Fork自 PaddlePaddle / Paddle
231.9 KB | W: | H:
116.2 KB | W: | H:
244.5 KB | W: | H:
236.1 KB | W: | H:
87.1 KB
{kind=link}
{kind=link}
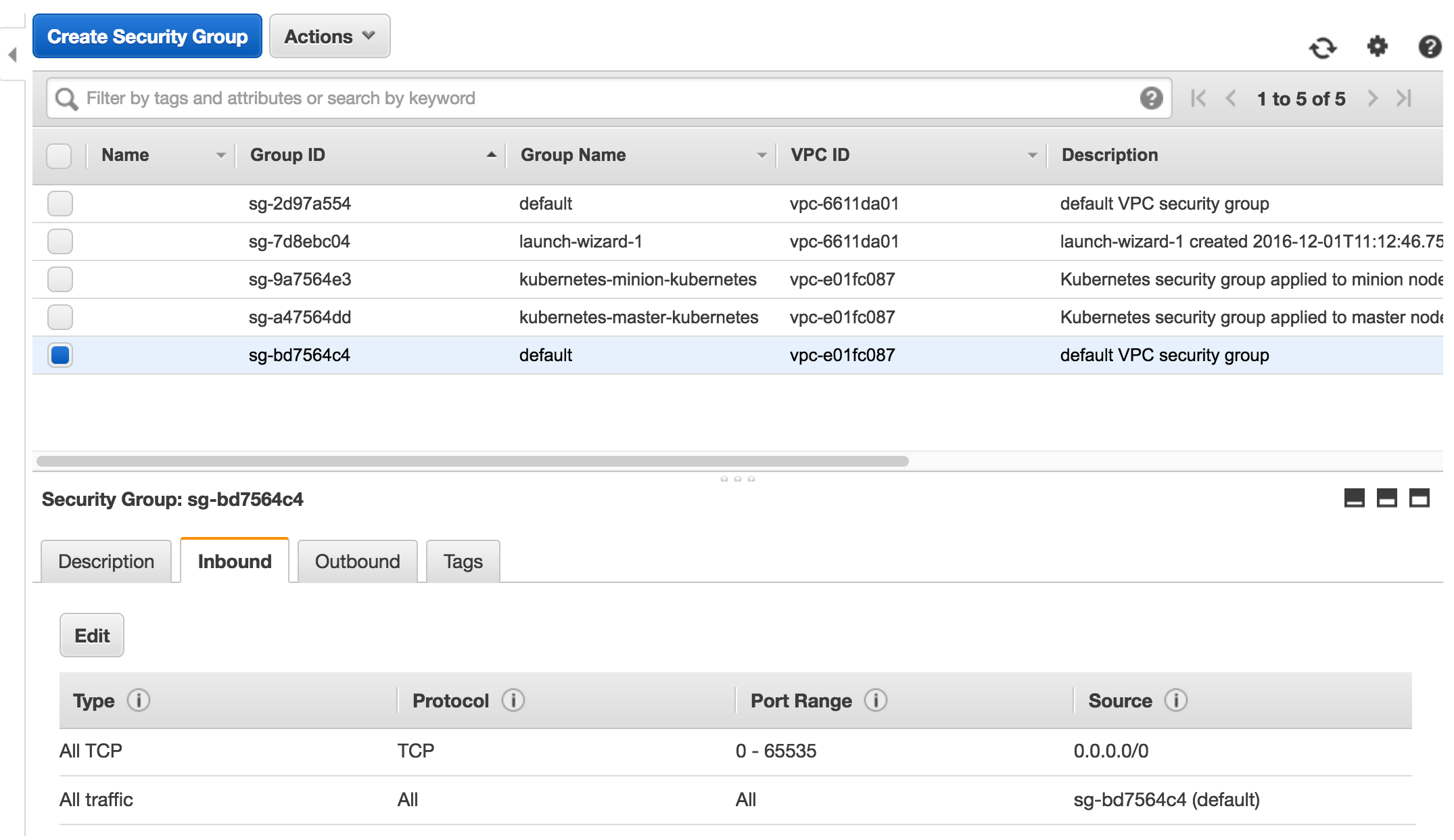
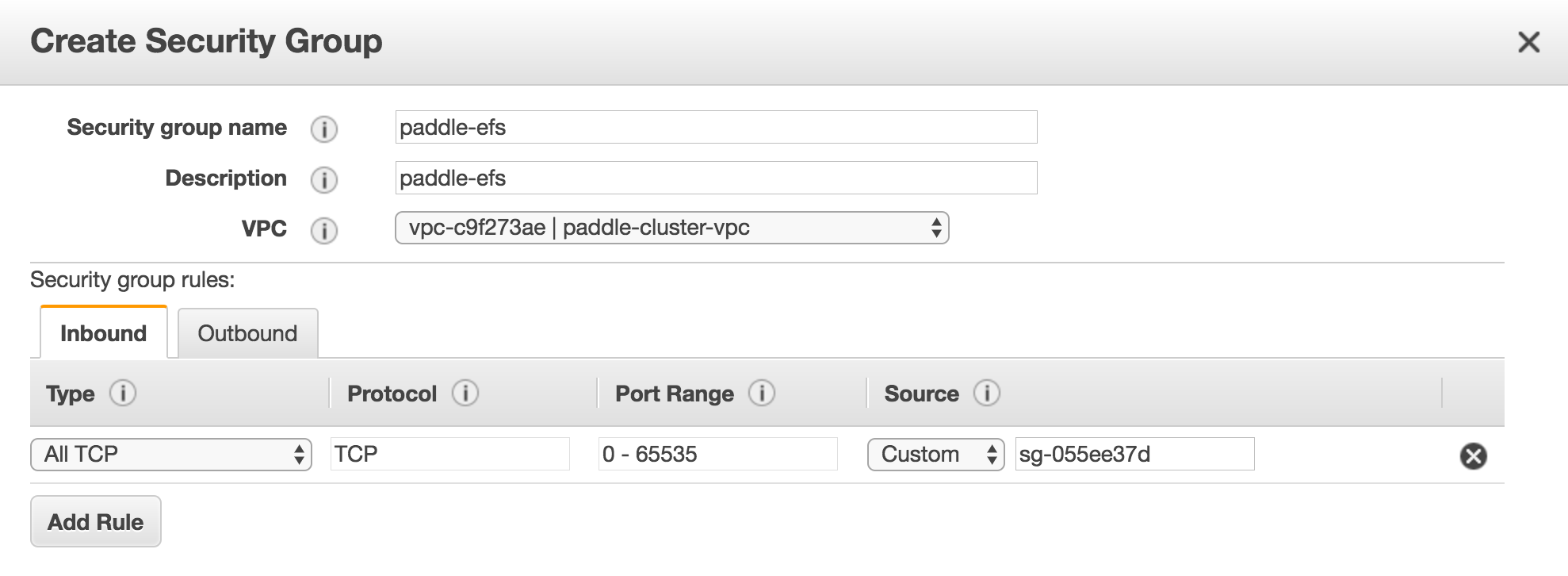
{kind=link}
{kind=link}
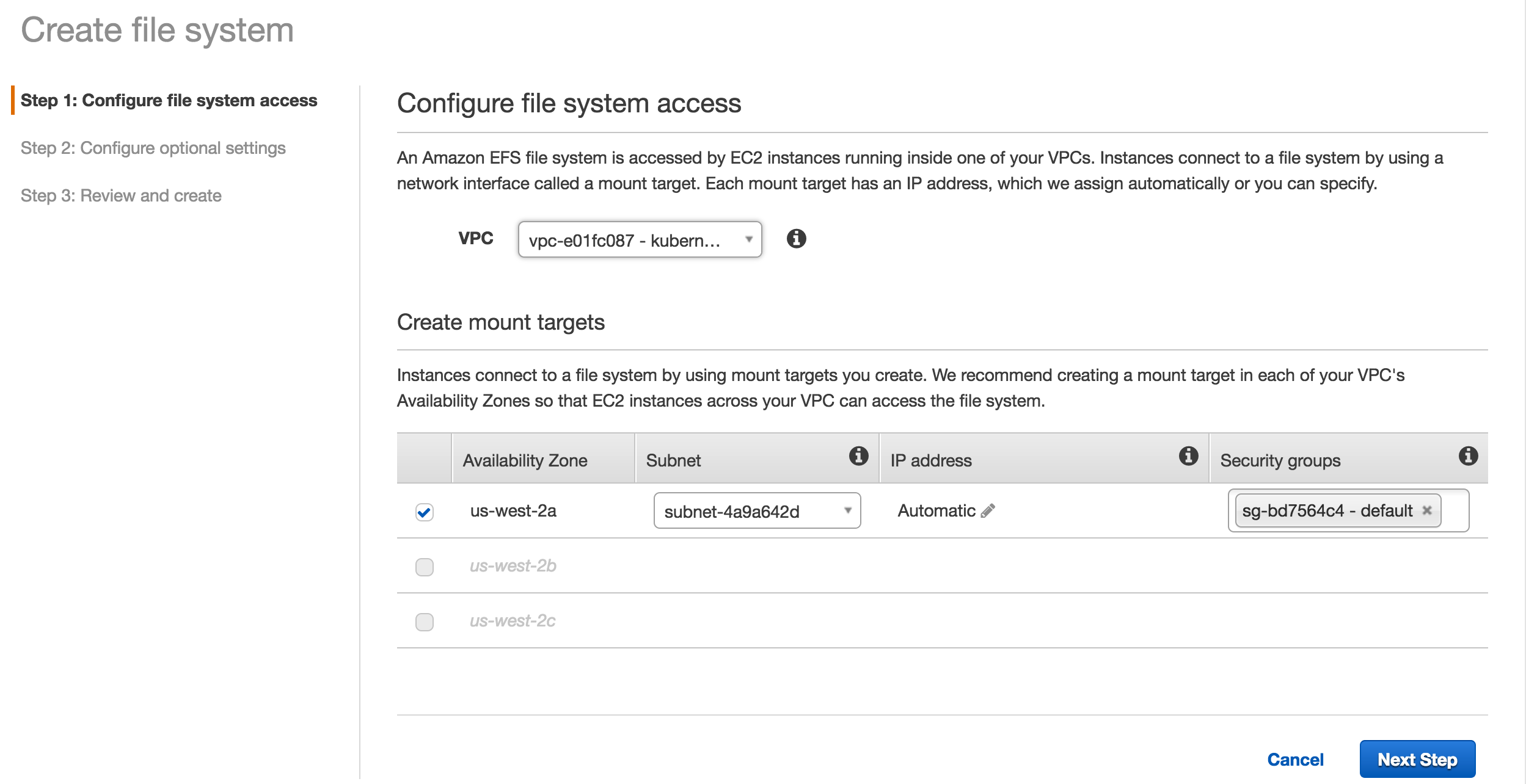
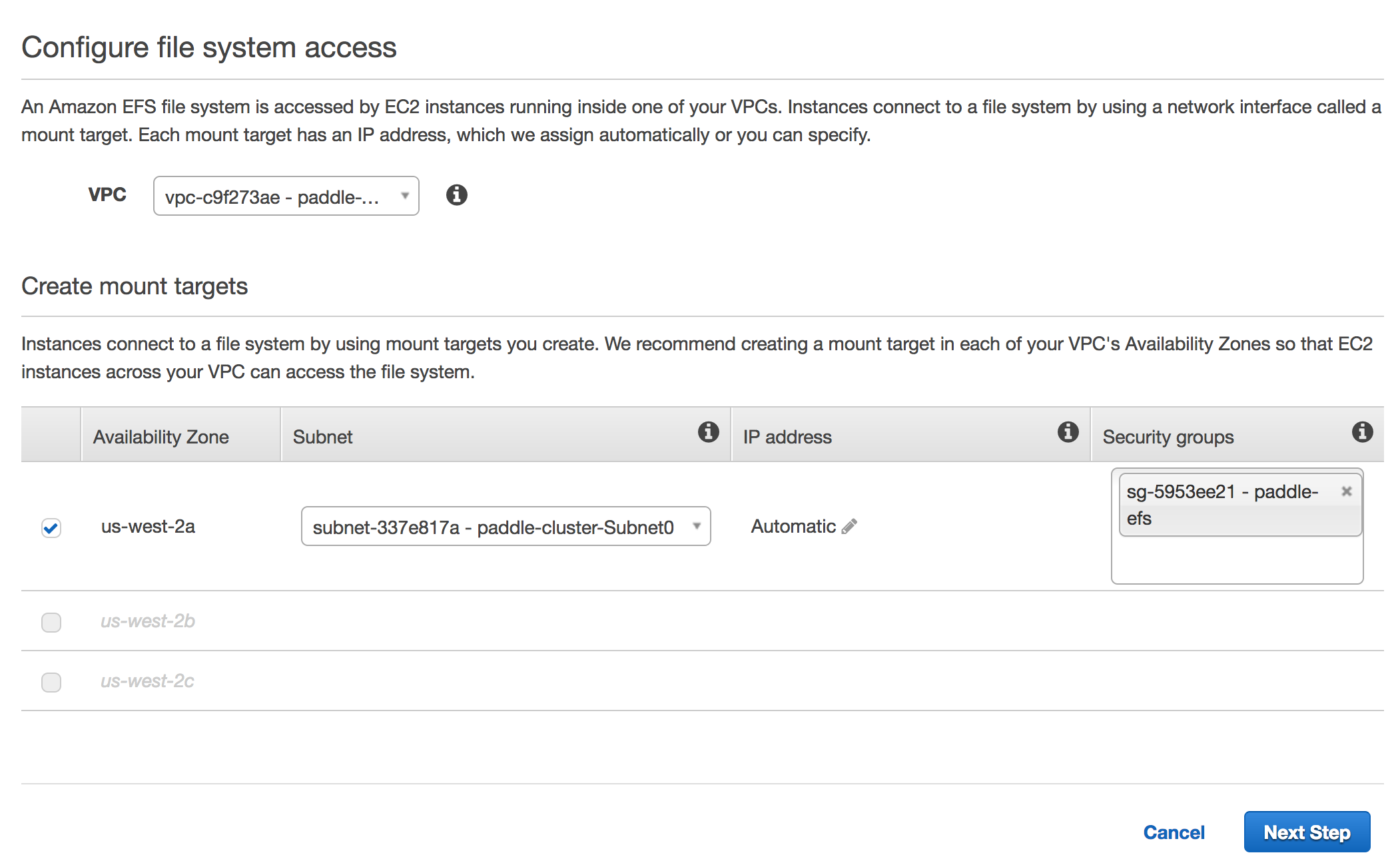
{kind=link}
