Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
开源软件推进联盟
《2023 中国开源发展蓝皮书》编制
提交
f935340d
《
《2023 中国开源发展蓝皮书》编制
项目概览
开源软件推进联盟
/
《2023 中国开源发展蓝皮书》编制
通知
146
Star
30
Fork
43
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
2
列表
看板
标记
里程碑
合并请求
2
DevOps
流水线
流水线任务
计划
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
《
《2023 中国开源发展蓝皮书》编制
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
2
Issue
2
列表
看板
标记
里程碑
合并请求
2
合并请求
2
Pages
DevOps
DevOps
流水线
流水线任务
计划
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
流水线任务
提交
Issue看板
提交
f935340d
编写于
5月 22, 2023
作者:
螺旋猫猫头
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
Update 第三章 开源项目发展现状.md
上级
d5ff8b06
变更
1
隐藏空白更改
内联
并排
Showing
1 changed file
with
32 addition
and
12 deletion
+32
-12
第三章 开源项目发展现状.md
第三章 开源项目发展现状.md
+32
-12
未找到文件。
第三章 开源项目发展现状.md
浏览文件 @
f935340d
...
...
@@ -418,51 +418,71 @@ OpenHarmony是开放原子基金会旗下另外一个重要的开源操作系统
近年来,随着深度学习的发展和大规模数据的积累,自然语言模型的规模和性能都有了显著的提升。2022年11月,OpenAI发布正式发布ChatGPT,仅仅2个月后,其成为迄今为止用户数最快破亿的应用,使自然语言处理(NLP)及大型自然语言模型(LLM)成为2023年最受关注的科技话题。自然语言模型的应用已进入快速发展和变革的时期,对高校学习、科研、产业应用、投融资等各社会组织活动将产生重大影响。
人工智能是国家战略的重要组成部分,是未来国际竞争的焦点和经济发展的新引擎。近年来,中国人工智能行业受到各级政府的高度重视和国家产业政策的重点支持 。为了把握新一轮科技革命和产业变革机遇,推动我国人工智能事业高质量发展,中国在“十四五”期间制定了《“十四五”智能制造发展规划》等一系列顶层设计文件,并从多个方面给予了政策扶持和资源投入。
根据《“十四五”智能制造发展规划》,中国将以数字化转型为主线,以关键核心技术突破为支撑,以场景创新为引领,以标准化建设为保障,以协同创新为动力,在2025年前实现我国智能制造水平显著提升。具体而言,在技术层面,《规划》提出加强算法创新与应用、推动算力基础设施建设、完善数据基础支撑体系等关键任务;在应用层面,《规划》提出培育一批具有全球竞争力的领军企业、打造一批示范性应用场景、构建一批开放共享平台等目标;在生态层面,《规划》提出优化政策环境、完善法律法规、加强伦理道德约束等措施。通过以上举措,《规划》旨在促进我国从传统制造大国向数字化制造强国转变,在全球产业链中占据更高端位置,在新一轮产业变革中赢得主动权。
**1.政策方面:**
1)加强基础研究和应用研究:《国务院办公厅关于全面加强新时代语言文字工作的意见》提出进一步推进计算机视觉、智能语音处理、生物特征识别、自然语言理解、智能决策控制以及新型人机交互等关键技术的研发和产业化,支持语言文字基础研究和应用研究,鼓励学科交叉,完善相关学科体系建设。同时,要加强语言文字数据资源的收集、整理、标注和共享,构建开放式的语言文字大数据平台,促进语言文字信息化水平的提升。建立健全自然语言处理和自然语言大模型的研发、评测、标准化、共享等体系,培育一批具有国际竞争力的核心技术和产品,提升我国在多语种文本分析、机器翻译、知识图谱、对话系统等领域的水平和影响;
2)支持产业创新和转化:《促进新一代人工智能产业发展三年行动计划(2018-2020年)》提出大力推动语言文字与人工智能、大数据、云计算等信息技术的深度融合,加强人工智能环境下自然语言处理等关键问题研究和原创技术研发,加强语言技术成果转化及推广应用,支持创业创新。同时,要加快推进自然语言处理和自然语言大模型的应用落地,打造一批具有示范效应的解决方案,促进产学研用协同创新。此外,要搭建开放包容的创新生态平台,鼓励各类主体参与自然语言处理和自然语言大模型的研究开发和商业化运营,为广大科技工作者和企业家提供政策支持和服务保障;
3)促进多领域多场景应用:以《2021年我国智能语音产业相关政策规划汇总》为例,梳理了我国部分地区出台的多项政策规划,鼓励开发自然语言处理和自然语言大模型在教育、文化、媒体、司法、医疗等行业领域的应用,提升应用场景中对于自然语言处理和生成的效率与效果,进而推动生产效率提升,并基于在具体场景中的使用,形成“使用——开发——研究”的反馈链路,加速基础研究与应用开发;通过使用自然语言大模型,可以提高各个领域和场景下的自然语言理解和生成效率和质量,实现更加便捷、准确和高效的信息交流和知识获取,并在以上领域建设国家新一代人工智能开放创新平台。
**2.科研方面:**
1)以鹏城实验室、智源研究院为代表的一系列科研机构的建立,进行重点攻关大规模自然语言处理领域的核心技术,逐步形成了以悟道、鹏程·盘古为代表的自然语言模型,并向产学研各界开放使用;以自由探索和目标导向相结合的体制机制,开展相关研究发表或支持发表国际AI顶会顶刊论文;与北京大学、清华大学、中国科学院等高校和科研机构建立紧密合作关系,共同培养人才和推进科技成果转化,有效促进了我国科研领域组织与人才在自然语言处理和语言模型方面不断努力和创新;
2)国内的顶级高校,如清华大学、北京大学、复旦大学等知名高校已经成立了专门的自然语言实验室或研究组织,致力于自然语言处理和语言模型方面的研究和应用。如近期上线并开源的MOSS和ChatGLM-6B分别来自于复旦大学的邱锡鹏教授团队和清华大学孵化的智谱AI团队。高校在推动科研发展的三方面优势:一是拥有优秀的师资队伍,他们在国内外发表了大量高水平的论文,也培养了一批优秀的研究生和博士生;二是拥有强大的计算资源,他们能够利用高性能计算机和云平台进行大规模数据处理和模型训练;三是拥有广泛的合作伙伴,他们与政府、企业、社会等各界保持良好的沟通和交流,为自然语言处理技术在各个领域的落地和创新提供了支持;
3)在全球知名顶会期刊中,我国开发者体量、国内论文投递量及收录量也在逐年提高,根据斯坦福大学的AI Index统计,自2017年开始统计以来,中国AI相关的研发活力始终处于世界第二的位置;以ACL 2021为例,共有 1239 篇论文投稿来自中国大陆,其中 251 篇被接收,接收率为20.3%。
**3.中文大模型案例**
中国作为世界上最大的中文使用国家,也在积极探索大型语言模型的研究和应用。截至2023年,中国已经涌现出多个具有国际水平的大型中文预训练语言模型,如腾讯的混元、阿里巴巴的M6、百度的文心、鹏程·盘古、华为的盘古、智源的悟道和IDEA的封神榜等。这些模型都基于不同的架构和数据集进行了预训练,并且在不同领域展示了其强大的生成和理解能力。下面对这些模型进行简要介绍:
中国作为世界上最大的中文使用国家,也在积极探索大型语言模型的研究和应用。截至2023年5月,国内已有超过30个大模型项目发布,其中,包含通用大型预训练语言模型,如腾讯的混元、阿里巴巴的通义千问、百度的文心、鹏程·盘古、华为的盘古、智源的悟道和IDEA的封神榜-姜子牙,也包括源自垂直领域如教育行业的网易有道的子曰,学而思的MathGPT等项目。
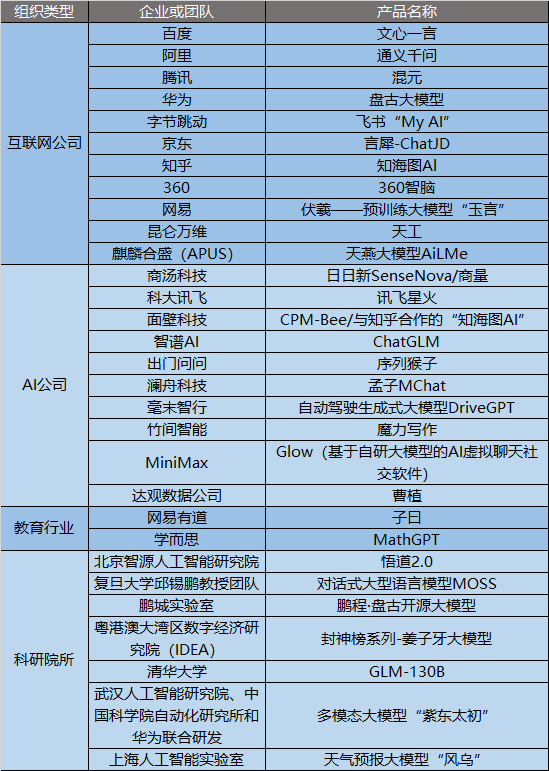
以上模型基于不同的架构和数据集进行了预训练,并且在不同领域展示了其强大的生成和理解能力。下面对部分模型进行简要介绍:
1)文心:文心大模型是百度为主体发布的产业级知识增强大模型,能够理解和生成自然语言,同时结合知识图谱,提升了学习效率和可解释性。文心大模型包括多个子模型,如ERNIE、PLATO、鹏城-百度·文心等,分别在语言理解、文本生成、跨模态语义理解、对话互动等领域取得多项技术突破。其中鹏城-百度·文心是全球首个知识增强千亿大模型,参数规模达到2600亿,在60多项典型任务中取得了世界领先效果,在各类AI应用场景中均具备极强的泛化能力。
2)悟道:悟道是北京智源人工智能研究院开发的一系列超大规模预训练语言模型,包括悟道1.0和悟道2.0。悟道2.0于2021年6月发布,参数量达到1.75万亿,并在世界公认的9项 Benchmark 上达到了世界第一,在多项基准测试中超越OpenAI GPT-3、DALL·E以及Google ALIGN等先进模型;除此之外,智源通过FlagAI开源平台,将悟道GLM正式开源。
3)鹏程·盘古:鹏程·盘古α大模型是鹏城实验室与华为联合研发的全球首个完全开源开放、以中文为核心的两千亿参数的预训练生成语言模型,鹏程·盘古系列大模型包括鹏程·盘古α、鹏程·盘古增强版、鹏程·盘古多语言大模型和鹏程·盘古对话生成大模型。其中鹏程·盘古增强版创新应用了多任务学习、任务统一格式、提示微调和持续学习等技术,对鹏程·盘古α基本版模型进行了能力扩展和增强。鹏程·盘古多语言大模型,首个以中文为中心的多语言&机器翻译模型,并在2022 IKCEST “一带一路”国际大数据竞赛中获得第二名。鹏程·盘古对话生成大模型是基于盘古α的开放域对话系统,可以与用户进行自然、流畅和有趣的对话。
4)华为盘古:华为盘古β大模型是循环智能与华为云联合推出千亿参数中文语言预训练模型,鹏城实验室提供算力支持。华为盘古β是2020年4月25日发布的Transformer encoder-decoder的中文理解模型,在权威的中文语言理解测评基准CLUE榜单中,总成绩及阅读理解、分类任务单项均排名第一。
5)混元:2022年底,混元1T大模型利用腾讯太极机器学习平台的高效算力和低成本网络,用千亿模型热启动的情况下,可以在256张显卡上一天内完成训练。该模型在国内最权威的自然语言理解任务榜单CLUE上取得了优异的成绩,并且已经成功应用于腾讯广告、搜索、对话等多个核心业务场景。
6)M6: M6模型是一种基于多模态(语言、图像、视频等)的人工智能预训练模型,具有10万亿级别的参数量,是中文社区最大的跨模态预训练模型。该模型通过一系列技术创新,大幅降低了训练能耗和时间,并且拥有强大的认知和创造能力。该模型在电商、制造业、文学艺术、科学研究等领域有广泛应用前景,并且已经实现了商业化落地。
7)封神榜:2021年11月,IDEA研究院正式发布了“封神榜”开源体系——一个以中文驱动的基础生态系统,其中包括了预训练大模型,特定任务的微调应用,基准和数据集等。我们的目标是构建一个全面的,标准化的,以用户为中心的生态系统。截至目前,封神榜体系中包含:二郎神、闻仲、燃灯、太乙、余元、周文王等模型。
3)盘古:华为盘古β大模型是循环智能与华为云联合推出千亿参数中文语言预训练模型,鹏城实验室提供算力支持。华为盘古β是2020年4月25日发布的Transformer encoder-decoder的中文理解模型,在权威的中文语言理解测评基准CLUE榜单中,总成绩及阅读理解、分类任务单项均排名第一。
鹏程·盘古α大模型是鹏城实验室与华为联合研发的全球首个完全开源开放、以中文为核心的两千亿参数的预训练生成语言模型,鹏程·盘古系列大模型包括鹏程·盘古α、鹏程·盘古增强版、鹏程·盘古多语言大模型和鹏程·盘古对话生成大模型。其中鹏程·盘古增强版创新应用了多任务学习、任务统一格式、提示微调和持续学习等技术,对鹏程·盘古α基本版模型进行了能力扩展和增强。鹏程·盘古多语言大模型,首个以中文为中心的多语言&机器翻译模型,并在2022 IKCEST “一带一路”国际大数据竞赛中获得第二名。鹏程·盘古对话生成大模型是基于盘古α的开放域对话系统,可以与用户进行自然、流畅和有趣的对话。
4)混元:2022年底,混元1T大模型利用腾讯太极机器学习平台的高效算力和低成本网络,用千亿模型热启动的情况下,可以在256张显卡上一天内完成训练。该模型在国内最权威的自然语言理解任务榜单CLUE上取得了优异的成绩,并且已经成功应用于腾讯广告、搜索、对话等多个核心业务场景。
5)通义千问:2023年4月,阿里正式发布“通义千问”,该模型基于10万亿级参数的大模型底座M6模型。M6是一种基于多模态(语言、图像、视频等)的人工智能预训练模型,通过一系列技术创新,大幅降低了训练能耗和时间,并且拥有强大的认知和创造能力。该模型在电商、制造业、文学艺术、科学研究等领域有广泛应用前景,并且已经实现了商业化落地。
6)封神榜-姜子牙:2021年11月,IDEA研究院正式发布了“封神榜”开源体系——一个以中文驱动的基础生态系统,其中包括了预训练大模型,特定任务的微调应用,基准和数据集等。2023年5月17日,IDEA研究院发布“姜子牙通用大模型V1”,姜子牙通用大模型v1(Ziya-LLaMA-13B-v1)拥有130亿参数,从LLaMA-13B开始重新构建中文词表,进行千亿token量级的已知的最大规模继续预训练,使模型具备原生中文能力。再经过500万条多任务样本的有监督微调(SFT)和综合人类反馈训练,进一步激发和加强各种AI任务能力。
7)知海图AI:2023年4月,面壁科技与知乎合作的知海图AI正式发布,该项目在开源的双语预训练语言模型CPM-Bee基础上进行研发。值得一提的是,作为参数量10B的CPM-Bee模型,不仅有十余种原生能力,更是具有强大的通用语言能力。CPM-Bee模型于2023年1月15日在 ZeroCLUE 榜单上登顶榜首。
8)GLM-130B及ChatGLM:GLM-130B是清华大学发布的预训练语言模型,具有1300亿个参数。根据其官网介绍,该模型不仅支持中文和英文双语,两种语言的精度均于发布时对比其他模型具有明显优势,除此之外,GLM-130B具备快速且基本无损推理的能力,并兼容包括昇腾NPU、英伟达GPU、海光DCU等多种架构的智能计算芯片。2023年3月,对话模型ChatGLM-6B及千亿对话模型ChatGLM由智谱AI(由清华大学计算机系技术成果转化而来)正式发布。
9)MOSS:2023年2月,MOSS由复旦大学邱锡鹏教授团队正式发布并于4月正式上线并开源。目前,相关代码、数据、模型参数已在Github、Hugging Face等平台开放。开源代码涵盖模型训练和推理代码,开源数据包括超100万条对话训练数据,开源模型包括160亿参数中英双语基座语言模型、对话模型及插件增强的对话模型。
### 发展建议
**提升算力水平**
**
1.
提升算力水平**
算力是支撑大规模预训练语言模型训练和部署的关键因素,需要开发和使用高效率、高性能、低成本的计算平台和硬件设备,并优化并行化和分布式计算策略。随着对模型性能要求的不断提升,对于训练模型所需的算力规模势必会不断增加,因此,集中力量建设“中国算力网”,像使用电力一样使用算力,将成为未来我国人工智能基础建设中的重要一环。
算力是支撑大规模预训练语言模型训练和部署的关键因素,需要开发和使用高效率、高性能、低成本的计算平台和硬件设备,并优化并行化和分布式计算策略。随着对模型性能要求的不断提升,对于训练模型所需的算力规模势必会不断增加,因此,集中力量建设“中国算力网”,像使用电力一样使用算力,将成为未来我国人工智能基础建设中的重要一环。通过中国算力网,实现AI算力资源的共享、调度和协同:一方面赋能用户根据需求灵活获取和使用各种类型和规模的AI算力服务,降低人工智能应用开发和部署的门槛和成本;另一方面也使得大规模算力跨区域协同计算成为可能,进而促进各地区、各行业、各领域之间的AI创新合作与交流,为我国人工智能产业发展提供强有力的支撑。
**加强数据资源建设**
**
2.
加强数据资源建设**
数据是训练大规模预训练语言模型不可或缺的基础,需要收集和整理高质量、高覆盖度、高多样性的数据集,对数据进行更加精细、更加高效的工程化处理,也将成为未来人工智能快速发展的重要基石;与此同时,数据安全和隐私保护的投入也将对大规模数据带来重要的支持作用。以GPT-4为例,其在数据工程化,特别是在动态数据更新、小样本数据微调、多模态数据融合等方面工作的尝试都产生了非常值得关注的效果。因此,如何建立我国的数据标准以及数据工程化实现方案对于提升我国在自然语言处理及语言大模型成果产生方面,将产生重大意义。
**探索新颖有效的模型架构**
**
3.
探索新颖有效的模型架构**
ChatGPT和GPT-4的成功证明,模型架构是决定大规模预训练语言模型性能和泛化能力的核心要素。因此,未来对于大模型的研发,也需要进行创新技术研究,考虑不同任务场景下特定领域知识和逻辑推理等因素。诸如多头注意力机制的改进、深度残差网络的优化、人类反馈强化学习(RLHF)的应用以及在多模态数据处理及应用方面的探索和尝试,均对新一代大模型的产生,提供了巨大的支持。随着数据量、计算资源、任务复杂度等因素不断增加,在保证可扩展性、可解释性、可控制性等方面也面临着新的挑战。因此,探索新颖而有效地语言模型架构不仅可以推动人工智能技术水平和应用价值的提升,也可以促进基础理论与前沿实践之间更紧密地结合。
**增强开放协作**
截至2023年3月,OpenAI仍未对GPT-3.5及GPT-4进行开源计划的发布,限制了其他研究者基于此的改进和创新,阻碍了模型的可解释性,也增加了模型被滥用和误用的风险。基于此,我国可以充分发挥制度优势,在中立机构的组织和协调下,团结各研究和开发力量,整合算力、数据资源,以开源开放方式进行大模型的研究与开发工作。通过开源协作,不仅能够提高我国在自然语言处理领域的技术水平和竞争力,也能够为全球社会贡献一种更公平、更透明、更可信赖的人工智能服务。同时,通过建立统一的标准和规范,我们也可以有效地保护用户隐私、维护网络安全、防止信息偏见和歧视等问题。
**4.增强开放协作**
截至2023年5月,OpenAI仍未对GPT-3.5及GPT-4进行开源计划的发布,限制了其他研究者基于此的改进和创新,阻碍了模型的可解释性,也增加了模型被滥用和误用的风险。基于此,我国可以充分发挥制度优势,在中立机构的组织和协调下,团结各研究和开发力量,整合算力、数据资源,以开源开放方式进行大模型的研究与开发工作。通过开源协作,不仅能够提高我国在自然语言处理领域的技术水平和竞争力,也能够为全球社会贡献一种更公平、更透明、更可信赖的人工智能服务。同时,通过建立统一的标准和规范,我们也可以有效地保护用户隐私、维护网络安全、防止信息偏见和歧视等问题。
## 开源区块链项目现状介绍
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
