@@ -15,7 +15,7 @@ This poses technical challenges to PaddlePaddle:
A training job will be created once user asks Paddle cloud to train a model. The training job is made up of different processes that collaboratively consume data and produce a trained model. There are three kinds of processes:
1. the *master process*, which dispatches tasks to
1. the *master server process*, which dispatches tasks to
1. one or more *trainer processes*, which run distributed training and synchronize gradients/models via
1. one or more *parameter server processes*, where each holds a shard of the global model, and receive the uploaded gradients from every *trainer process*, so they can run the optimize functions to update their parameters.
...
...
@@ -27,9 +27,9 @@ By coordinating these processes, PaddlePaddle supports use both Synchronize Stoc
When training with sync SGD, parameter servers wait for all trainers to finish gradients update and then send the updated parameters to trainers, training can not proceed until the trainer received the updated parameters. This creates a synchronization point between trainers. When training with async SGD, each trainer upload gradient and download new parameters individually, without the synchronization with other trainers. Using asyc SGD will be faster in terms of time per pass, but have more noise in gradient since trainers are likely to have a stale model.
### Master Process
### Master Server Process
The master process will:
The master server process will:
- Partition a dataset into [tasks](#task) and dispatch tasks to trainers.
- Keep track of training progress on the dataset with [task queue](#task-queue). A training job will iterate on the dataset for a full pass until it goes into next pass.
...
...
@@ -41,11 +41,11 @@ A task is a data shard to be trained. The total number of tasks will be much big
#### Task Queue
The master process has three task queues to track training progress. As illustrated in the graph below, Job A and Job B both have one master process. Each master process has three task queues.
The master server has three task queues to track training progress. As illustrated in the graph below, Job A and Job B both have one master server. Each master server process has three task queues.
<imgsrc="src/paddle-task-queues.png"/>
- The todo queue holds tasks to be dispatched. When a job starts, the master process fills in the todo queue with all tasks.
- The todo queue holds tasks to be dispatched. When a job starts, the master server fills in the todo queue with all tasks.
- The pending queue holds tasks that are currently training by trainers.
- the done queue holds tasks that are already trained.
...
...
@@ -54,10 +54,10 @@ The life cycle of a single task is illustrated below:
<imgsrc="src/paddle-task-states.png"/>
1. When a new pass of training starts, all tasks will be placed in the todo queue.
1. The master process will dispatch few tasks to each trainer at a time, puts them in the pending queue and waits for completion.
1. The trainer will work on its tasks and tell the master process once a task is completed. The master process will dispatch a new task to that trainer.
1. If a task timeout. the master process will move it back to the todo queue. The timeout count will increase by one. If the timeout count is above a threshold, the task is likely to cause a trainer to crash, so it will be discarded.
1. The master process will move completed task to the done queue. When the todo queue is empty, the master process will start a new pass by moving all tasks in the done queue to todo queue and reset the timeout counter of all tasks to zero.
1. The master server will dispatch few tasks to each trainer at a time, puts them in the pending queue and waits for completion.
1. The trainer will work on its tasks and tell the master server once a task is completed. The master server will dispatch a new task to that trainer.
1. If a task timeout. the master server will move it back to the todo queue. The timeout count will increase by one. If the timeout count is above a threshold, the task is likely to cause a trainer to crash, so it will be discarded.
1. The master server will move completed task to the done queue. When the todo queue is empty, the master server will start a new pass by moving all tasks in the done queue to todo queue and reset the timeout counter of all tasks to zero.
### Trainer Process
...
...
@@ -93,7 +93,7 @@ The communication pattern between the trainers and the parameter servers depends
## Fault Tolerant
The training job will pause if the master processes is dead, or any of the parameter server process is dead. They will be started by [Kubernetes](https://kubernetes.io/) and recover in few minutes. Please refer to [fault recovery](#fault-recovery).
The training job will pause if the master server processes is dead, or any of the parameter server process is dead. They will be started by [Kubernetes](https://kubernetes.io/) and recover in few minutes. Please refer to [fault recovery](#fault-recovery).
The training job will continue to make progress if there is at least one training process running. The strategy depends on the type of optimization algorithm:
...
...
@@ -113,7 +113,7 @@ Now we will introduce how each process recovers from a failure, the graph below
<imgsrc="src/paddle-etcd.png"/>
### Master Process
### Master Server Process
When the master is started by the Kubernetes, it executes the following steps at startup:
...
...
@@ -122,7 +122,7 @@ When the master is started by the Kubernetes, it executes the following steps at
1. Watches the trainer prefix keys `/trainer/` on etcd to find the live trainers.
1. Starts dispatching the tasks to the trainers, and updates task queue using an etcd transaction to ensure lock is held during the update.
When the master process is dead for any reason, Kubernetes will restart it. It will be online again with all states recovered from etcd in few minutes.
When the master server process is dead for any reason, Kubernetes will restart it. It will be online again with all states recovered from etcd in few minutes.
### Trainer Process
...
...
@@ -132,7 +132,7 @@ When the trainer is started by the Kubernetes, it executes the following steps a
1. Generates a unique ID, and sets key `/trainer/<unique ID>` with its contact address as value. The key will be deleted when the lease expires, so the master will be aware of the trainer being online and offline.
1. Waits for tasks from the master to start training.
If trainer's etcd lease expires, it will try set key `/trainer/<unique ID>` again so that the master process can discover the trainer again.
If trainer's etcd lease expires, it will try set key `/trainer/<unique ID>` again so that the master server can discover the trainer again.
When a trainer fails, Kuberentes would try to restart it. The recovered trainer would fetch tasks from the TODO queue and go on training.
For an overview of master server's role, please refer to [distributed training design doc](./README.md). In this design doc we will discuss the master server in more details. The master will be implemented in [Go](https://golang.org/).
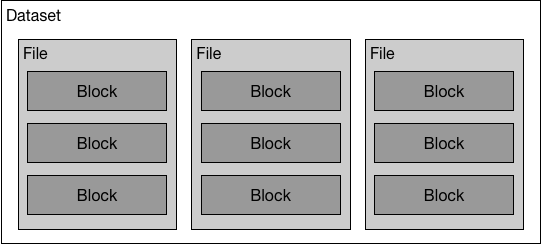
## Dataset
<imgsrc="src/dataset.png"/>
A dataset is a list of files in *RecordIO* format. A RecordIO file consists of chunks, whereas each chunk consists some records.
## Task Queue
As mentioned in [distributed training design doc](./README.md), a *task* is a data shard that the master server assigns to the trainer process to train on. A task consists of one or multiple *blocks* from one or multiple files. The master server maintains *task queues* to track the training progress.
### Task Queue Creation
1. Each trainer will make an RPC call (using Go's [rpc](https://golang.org/pkg/net/rpc/) package) to the master server, telling it the RecordIO files representing the dataset specified by the user. Since every trainer will tell the master server the same dataset, only the first RPC call will be honored.
1. The master server will scan through each RecordIO file to generate the *block index* and know how many blocks does each file have. A block can be referenced by the file path and the index of the block within the file. The block index is in memory data structure that enables fast access to each block, and the index of the block with the file is an integer start from 0, representing the n-th block within the file.
The definition of the block is:
```go
type Block struct {
Idx int // index of the block within the file
Path string
Index recordio.Index // block index
}
```
1. Blocks are grouped into tasks, and tasks are filled into the todo queue. The pending queue and the done queue are initialized with no element.
The definition of the task is:
```go
type Task struct {
Index int
Blocks []Block
}
```
The elements in the tasks queues is of type `TaskEntry`, containing a timeout counter (described in [task retry logic](#task-retry-logic)), and a task:
```go
type TaskEntry struct {
NumTimeout int
Task Task
}
```
The definition of task queues is:
```go
type TaskQueues struct {
Todo []TaskEntry
Pending map[int]TaskEntry // map from task index to task entry
Done []TaskEntry
}
```
### Task Queue Persistence
The task queues need to be persisted on [etcd](https://github.com/coreos/etcd) for fault recovery. Since the task queues only change once a task is completed or timed out, which is not very frequent, we can afford to synchronize with etcd every time the task queues change.
We will serialize the task queues data structure with [gob encoding](https://golang.org/pkg/encoding/gob/), compress with gzip, and save into etcd synchronously under key `/task_queues`.
### Task Dispatch
The trainer will make an RPC call to master to get a new task when:
Argument `finished` will be `nil` when the trainer is just started.
During the RPC call the master will do the following:
- Make a copy of the task queues, and update the copy reflecting the finished tasks and the new pending tasks.
- Synchronize the copy of task queues with etcd using a transaction conditioned on holding the master lock.
- Replace the task queues with the copy and report to the trainer with the new tasks if succeeded, or discard the copy and report the error to the trainer if failed.
### Task Retry Logic
When a task is dispatched to the trainer, the master will schedule a function for execution after the timeout duration (based on the moving average of task completion time). If the task entry in still in the pending queue, its timeout counter will increase by one, and the task will be moved to todo queue. If the timeout counter is above the threshold, the master will log the error and discard the task.
Please note that since a timed out task could be completed after it has been dispatched for retry, so it is possible for a task to be processed multiple times. We do not try to prevent it from happening since it's fine to train on the same task multiple times due to the stochastic nature of the stochastic gradient decent algorithm.
{kind=link}