Merge pull request #2 from seiriosPlus/master
PaddleRec Milestone
Showing
.gitignore
0 → 100644
__init__.py
0 → 100755
core/__init__.py
0 → 100755
core/engine/__init__.py
0 → 100755
core/engine/cluster/__init__.py
0 → 100644
core/engine/cluster/cluster.py
0 → 100644
core/engine/engine.py
0 → 100755
core/engine/local_cluster.py
0 → 100755
core/engine/local_mpi.py
0 → 100755
core/factory.py
0 → 100755
core/layer.py
0 → 100755
core/metric.py
0 → 100755
core/metrics/__init__.py
0 → 100755
core/metrics/auc_metrics.py
0 → 100755
core/model.py
0 → 100755
core/modules/__init__.py
0 → 100755
core/modules/coding/__init__.py
0 → 100755
core/modules/coding/layers.py
0 → 100755
core/modules/modul/__init__.py
0 → 100755
core/modules/modul/build.py
0 → 100755
core/modules/modul/layers.py
0 → 100755
core/reader.py
0 → 100755
core/trainer.py
0 → 100755
core/trainers/__init__.py
0 → 100755
core/trainers/cluster_trainer.py
0 → 100755
此差异已折叠。
core/trainers/single_trainer.py
0 → 100755
core/utils/__init__.py
0 → 100755
core/utils/dataloader_instance.py
0 → 100755
core/utils/dataset_holder.py
0 → 100755
core/utils/dataset_instance.py
0 → 100755
core/utils/envs.py
0 → 100755
core/utils/fs.py
0 → 100755
core/utils/table.py
0 → 100755
core/utils/util.py
0 → 100755
doc/.DS_Store
0 → 100644
文件已添加
doc/__init__.py
0 → 100755
doc/benchmark.md
0 → 100644
doc/contribute.md
0 → 100644
doc/custom_dataset_reader.md
0 → 100644
此差异已折叠。
doc/design.md
0 → 100644
doc/distributed_train.md
0 → 100644
doc/faq.md
0 → 100644
doc/imgs/cnn-ckim2014.png
0 → 100644
{kind=link}
136.7 KB
doc/imgs/coding-gif.png
0 → 100755
{kind=link}

263.6 KB
doc/imgs/dcn.png
0 → 100644
{kind=link}
174.6 KB
doc/imgs/deepfm.png
0 → 100644
{kind=link}
242.7 KB
doc/imgs/design.png
0 → 100644
{kind=link}
456.1 KB
doc/imgs/din.png
0 → 100644
{kind=link}
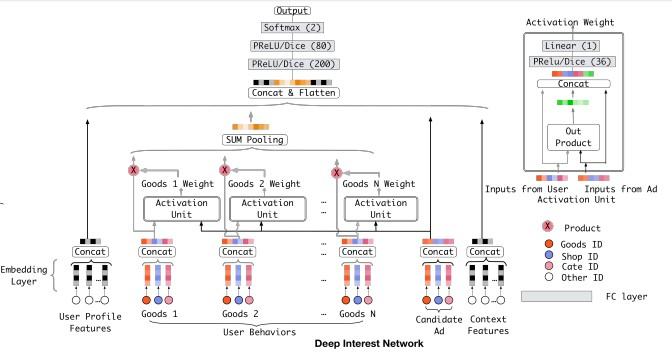
130.0 KB
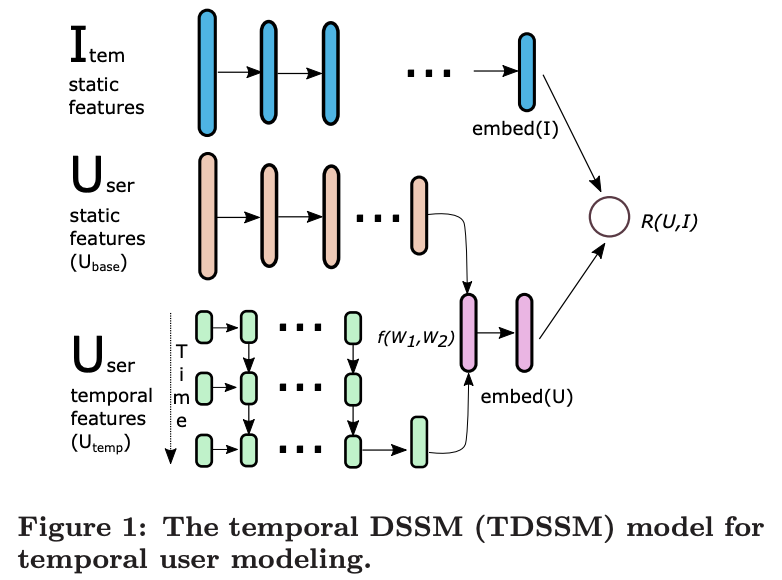
doc/imgs/dssm.png
0 → 100644
{kind=link}
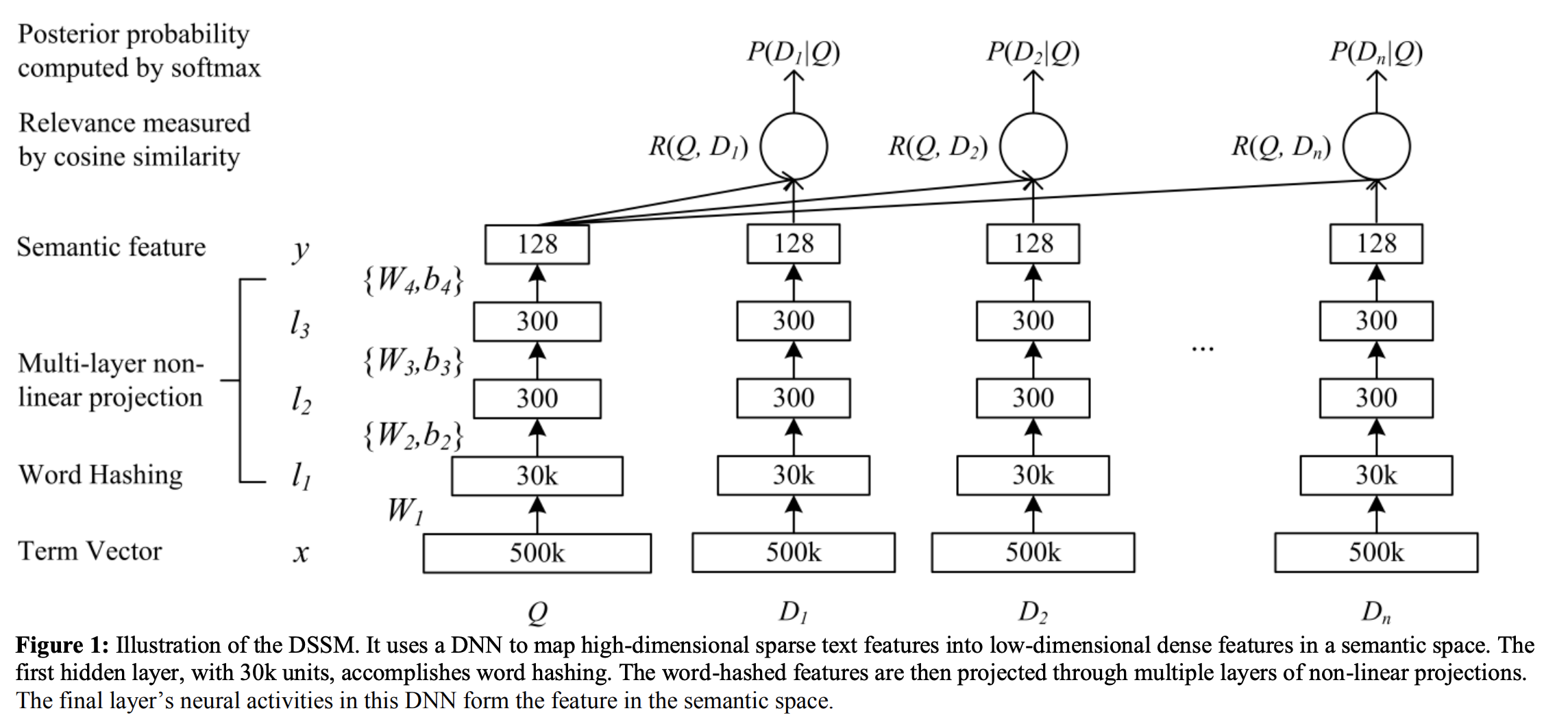
373.8 KB
doc/imgs/esmm.png
0 → 100644
{kind=link}
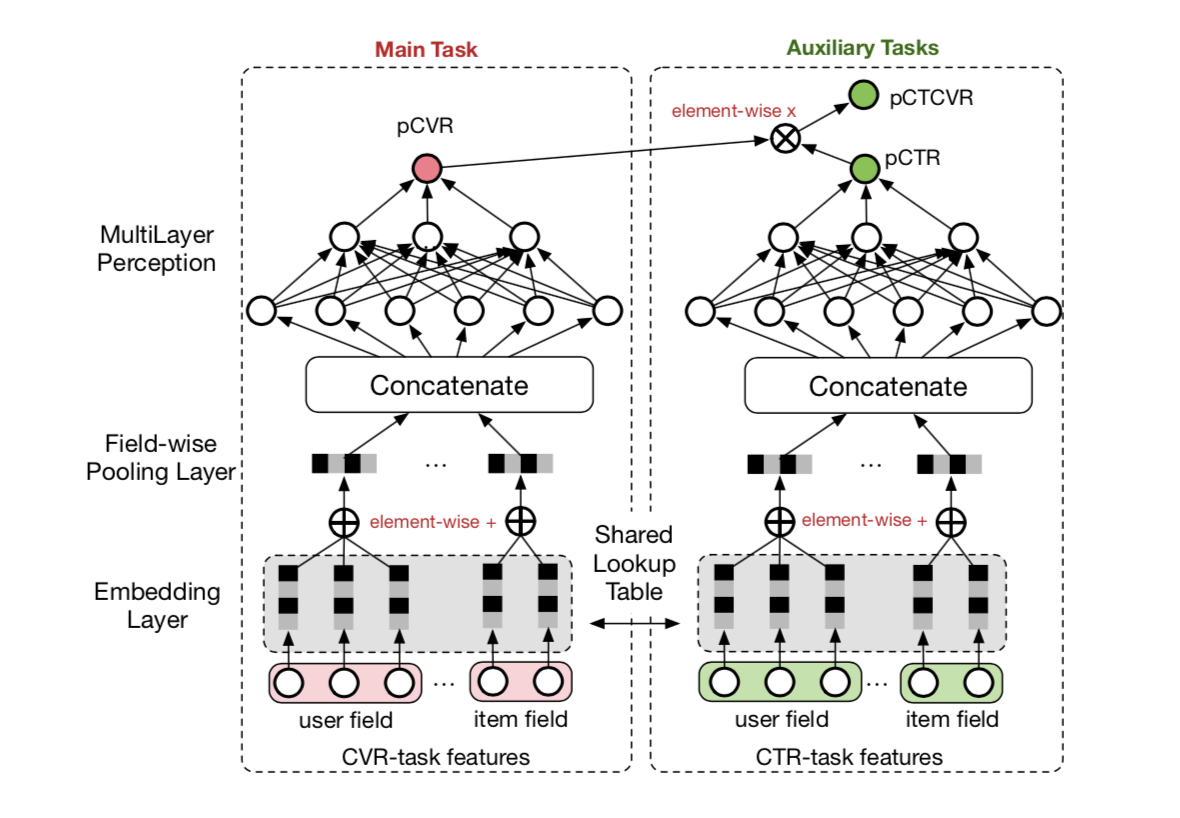
235.4 KB
doc/imgs/fleet-ps.png
0 → 100644
{kind=link}
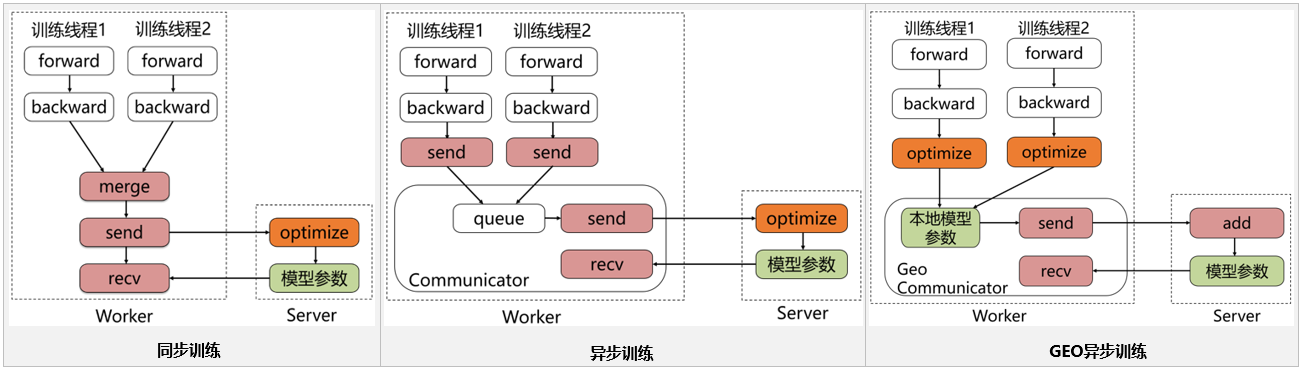
173.5 KB
doc/imgs/gnn.png
0 → 100644
{kind=link}
247.5 KB
doc/imgs/gru4rec.png
0 → 100644
{kind=link}
124.1 KB
doc/imgs/logo.png
0 → 100644
{kind=link}
442.4 KB
doc/imgs/mmoe.png
0 → 100644
{kind=link}
101.1 KB
doc/imgs/multiview-simnet.png
0 → 100644
{kind=link}
303.1 KB
doc/imgs/ncf.png
0 → 100644
{kind=link}
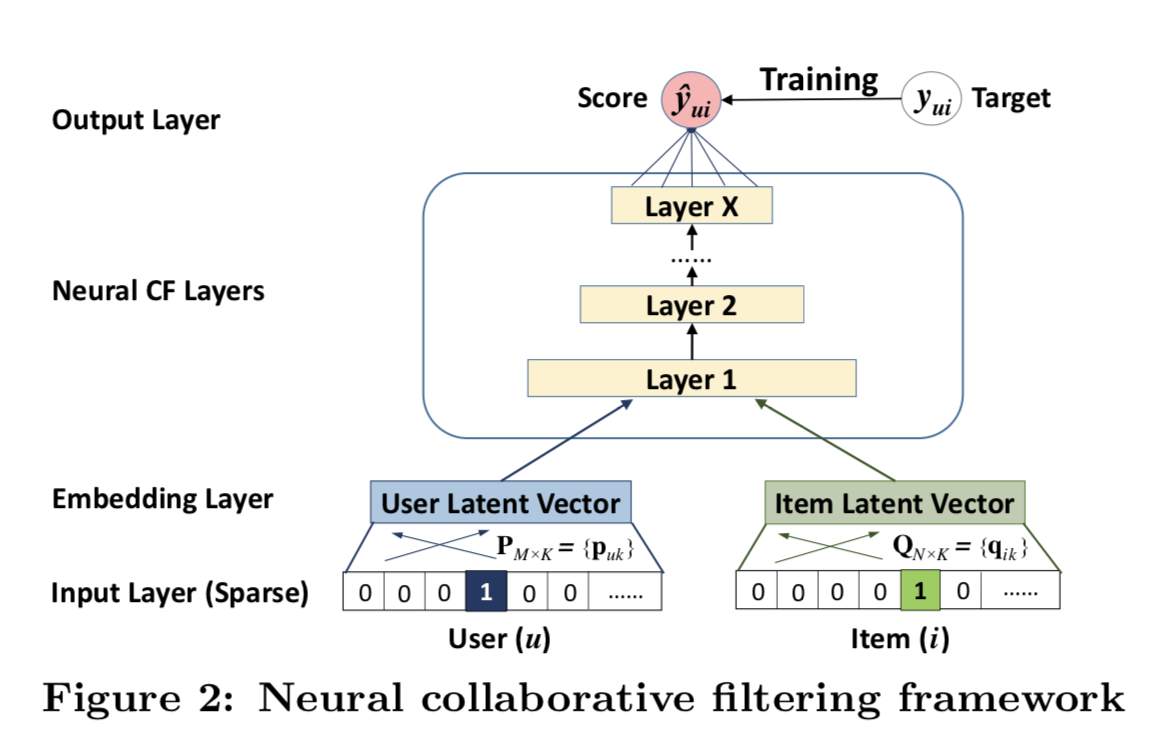
148.0 KB
doc/imgs/overview.png
0 → 100644
{kind=link}
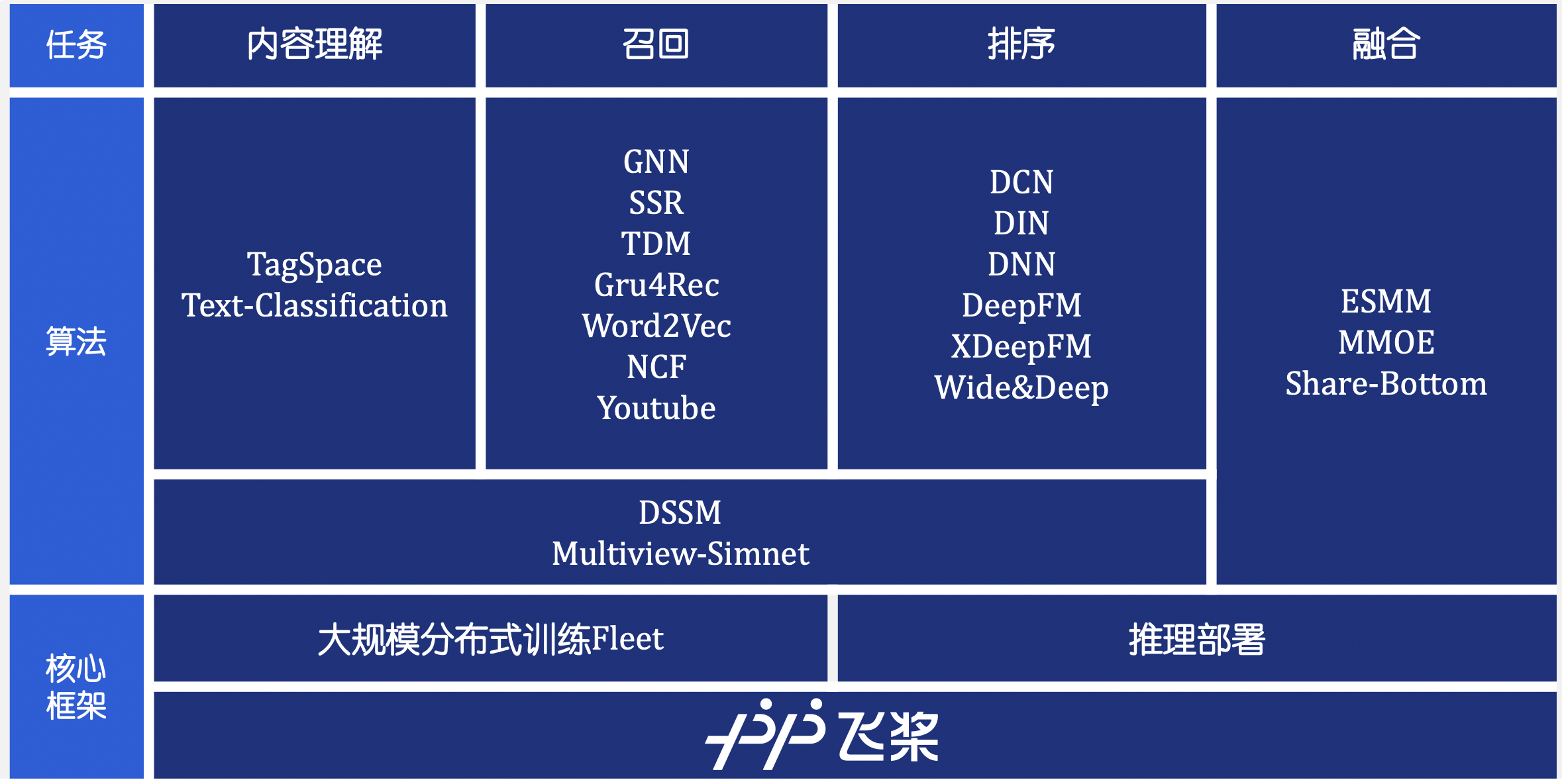
698.6 KB
doc/imgs/ps-overview.png
0 → 100644
{kind=link}
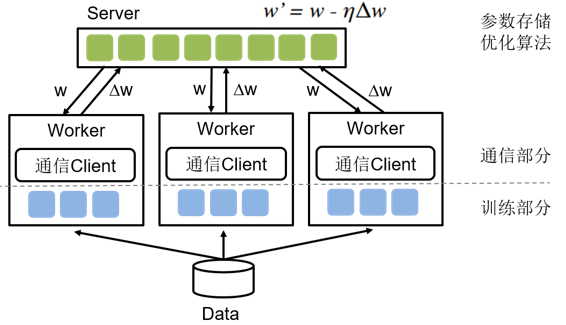
54.9 KB
doc/imgs/rec-overview.png
0 → 100644
{kind=link}
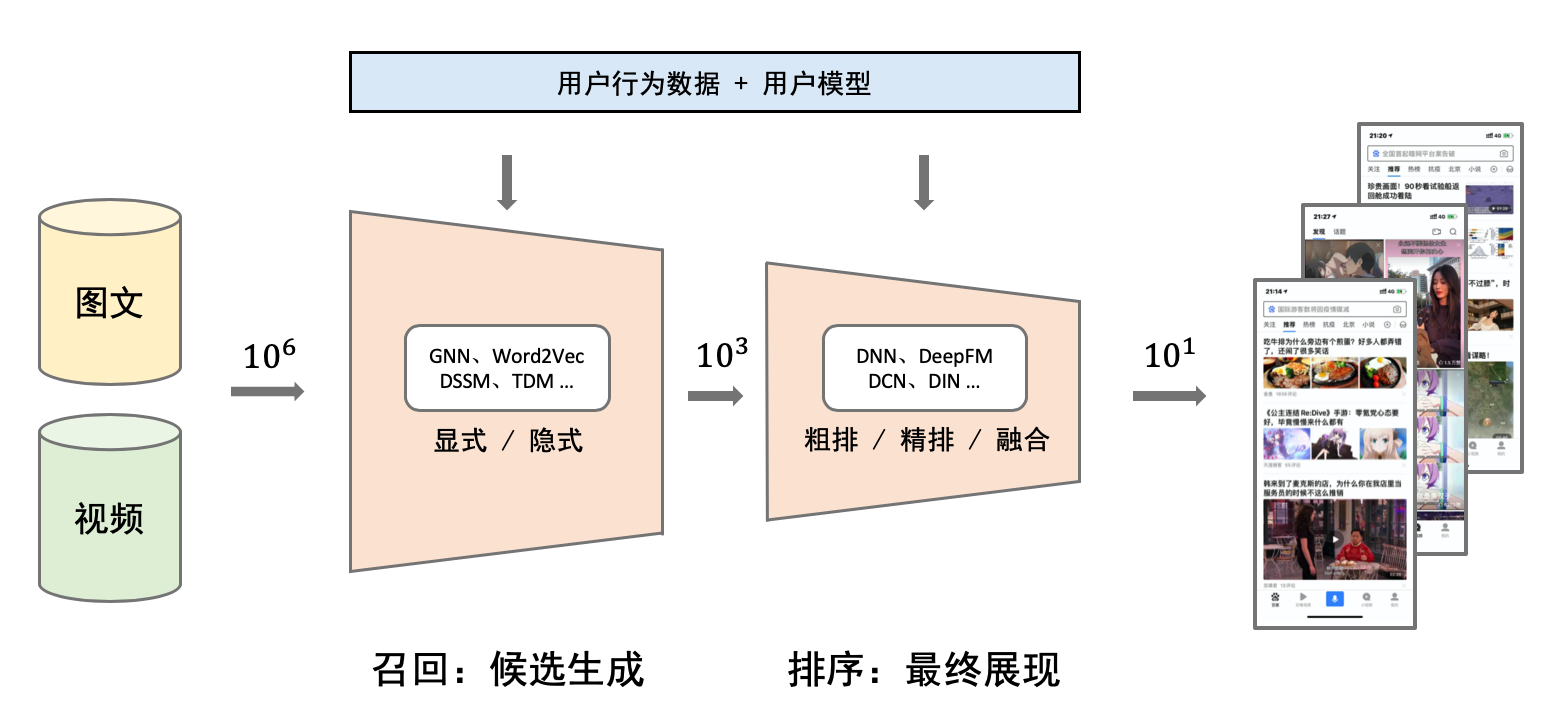
267.3 KB
doc/imgs/share-bottom.png
0 → 100644
{kind=link}
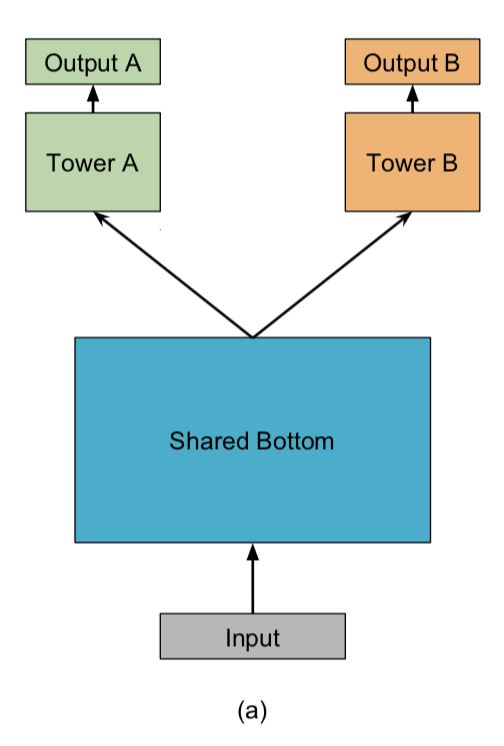
47.2 KB
doc/imgs/ssr.png
0 → 100644
{kind=link}
77.4 KB
doc/imgs/structure.png
0 → 100644
{kind=link}

352.3 KB
doc/imgs/tagspace.png
0 → 100644
{kind=link}

134.0 KB
doc/imgs/wide&deep.png
0 → 100644
{kind=link}
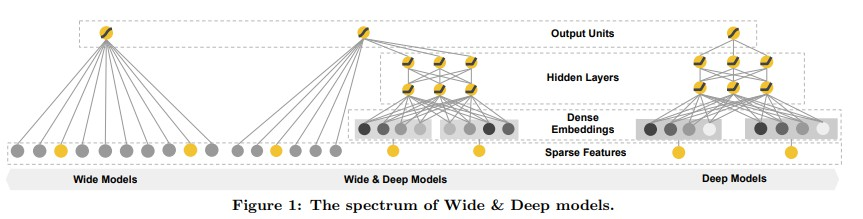
151.9 KB
doc/imgs/word2vec.png
0 → 100644
{kind=link}
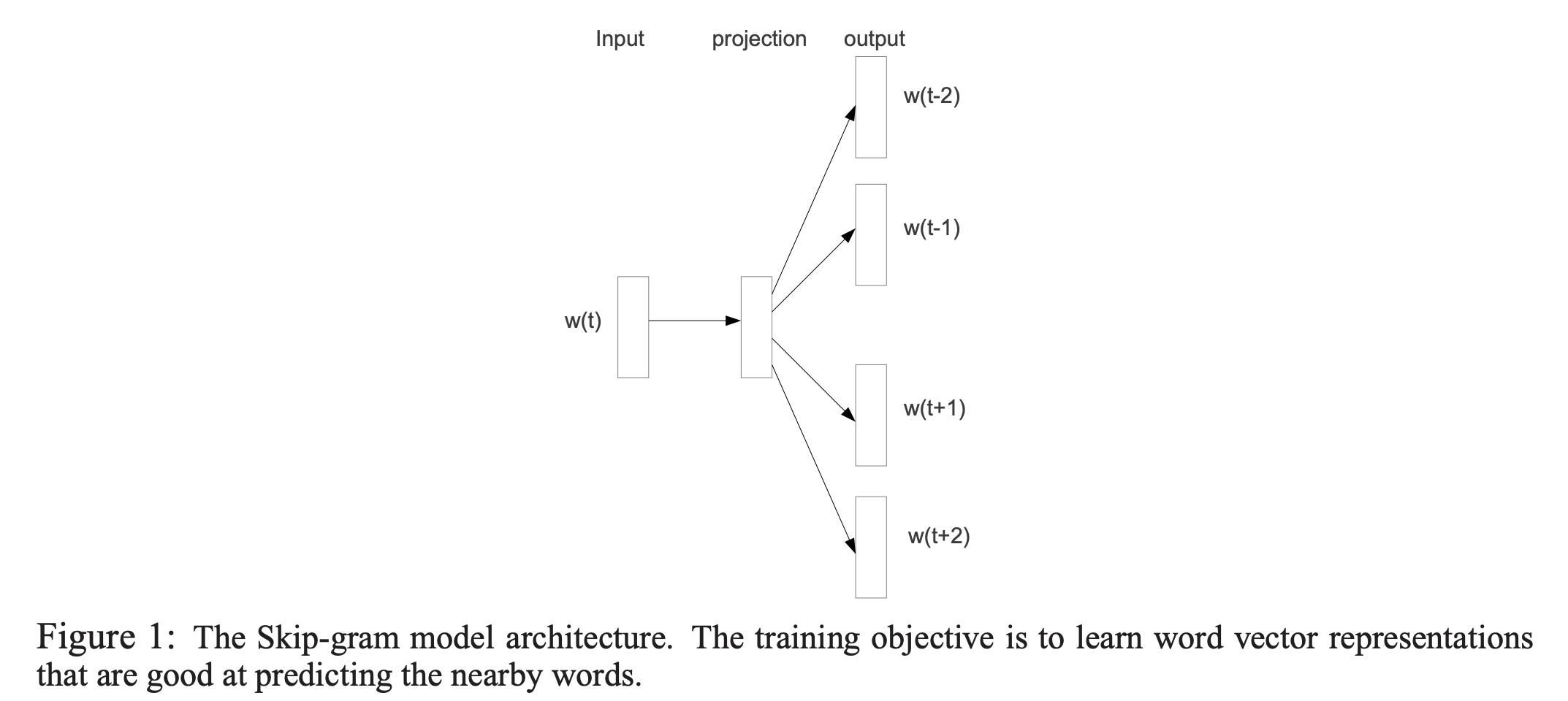
108.7 KB
doc/imgs/xdeepfm.png
0 → 100644
{kind=link}
95.5 KB
doc/imgs/youtube_dnn.png
0 → 100644
{kind=link}
214.9 KB
doc/local_train.md
0 → 100644
doc/model_list.md
0 → 100644
doc/optimization_model.md
0 → 100644
doc/predict.md
0 → 100644
doc/ps_background.md
0 → 100644
doc/rec_background.md
0 → 100644
models/__init__.py
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
models/match/__init__.py
0 → 100755
models/match/dssm/__init__.py
0 → 100755
此差异已折叠。
models/match/dssm/config.yaml
0 → 100755
此差异已折叠。
此差异已折叠。
models/match/dssm/model.py
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
models/match/readme.md
0 → 100755
此差异已折叠。
models/multitask/__init__.py
0 → 100755
models/multitask/esmm/__init__.py
0 → 100755
此差异已折叠。
models/multitask/esmm/config.yaml
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
models/multitask/esmm/model.py
0 → 100644
此差异已折叠。
models/multitask/mmoe/__init__.py
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
models/multitask/mmoe/config.yaml
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
models/multitask/mmoe/model.py
0 → 100644
此差异已折叠。
models/multitask/readme.md
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
models/rank/__init__.py
0 → 100755
models/rank/dcn/__init__.py
0 → 100755
此差异已折叠。
models/rank/dcn/config.yaml
0 → 100755
此差异已折叠。
models/rank/dcn/data/download.py
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
models/rank/dcn/data/run.sh
0 → 100644
此差异已折叠。
models/rank/dcn/model.py
0 → 100755
此差异已折叠。
models/rank/deepfm/__init__.py
0 → 100755
此差异已折叠。
models/rank/deepfm/config.yaml
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
models/rank/deepfm/data/run.sh
0 → 100644
此差异已折叠。
models/rank/deepfm/model.py
0 → 100755
此差异已折叠。
models/rank/din/__init__.py
0 → 100755
此差异已折叠。
models/rank/din/config.yaml
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
models/rank/din/data/remap_id.py
0 → 100755
此差异已折叠。
此差异已折叠。
models/rank/din/model.py
0 → 100755
此差异已折叠。
models/rank/din/reader.py
0 → 100755
此差异已折叠。
models/rank/dnn/README.md
0 → 100644
此差异已折叠。
models/rank/dnn/__init__.py
0 → 100755
此差异已折叠。
models/rank/dnn/config.yaml
0 → 100755
此差异已折叠。
models/rank/dnn/data/download.sh
0 → 100644
此差异已折叠。
此差异已折叠。
models/rank/dnn/data/run.sh
0 → 100644
此差异已折叠。
models/rank/dnn/model.py
0 → 100755
此差异已折叠。
models/rank/readme.md
0 → 100755
此差异已折叠。
models/rank/wide_deep/__init__.py
0 → 100755
此差异已折叠。
models/rank/wide_deep/config.yaml
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
models/rank/wide_deep/data/run.sh
0 → 100644
此差异已折叠。
models/rank/wide_deep/model.py
0 → 100755
此差异已折叠。
models/rank/xdeepfm/__init__.py
0 → 100755
此差异已折叠。
models/rank/xdeepfm/config.yaml
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
models/rank/xdeepfm/data/run.sh
0 → 100644
此差异已折叠。
models/rank/xdeepfm/model.py
0 → 100755
此差异已折叠。
models/recall/__init__.py
0 → 100755
models/recall/gnn/__init__.py
0 → 100755
此差异已折叠。
models/recall/gnn/config.yaml
0 → 100755
此差异已折叠。
models/recall/gnn/data/config.txt
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
models/recall/gnn/data_process.sh
0 → 100755
此差异已折叠。
此差异已折叠。
models/recall/gnn/model.py
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
models/recall/gnn/reader.py
0 → 100755
此差异已折叠。
models/recall/gru4rec/__init__.py
0 → 100755
此差异已折叠。
models/recall/gru4rec/config.yaml
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
models/recall/gru4rec/model.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
models/recall/ncf/__init__.py
0 → 100755
此差异已折叠。
models/recall/ncf/config.yaml
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
models/recall/ncf/model.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
models/recall/readme.md
0 → 100755
此差异已折叠。
models/recall/ssr/__init__.py
0 → 100755
此差异已折叠。
models/recall/ssr/config.yaml
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
models/recall/ssr/model.py
0 → 100644
此差异已折叠。
此差异已折叠。
models/recall/ssr/ssr_reader.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
models/recall/word2vec/model.py
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
models/treebased/README.md
0 → 100644
此差异已折叠。
models/treebased/__init__.py
0 → 100644
models/treebased/tdm/README.md
0 → 100644
此差异已折叠。
models/treebased/tdm/__init__.py
0 → 100755
models/treebased/tdm/config.yaml
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
models/treebased/tdm/model.py
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
run.py
0 → 100755
此差异已折叠。
setup.py
0 → 100644
此差异已折叠。
tests/__init__.py
0 → 100755
tools/__init__.py
0 → 100644
tools/tools.py
0 → 100644
此差异已折叠。