache-service.png
0 → 100644
浏览文件 @
395d37d4
64.7 KB
Day91-100/93.MySQL性能优化.md
浏览文件 @
395d37d4
...
...
@@ -79,22 +79,32 @@ MySQL支持做数据分区,通过分区可以存储更多的数据、优化查
+-----------------+-----------+
```
-
创建慢查询日志文件并修改所有者。
```Bash
touch /var/log/mysqld-slow.log
chown mysql /var/log/mysqld-slow.log
```
-
修改全局慢查询日志配置。
```SQL
mysql> set global slow_query_log_file='/var/log/mysqld-slow.log'
mysql> set global slow_query_log='ON';
mysql> set global long_query_time=1;
```
或者直接修改MySQL配置文件启用慢查询日志。
```
或者直接修改MySQL配置文件启用慢查询日志。
```INI
[mysqld]
slow_query_log=ON
slow_query_log_file=/
usr/local/mysql/data/
slow.log
slow_query_log_file=/
var/log/mysqld-
slow.log
long_query_time=1
```
> **注意**:修改了配置文件需要重启MySQL,CentOS上对应的命令是`systemctl restart mysqld`。
2. 通过`explain`了解SQL的执行计划。例如:
```
SQL
...
...
README.md
浏览文件 @
395d37d4
...
...
@@ -282,7 +282,7 @@ Python在以下领域都有用武之地。
-
使用装饰器实现页面缓存
-
为数据接口提供缓存服务
#### Day52 - [
文件上传](./Day41-55/52.文件上传
.md)
#### Day52 - [
接入三方平台](./Day41-55/52.接入三方平台
.md)
-
文件上传表单控件和图片文件预览
-
服务器端如何处理上传的文件
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
