Merge branch 'develop' of https://github.com/PaddlePaddle/Paddle into add-pserver-util
Showing
.gitmodules
已删除
100644 → 0
cmake/check_packages.cmake
已删除
100644 → 0
cmake/configure.cmake
0 → 100644
cmake/external/gflags.cmake
0 → 100644
cmake/external/glog.cmake
0 → 100644
cmake/external/gtest.cmake
0 → 100644
cmake/external/openblas.cmake
0 → 100644
cmake/external/protobuf.cmake
0 → 100644
cmake/external/python.cmake
0 → 100644
cmake/external/swig.cmake
0 → 100644
cmake/external/warpctc.cmake
0 → 100644
cmake/external/zlib.cmake
0 → 100644
cmake/swig.cmake
已删除
100644 → 0
cmake/system.cmake
0 → 100644
doc/howto/dev/new_layer_cn.rst
0 → 100644
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
{kind=link}
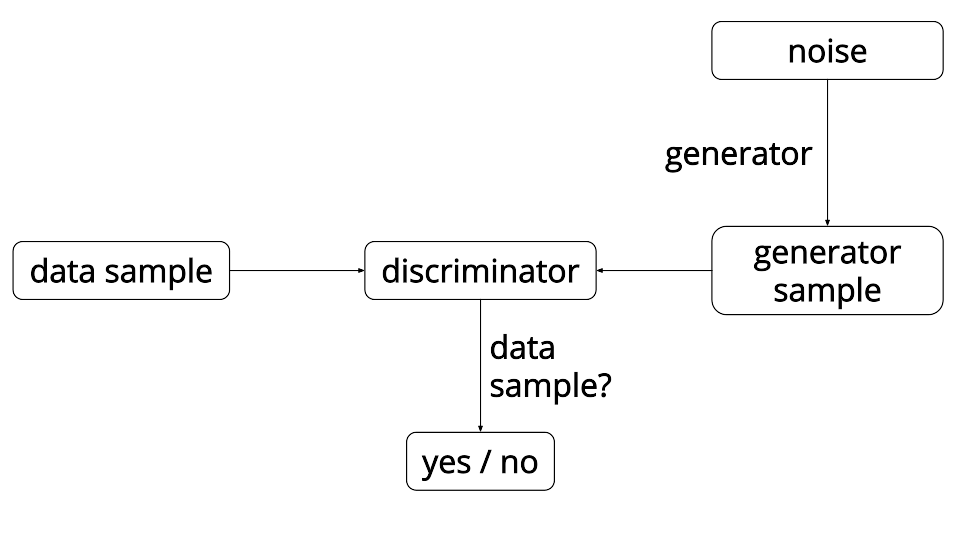
| W: | H:
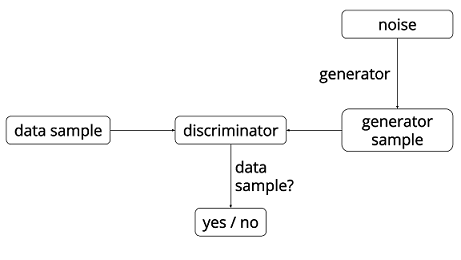
| W: | H:
{kind=link}
{kind=link}
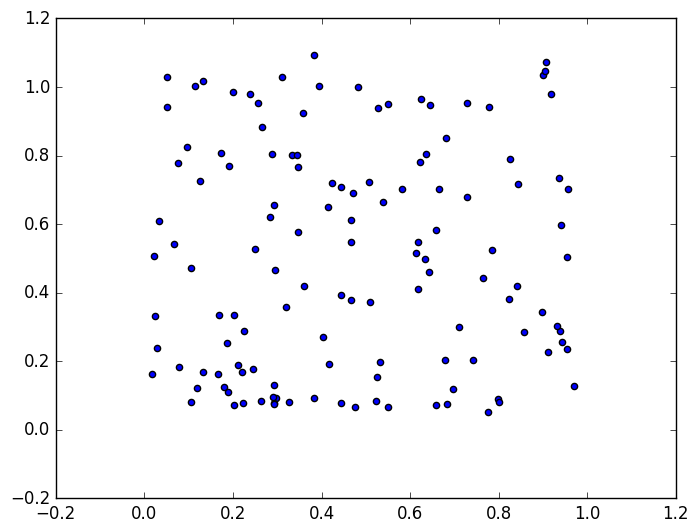
| W: | H:
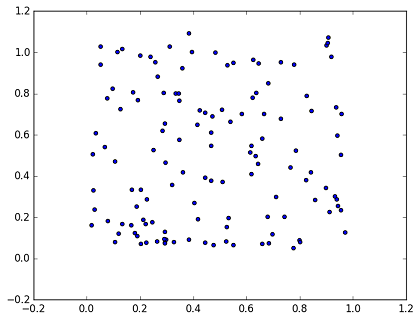
| W: | H:
paddle/scripts/docker/entrypoint
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。