Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
Crayon鑫
Paddle
提交
bb5fb0de
P
Paddle
项目概览
Crayon鑫
/
Paddle
与 Fork 源项目一致
Fork自
PaddlePaddle / Paddle
通知
1
Star
1
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
1
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
Paddle
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
1
Issue
1
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
bb5fb0de
编写于
3月 27, 2017
作者:
Y
yi.wu
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
update
上级
3023c652
变更
7
隐藏空白更改
内联
并排
Showing
7 changed file
with
72 addition
and
113 deletion
+72
-113
doc/design/cluster_design.md
doc/design/cluster_design.md
+72
-113
doc/design/images/arch.png
doc/design/images/arch.png
+0
-0
doc/design/images/checkpointing.png
doc/design/images/checkpointing.png
+0
-0
doc/design/images/less_trainer.png
doc/design/images/less_trainer.png
+0
-0
doc/design/images/master.png
doc/design/images/master.png
+0
-0
doc/design/images/more_trainer.png
doc/design/images/more_trainer.png
+0
-0
doc/design/images/trainer.graffle
doc/design/images/trainer.graffle
+0
-0
未找到文件。
doc/design/cluster_design.md
浏览文件 @
bb5fb0de
...
@@ -26,145 +26,104 @@
...
@@ -26,145 +26,104 @@
1.
为了支持大量的训练任务和使用模型的应用在一个集群上,需要支持训练任务节点的伸缩。
1.
为了支持大量的训练任务和使用模型的应用在一个集群上,需要支持训练任务节点的伸缩。
1.
支持训练任务的前置任务和后置任务,支持训练任务的定时调度和对在线流式数据的处理
1.
支持训练任务的前置任务和后置任务,支持训练任务的定时调度和对在线流式数据的处理
## 模型参数数据备份
## 模型参数检查点(Checkpointing)
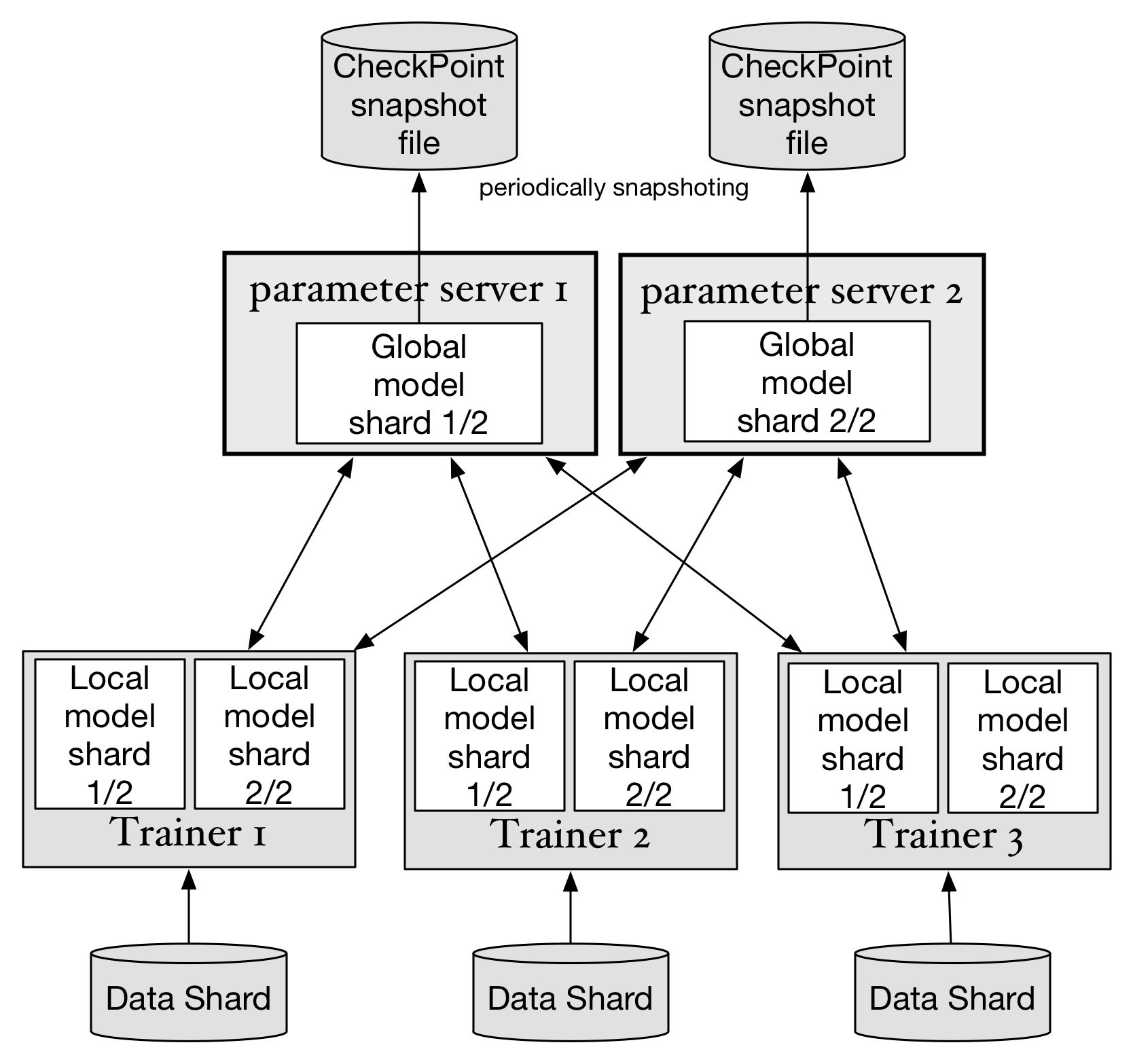
为了实现parameter server集群可以容忍单点故障,须将每个模型参数的分片在集群中存储多个副本。虽然也可以考虑使用校验和的技术减少副本大小,但为了整体系统的简单,优先选择使用副本的方式。
模型数据检查点的实现,可以有效的避免parameter server的单点或多点同时故障。模型参数检查点通过定期向磁盘上保存一份存储在parameter server内存中的模型数据的完整镜像,来保证训练过程可以从中间状态重新启动。在一个不可中断并缺少备份的训练任务中,可以通过阶段性的在每个parameter server的
***本地磁盘/分布式存储挂载点**
*
保存检查点快照达到容灾的目的,比如每个pass或每n个mini-batch保存一次快照。在出现单点故障时,只需要恢复这台节点,或者将这台节点迁移到另一个节点并启动即可恢复训练任务。
<img
src=
"images/replica.png"
width=
"500"
/>
<img
src=
"images/checkpointing.png"
width=
"500"
/>
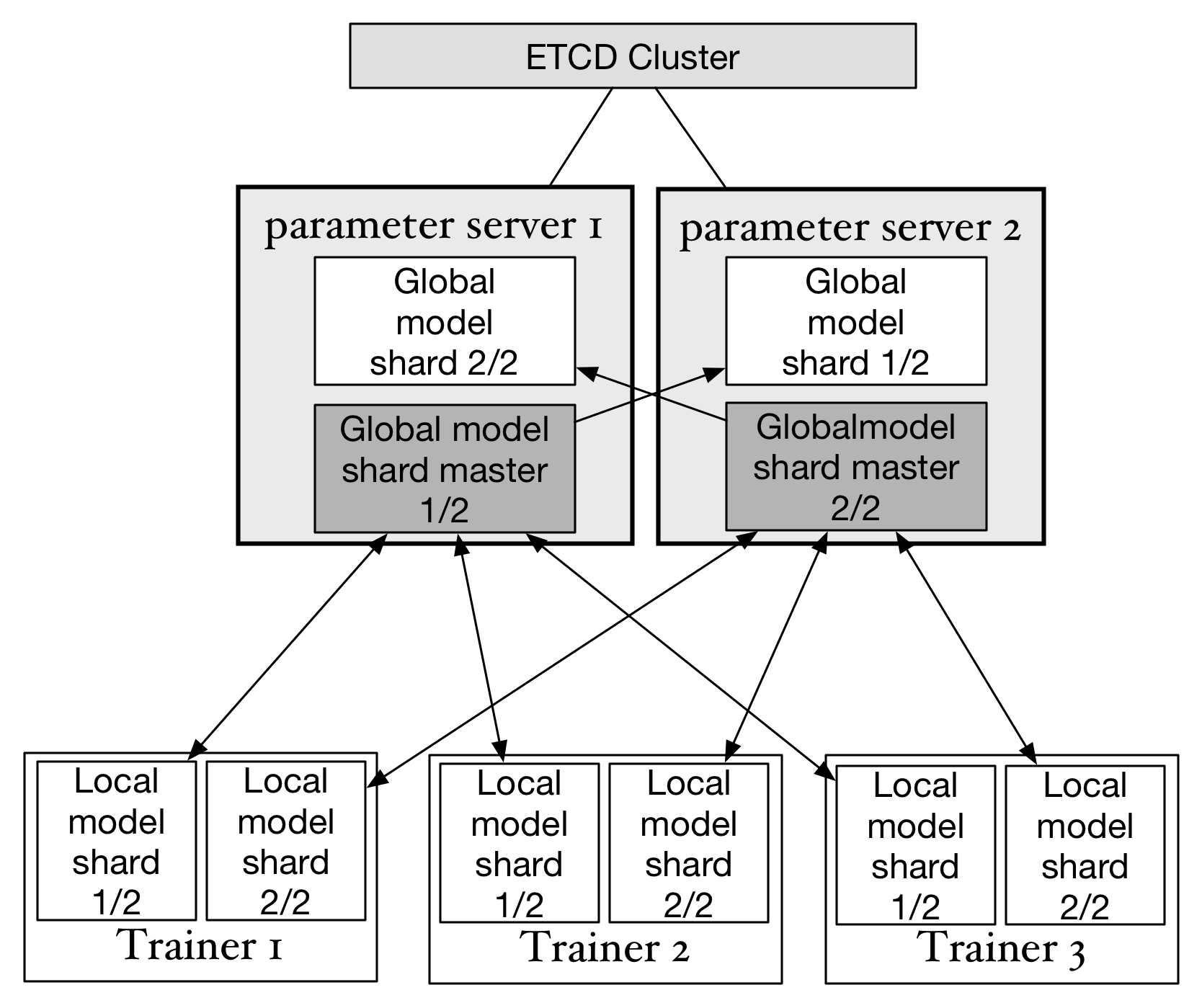
上图显示了在3台parameter server中实现每个模型参数的分片均保存两个副本的状态。parameter 负责存储
### 快照保存的设计如下:
所有参数分片副本并在etcd中同步每个副本的状态。每个分片的多个副本中同时只有一个处于"master"状态,
处于"master"状态的副本是当前活动的副本。当一台parameter server故障时,集群中剩下的parameter server
前置要求:
会重新选举出新的"master"副本并继续提供服务。比如如果parameter server 3故障,仍然可以从parameter server 1和2中找出完整的3个副本。此时虽然性能会临时降低,但可以确保训练任务继续运行,只要有新的parameter server上线,并完成副本的重新分布,就可以恢复原先的集群状态。
*
所有parameter server在etcd上注册自己的id节点为TTL节点
`/paddle/pservers/[id]`
,并保持心跳。同时使用watcher监听
`/paddle/pservers`
目录,监听parameter server增加或丢失的消息。
*
所有trainers在etcd
`/paddle/trainers/[id]`
下注册节点。并监听暂停信号:
`/paddle/trainers/pause`
(监听节点创建和删除),
`re-fetch`
信号。trainer在收到pause创建的信号之后,需要保存trainer的reader所读取的文件信息(文件名/文件元数据),和读取的offset到:
`/paddle/trainers/[id]`
的内容中。
用户在启动parameter server是可以指定副本的个数(>=1),副本越多容灾能力越强,越少性能越好。但通常不会
使用>3个的副本配置。
程序流程:
1.
满足条件""每个pass或每n个mini-batch"时,parameter server原子写入
`/paddle/trainers/pause`
暂停所有trainer上传新的梯度
etcd中数据存储格式为:
2.
parameter server在etcd服务中创建
`/paddle/checkpoints/[snapshot uuid]/[parameter server id]`
TTL节点,标识快照开始更新。然后开始向磁盘/存储服务中一个新的文件写入快照数据,并在写入过程中定时更新 etcd的checkpoint TTL节点已保证心跳。
1.
pserver集群状态
`[CLUSTER_CHROOT]/pserver_cluster_status`
3.
任意一个parameter server完成检查点更新后,创建etcd目录
`/paddle/checkpoints/[snapshot uuid]/finished/[parameter server id]`
,写入完成的timestamp。然后检查是否所有的parameter server都完成。如果是,跳到第5步;否则循环等待。
```
json
4.
如果在任意时间点,收到parameter server增加或丢失的消息,则需要回滚整个集群训练过程到上一个检查点:
{
"cluster_status"
:
"OK|UNHEALTHY|UNKNOWN"
*
如果没有处在暂停状态,则暂停所有的参数更新
"reason"
:
""
,
*
删除etcd中
`/paddle/checkpoints/[snapshot uuid]`
的路径,清理没有成功执行的检查点任务。
"nodes"
:
[
0
,
1
,
2
,
3
]
*
从etcd中读取检查点的uuid和timestamp,然后解析所有存储在磁盘上的检查点文件(可能有多个文件),判断对应uuid是否相同,如果都不同,则报错退出(FATAL error)。如果有相同的文件,则加载这个检查点文件,并覆盖内存中的参数。
}
*
原子性创建etcd节点:
`/paddle/trainer/re-fetch`
(即多个parameter server不重复创建),通知trainer重新获取参数
```
*
删除
`/paddle/trainers/pause`
节点,重新开启训练过程,trainer需要从
`/paddle/checkpoints/latest`
中找到上一个检查点的file和对应的offset,并将reader重新设置到这个位置。
1.
每个pserver的状态: [CLUSTER_CHROOT]/pservers/[pserverid]
5.
尝试获取
`/paddle/checkpoints/finish_lock`
分布式锁(使用etcd3或者客户端wrapper)。获取锁之后,更新
`/paddle/checkpoints/latest`
的内容为最新的checkpoint的uuid,timestamp;从
`/paddle/trainers/[id]`
中获取file和offset并更新到
`/paddle/checkpoints/latest/files/[id]`
中;删除每个pserver的上一个snapshot文件;释放锁;删除
`/paddle/trainers/pause`
节点。
```
json
{
"id"
:
0
,
"instance"
:
"pserver1"
,
"status"
:
"up"
,
"start_time"
:
1490184573.25
,
"sync"
:
true
,
}
```
1.
parameter分片信息: [CLUSTER_CHROOT]/pshards/[shardid]/[replicaid]
比如上图显示的分片将生成下面的4个etcd路径:
```
bash
/pshards/0/0
/pshards/0/1
/pshards/1/0
/pshards/1/1
```
每个replica的信息如下:
```
json
{
"id"
:
0
,
"shardid"
:
0
,
"created"
:
1490184573.25
,
"modified"
:
1490184573.25
,
"status"
:
"master"
,
#
indicates
the
replica
is
in
use
}
```
## 数据一致性
存在多个副本数据的情况下就需要考虑多个副本之间的数据一致性。如果使用数据强一致性(例如paxos/raft或两段式提交),
则在故障恢复时可以获得一个完整的数据集,但每次更新模型参数的性能会下降,因为需要保证多个副本都完全更新之后才算更新
成功。如果使用异步同步(最终一致性),则在重新选举"master"副本时,可能得到的副本并没有完成数据同步。
本文档讨论使用两阶段提交(2PC)实现模型副本数据的更新。
*
每个副本通常由多个parameter block组成,多个block之间可以并发更新,但更新同一个block需要保证顺序性。
*
每次需要更新一个block的时候,trainer首先向存放"master"副本的服务器提交“准备更新”请求,"master"副本检查其他副本的状态并创建一个更新事务,然后返回OK。
*
trainer再向"master"发送变化部分的梯度数据和这份数据的id,然后"master"并发的更新本地和其他副本的模型数据,更新成功返回OK,如果有更新失败的节点,则执行"rollback",退回到更新前状态并返回错误代码。
<img
src=
"images/two_phase_commit.png"
width=
"500"
/>
## 模型数据检查点(Checkpointing)
模型数据检查点,可以在磁盘上保存一份存储在parameter server内存中的模型数据的完整镜像。在一个不可中断并缺少备份的训练任务中,可以通过阶段性的在每个parameter server的
***本地磁盘/分布式存储挂载点**
*
保存检查点快照达到容灾的目的,比如每个pass或每n个mini-batch保存一次快照。在出现单点故障时,只需要恢复这台节点,或者将这台节点迁移到另一个节点并启动即可恢复训练任务。
这里需要用户额外注意,在您的实际环境中,训练任务的运行可能会占满trainer和parameter server之间的网络带宽,如果parameter server此时还需要通过网络访问分布式存储以保存快照,可能会造成网络拥塞,而出现阶段性的运行停滞。
这里需要用户额外注意,在您的实际环境中,训练任务的运行可能会占满trainer和parameter server之间的网络带宽,如果parameter server此时还需要通过网络访问分布式存储以保存快照,可能会造成网络拥塞,而出现阶段性的运行停滞。
##
训练数据的存储和分发
##
# ETCD文件一览
生产环境中的训练数据集通常体积很大,并被存储在诸如Hadoop HDFS, Ceph, AWS S3之类的分布式存储之上。这些分布式存储服务通常会把数据切割成多个分片分布式的存储在多个节点之上,而多个trainer通常也需要预先完成文件的切割。但通常的方法是从HDFS上将数据拷贝到训练集群,然后切割到多个trainer服务器上,如图(Mount/Copy):
***注:TTL节点表示这个节点在创建者消失时,在TTL时间内也会消失**
*
<img
src=
"images/trainer_data.png"
width=
"500"
/>
*
`/paddle/pservers/[id]`
: TTL节点。id是parameter server的id,保存parameter server的信息。
*
`/paddle/checkpoints/latest`
: 最新的checkpoint的信息。json格式保存timestamp, uuid
*
`/paddle/checkpoints/latest/files/[trainer id]`
: 保存最新的checkpoint对应的每个trainer读取数据的文件和offset
*
`/paddle/checkpoints/[snapshot uuid]/[parameter server id]`
: TTL节点。uuid是checkpoint生成的唯一snapshot id
*
`/paddle/checkpoints/[snapshot uuid]/finished/[parameter server id]`
: 同上
*
`/paddle/trainers/[id]`
: TTL节点,保存trainer信息。如果发生全局暂停,则节点中以json格式保存trainer正在读取的文件和offset
*
`/paddle/trainers/pause`
: 控制trainer暂停上传梯度
*
`/paddle/trainers/re-fetch`
: 控制trainer重新从parameter server读取参数并覆盖本地参数
考虑到HDFS实际上已经完成了数据切割的任务,而且如果存在前置的数据预处理任务(Map-Reduce或Spark SQL),这些任务的输出也都存放于HDFS之上,则trainer可以直接调用HDFS LowLevel API,从元数据节点获得每个数据分片存储的位置,直接获得分片。
## 训练数据的存储和分发
***注:每个数据分片保存多个mini_batch**
*
### 现在的方法
生产环境中的训练数据集通常体积很大,并被存储在诸如Hadoop HDFS, Ceph, AWS S3之类的分布式存储之上。这些分布式存储服务通常会把数据切割成多个分片分布式的存储在多个节点之上,而多个trainer通常也需要预先完成文件的切割。但通常的方法是从HDFS上将数据拷贝到训练集群,然后切割到多个trainer服务器上,但这样的效率是底下的。如图(Mount/Copy):
进一步优化,trainer可以寻找在物理网络拓扑中离自己最近的一个分片副本获取数据。
<img
src=
"images/trainer_data.png"
width=
"500"
/>
trainer和训练数据分片的均衡:
### 期望的方法
*
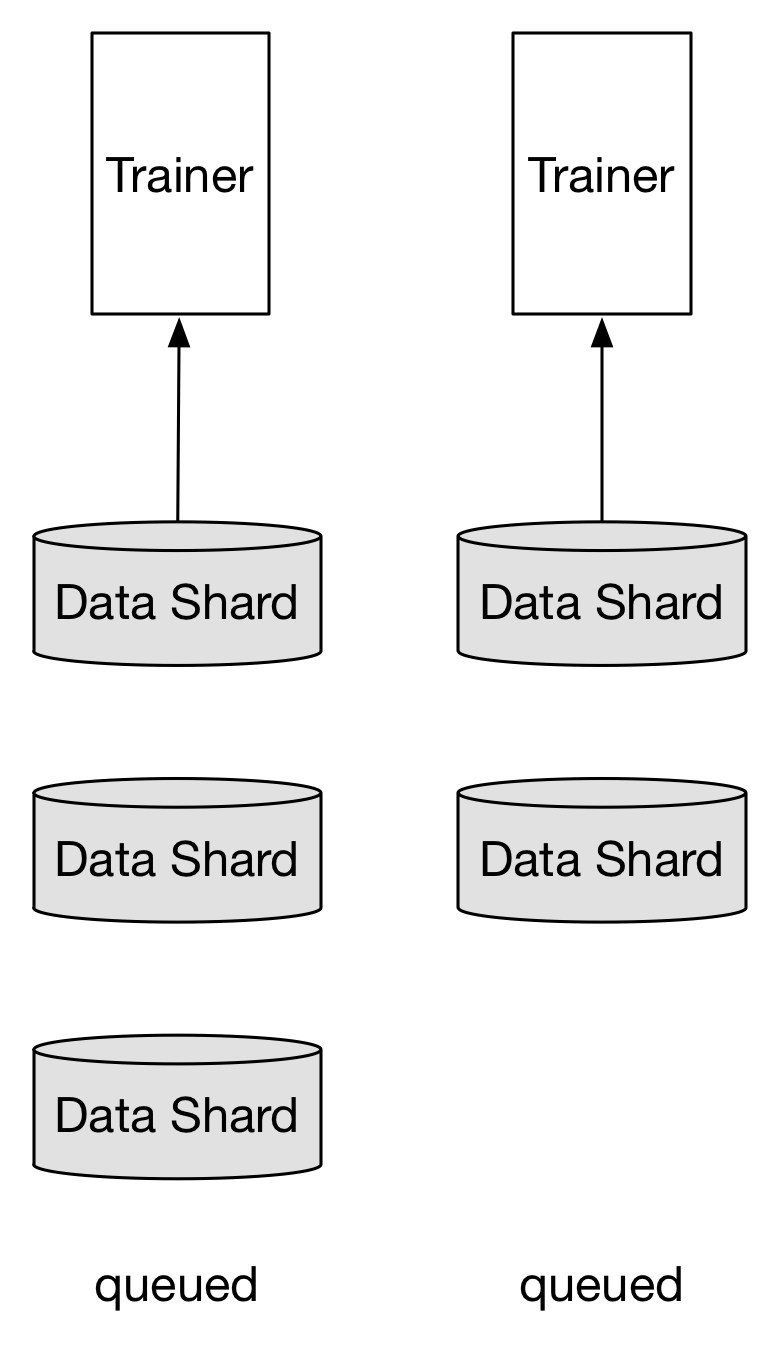
当trainer >= 数据分片:
trainer个数和数据分片个数相同时,可以获得最高的吞吐量。当trainer个数再大于分片数量时,必然有Trainer获取不到数据分片,处于等待状态。但对整体任务运行没有影响,等待的trainer也会消耗很小的资源。
<img
src=
"images/more_trainer.png"
width=
"500"
/>
考虑到HDFS实际上已经完成了数据切割的任务,而且如果存在前置的数据预处理任务(Map-Reduce或Spark SQL),这些任务的输出也都存放于HDFS之上,则trainer可以直接调用HDFS LowLevel API,从元数据节点获得每个数据分片存储的位置,直接获得分片。
*
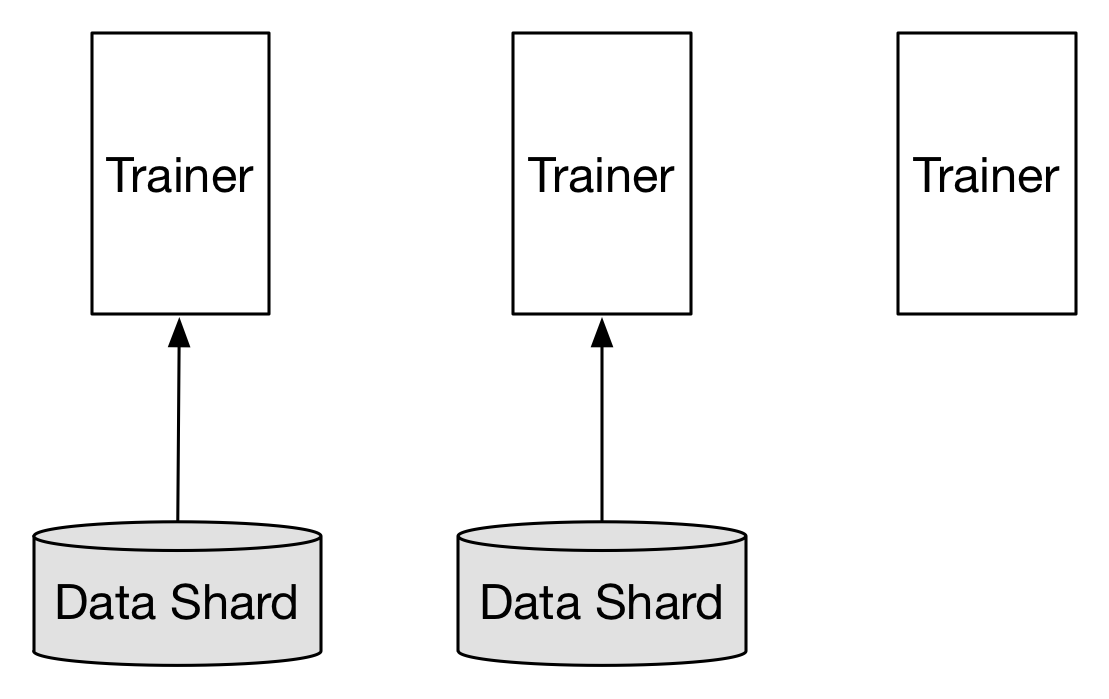
当trainer < 数据分片
***注:每个数据分片保存多个mini_batch**
*
每个trainer负责多个数据分片,轮询方式完成一个分片训练之后开始下一个分片。
<img
src=
"images/less_trainer.png"
align=
"center"
height=
"500"
/>
我们将使用如下的设计完成数据分发:
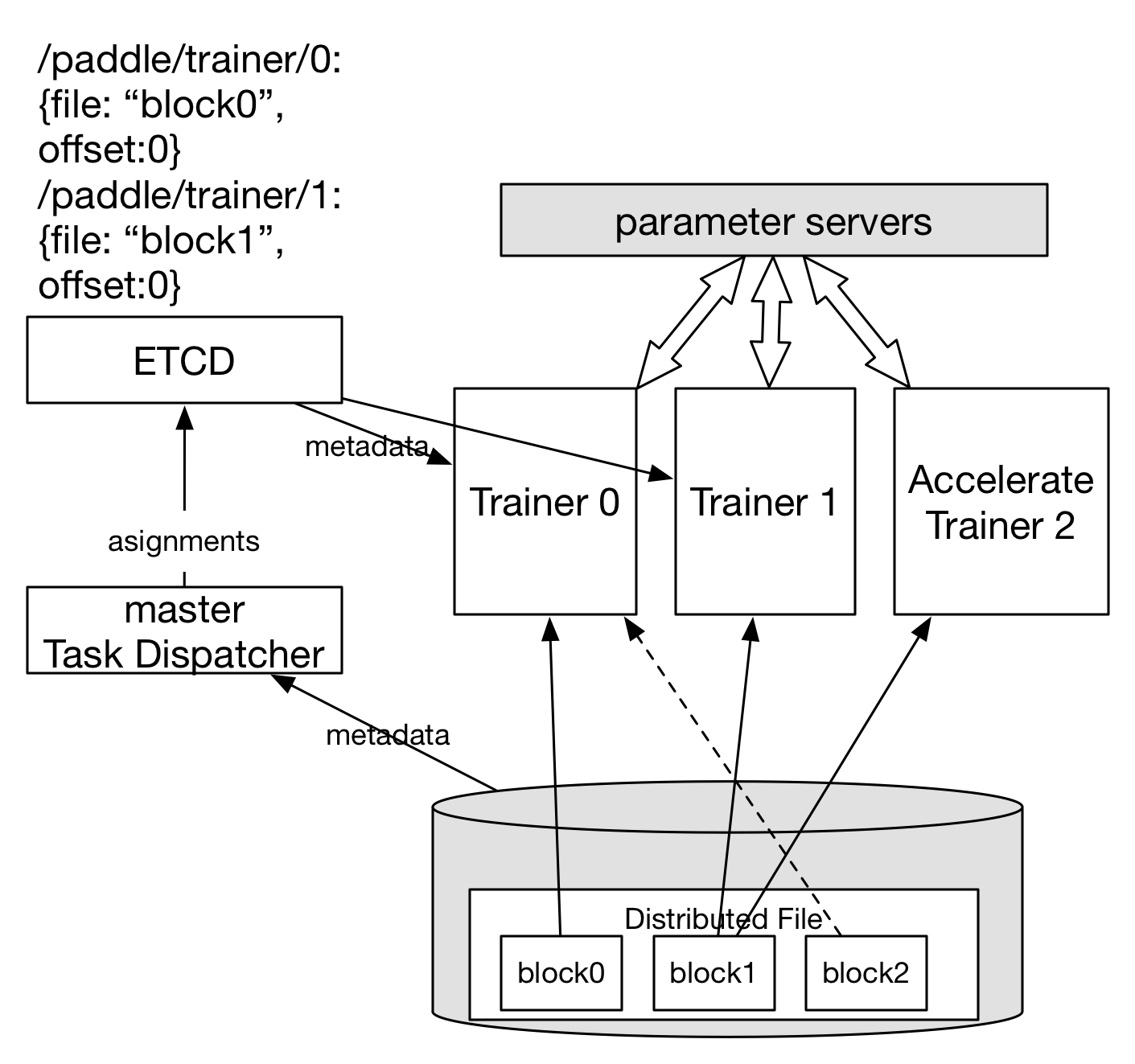
## 故障恢复
<img
src=
"images/master.png"
width=
"500"
/>
在通用集群上运行的应用和任务,通常需要有能够自动伸缩的能力,这样在在线集群进行扩容时,可以适当的减小训练任务的资源(进程数/并发数),而不需要直接停止训练任务,修改参数后重新提交任务。
然而对于常见的在线服务(比如Web服务,RPC服务等),是可以“无状态”伸缩的,即扩容和缩容只需要增删对应的节点,集群能力就可以自动伸缩,Web服务的每个节点不会维护自身的状态变化和自身的数据,这些数据通常会借由外部的存储或服务完成,如MySQL,Redis等。而对于训练任务来说,每个parameter server都需要保存状态(mini-batch id)和数据(parameters),在增删节点的时候都会涉及到数据重新分布(re-sharding)和处理数据同步的问题
。
如图,数据存储在分布式文件系统中,并将预处理之后的文件切割成3个block存储在不同的机器上。在训练任务开始时,master读取这个分布式文件的元数据,并将一个block分配给一个trainer,然后将分配信息写入etcd中。随后trainer从etcd中获取到数据的分配信息并开始执行训练。一个block数据训练完成后,master负责在将新的block分配给一个trainer(途中虚线所示)
。
用户只要根据实际训练任务场景,配置parameter server和trainer的初始节点个数,最大节点个数和最小节点个数,模型副本个数,是否开启检查点等配置项,即可配置并启动一个可以容灾的训练集群。具体的过程如下:
master不会直接发送数据给Trainer而是负责协调训练数据的分配,并以ETCD为协调中心。所以master是一个无状态程序,任务运行过程中,master停止后只需要重新启动即可。
1.
配置parameter server和trainer的初始节点个数、最大节点个数、最小节点个数、模型副本个数、是否开启检查点等配置以及训练任务相关配置。
### 推测执行/加速执行(TODO)
1.
启动parameter server和trainer,每个实例会在etcd中注册一个带TTL(过期时间)的节点,并每隔一段时间(
`<TTL`
)更新这个节点的TTL。这样当某个parameter server或trainer失效时,etcd中的节点会消失,反应的状态。每个parameter server在所有的parameter server上会使用etcd watcher监听节点的变化状态,已完成后续处理。
在异构集群中,如果存在某些trainer执行速度过慢会影响整体集群的速度(如图中Trainer 1),此时master将负责启动一个新的Trainer(Accelerate Trainer 2),使用同样的训练数据block。哪个trainer先完成block的训练,则把另一个慢速的kill掉。
1.
parameter server如果开启了检查点,则先判断是否已经存在本地检查点快照数据,如果有,则从快照数据中加载状态和数据,并开始提供服务。如果没有则执行初始化启动步骤。
1.
提交用户定义的深度学习网络(topology),并根据网络中参数完成pre-sharding,将参数block(每个参数分片由多个参数block组成)哈希到512或1024个slot中,每个slot即为一个参数分片。根据实际存在的parameter server个数,将slot和parameter server完成对应的映射,使slot可以平均存储在这些parameter server上。
1.
parameter server开始监听端口并接收数据。每次接收到数据,都使用两段式提交方式同步到所有的副本。如果需要存储检查点,则在同步所有副本之后,保存检查点。
1.
当其中一台parameter server故障发生后(物理机停机,进程core dump等),其他的parameter server会收到etcd发送的watcher信号:
```
json
{
"event"
:
"removal"
,
"node"
:
{
"createdIndex"
:
1
,
"key"
:
"/mycluster/pservers/3"
,
"modifiedIndex"
:
1
,
"value"
:
"{...json...}"
},
}
```
此时将暂停trainer的训练(此时要检查最后一次参数更新更新的状态,如果处于不同步状态(处于准备或提交但并无提交响应),需要执行rollback),然后执行执行re-sharding步骤:
1.
根据现有存活的parameter server的个数,遍历所有的参数分片,找出那些分片已经丢失master分片,则在分片的副本中重新找出一个选作master。
2.
重新分布每个slot,将slot平均分布在所有parameter server上,保证负载均衡。
3.
重新开始trainer的训练。
新增节点的方法类似,此处不再赘述。
### 关于存储的考虑
*
图像/音频类数据,预处理之后以何种方式分布式存储,如何切割?
*
支持流式数据接口和常规文件接口
*
对不同的分布式存储,需要实现不同的reader wrapper
## 动态扩容/缩容
## 动态扩容/缩容
虽然故障恢复可以提供任意时刻的节点新增和删除仍然可以保证任务正常运行,但通常这样是比较暴力的。为了能graceful的关闭多个节点,
parameter serv
er需要提供对应的API接口:
虽然故障恢复可以提供任意时刻的节点新增和删除仍然可以保证任务正常运行,但通常这样是比较暴力的。为了能graceful的关闭多个节点,
mast
er需要提供对应的API接口:
```
python
```
python
def
resize
(
n
):
def
resize
(
n
):
# do resize
save_checkpoint
()
pause_all_trainers
()
start_and_wait_trainers
(
n
-
self
.
num_trainers
)
start_and_wait_pservers
(
n
-
self
.
num_pservers
)
do_parameter_re_hash
()
trainers_re_fetch
()
start_all_trainers
()
return
success
return
success
```
```
接口完成先发送信号暂停训练任务,re-shard数据分片,然后重新开启训练。这样可以避免程序bug导致的数据不同步问题出现。
要实现
`do_parameter_re_hash()`
,将现有的parameter能够在增加parameter servers时,完成重新分布,需要实现以下的细节:
## 性能考虑
```
由于每次数据提交都需要完成分片同步,而且在每个pass之后执行检查点保存,必然会带来parameter server性能下降。可以根据不同的场景配置不同的容灾方案。
parameters = large vector
<..............................>
|___| |___| |___|
^
|
parameter block
需要:
hash to map to
parameter block --------> 128~1024 slots --------> parameter servers
```
*
测试任务/极短训练任务:如果训练任务在几十分钟或小时级别可以运行完成,可以考虑不开启副本也不开启检查点。
接口完成先发送信号暂停训练任务,保存参数的checkpoint,然后重新开启训练。这样可以避免程序bug导致的数据不同步问题出现。
*
短期训练任务/测试任务:训练任务运行时间如果在数小时或数天范围,可以考虑只使用一个副本(每个slot只保存一份),并开启检查点。在这个时长内出现不可恢复的硬件故障的概率极低。
*
大型训练任务:训练时间以周或月为单位。建议开启多个副本和检查点。这样可以在任意一个pass停止任务,并重新从这个pass开始训练。或者在通用集群运行时,可以考虑动态扩容和缩容。
## 实现考虑
## 实现考虑
由于两阶段提交和数据备份同步、选举部分实现比较复杂,可以考虑使用一些开源库函数,比如2pc,raft库等,后期在优化过程中逐步替换。
由于两阶段提交和数据备份同步、选举部分实现比较复杂,可以考虑使用一些开源库函数,比如2pc,raft库等,后期在优化过程中逐步替换。
...
...
doc/design/images/arch.png
已删除
100644 → 0
浏览文件 @
3023c652
161.2 KB
doc/design/images/checkpointing.png
0 → 100644
浏览文件 @
bb5fb0de
179.1 KB
doc/design/images/less_trainer.png
已删除
100644 → 0
浏览文件 @
3023c652
59.7 KB
doc/design/images/master.png
0 → 100644
浏览文件 @
bb5fb0de
162.2 KB
doc/design/images/more_trainer.png
已删除
100644 → 0
浏览文件 @
3023c652
31.8 KB
doc/design/images/trainer.graffle
浏览文件 @
bb5fb0de
无法预览此类型文件
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}