
create pro
Showing
README.md
0 → 100644
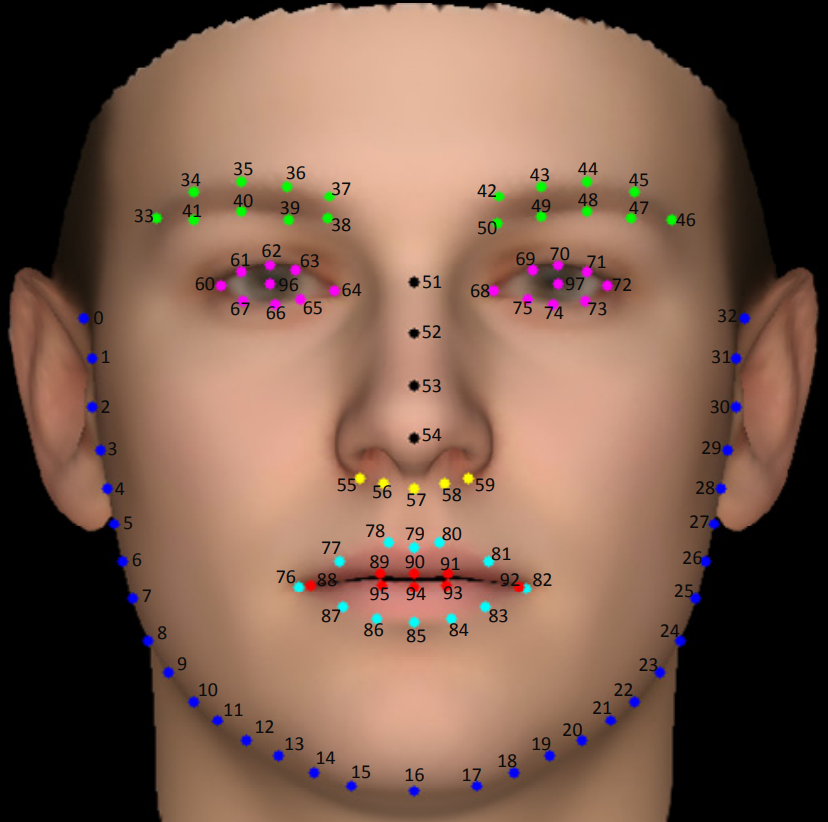
WFLW_annotation.png
0 → 100644
{kind=link}
354.1 KB
data_iter/data_agu.py
0 → 100644
data_iter/datasets.py
0 → 100644
image/1.jpg
0 → 100644
{kind=link}

9.1 KB
image/10.jpg
0 → 100644
{kind=link}

41.3 KB
image/11.jpg
0 → 100644
{kind=link}

13.4 KB
image/12.jpg
0 → 100644
{kind=link}

6.9 KB
image/2.jpg
0 → 100644
{kind=link}

8.5 KB
image/3.jpg
0 → 100644
{kind=link}

10.1 KB
image/4.jpg
0 → 100644
{kind=link}

11.6 KB
image/5.jpg
0 → 100644
{kind=link}

12.8 KB
image/6.jpg
0 → 100644
{kind=link}

11.3 KB
image/7.jpg
0 → 100644
{kind=link}

7.6 KB
image/8.jpg
0 → 100644
{kind=link}

16.6 KB
image/9.jpg
0 → 100644
{kind=link}

13.9 KB
inference.py
0 → 100644
loss/loss.py
0 → 100644
models/resnet.py
0 → 100644
samples/1.jpg
0 → 100644
{kind=link}

21.7 KB
samples/10.jpg
0 → 100644
{kind=link}

87.3 KB
samples/11.jpg
0 → 100644
{kind=link}

30.0 KB
samples/12.jpg
0 → 100644
{kind=link}

16.3 KB
samples/2.jpg
0 → 100644
{kind=link}

18.4 KB
samples/3.jpg
0 → 100644
{kind=link}

22.8 KB
samples/4.jpg
0 → 100644
{kind=link}

26.2 KB
samples/5.jpg
0 → 100644
{kind=link}

28.7 KB
samples/6.jpg
0 → 100644
{kind=link}

25.6 KB
samples/7.jpg
0 → 100644
{kind=link}

18.5 KB
samples/8.jpg
0 → 100644
{kind=link}

36.8 KB
samples/9.jpg
0 → 100644
{kind=link}

30.1 KB
train.py
0 → 100644
utils/common_utils.py
0 → 100644
utils/model_utils.py
0 → 100644