Merge remote-tracking branch 'upstream/develop' into develop
Showing
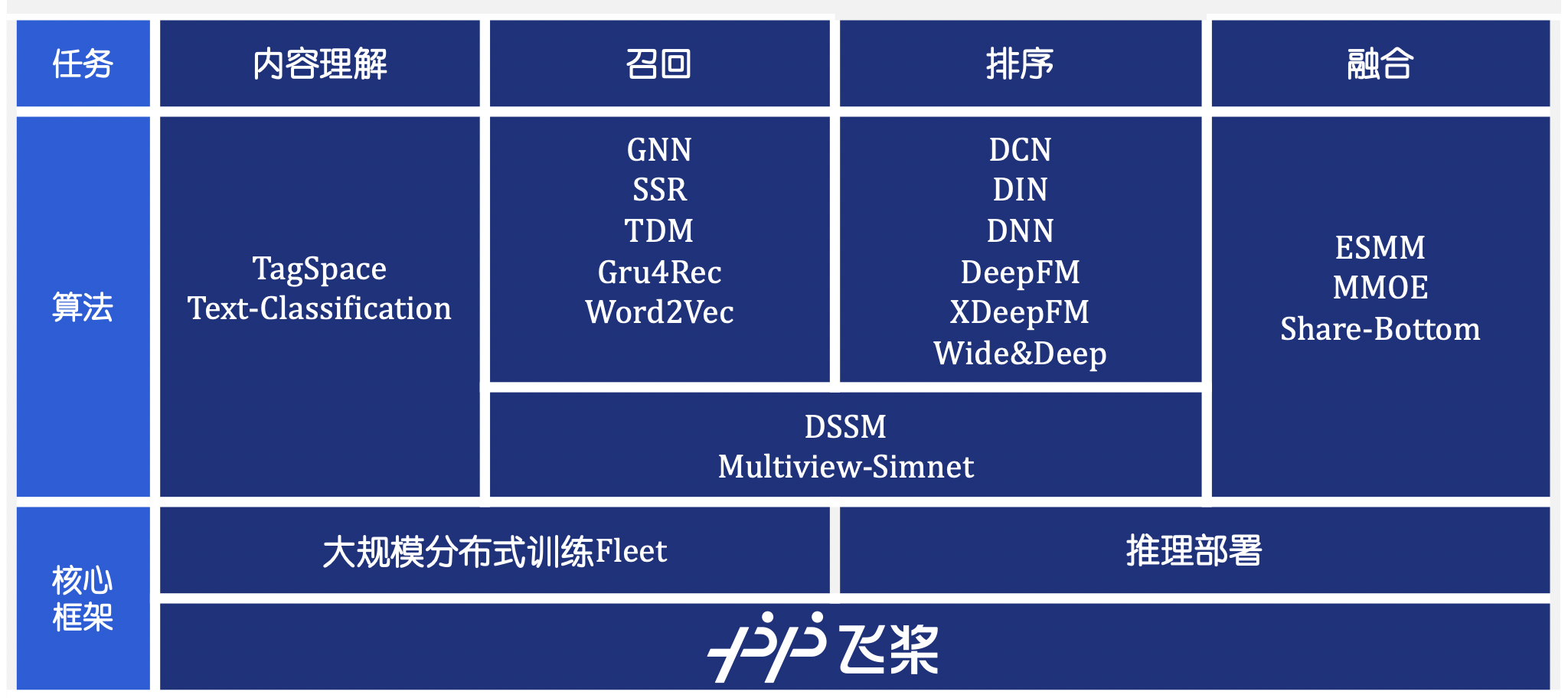
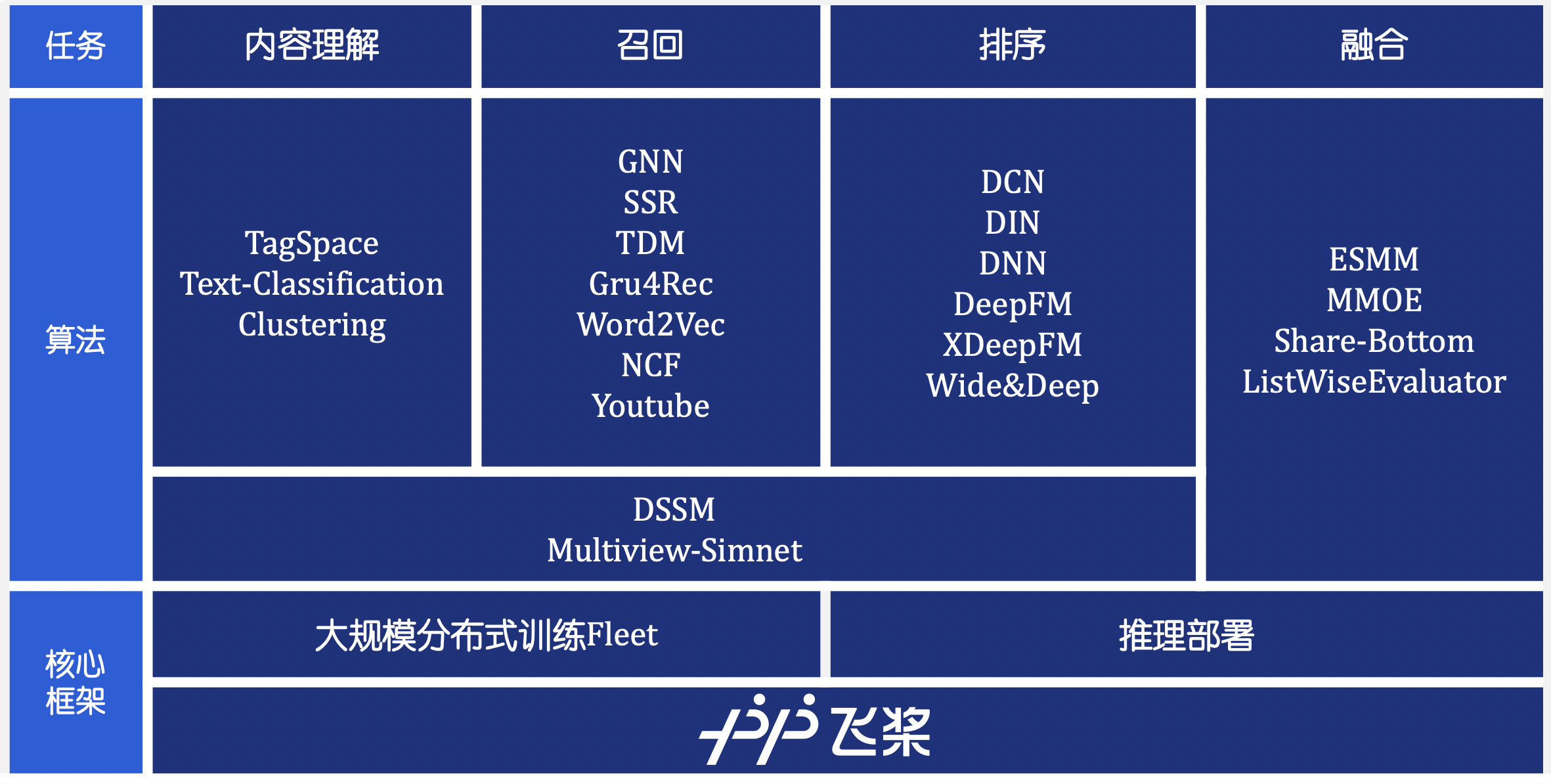
doc/imgs/design.png
0 → 100644
{kind=link}
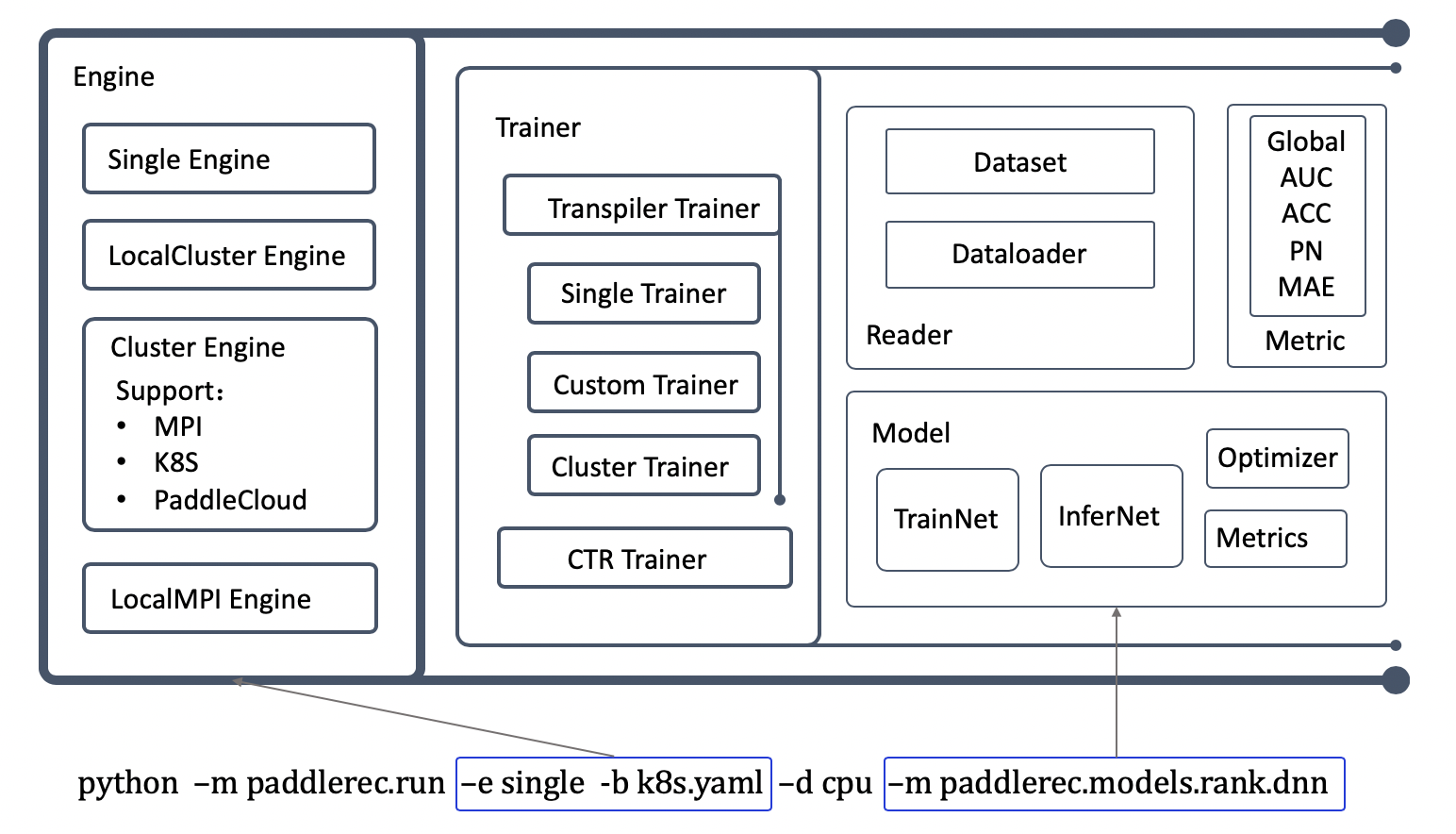
456.1 KB
doc/imgs/dssm.png
0 → 100644
{kind=link}
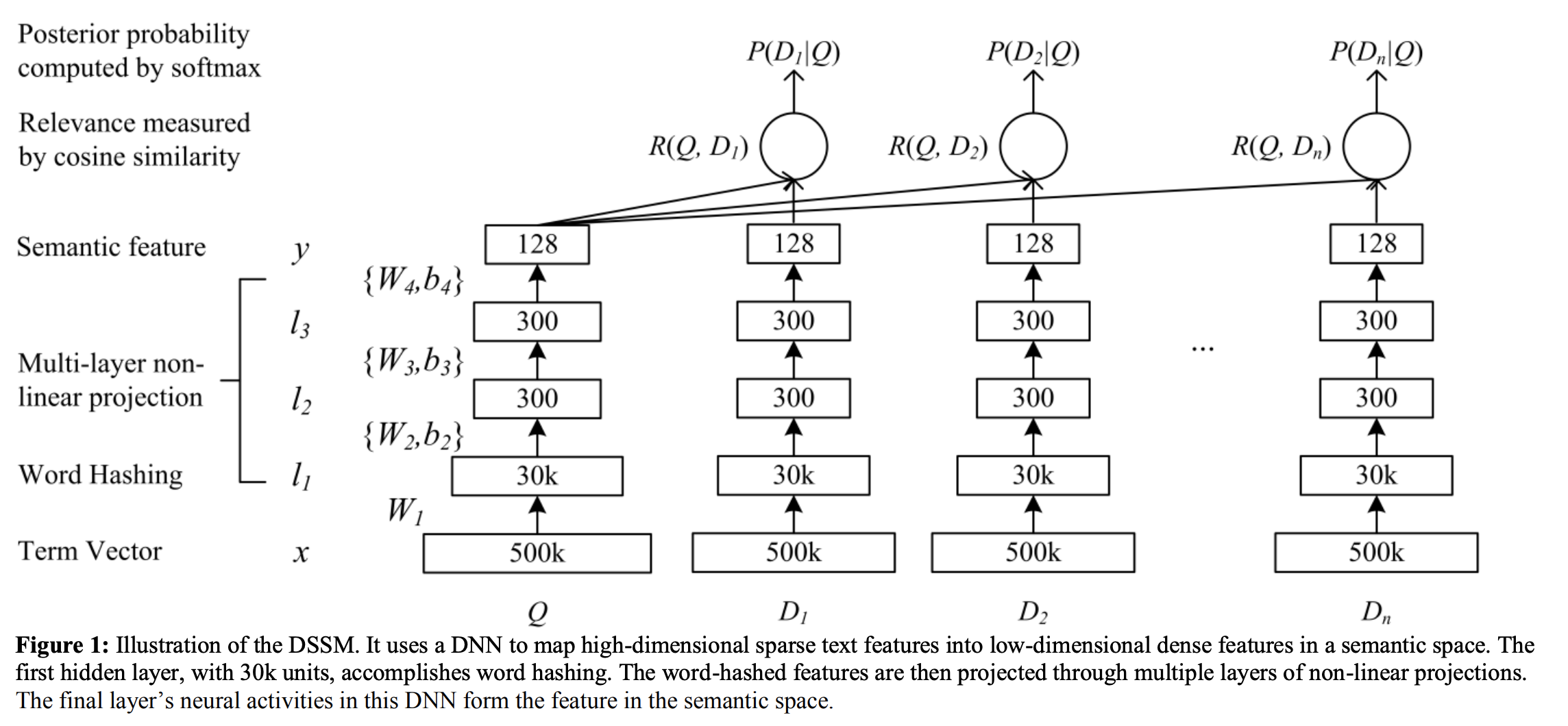
373.8 KB
doc/imgs/gnn.png
0 → 100644
{kind=link}
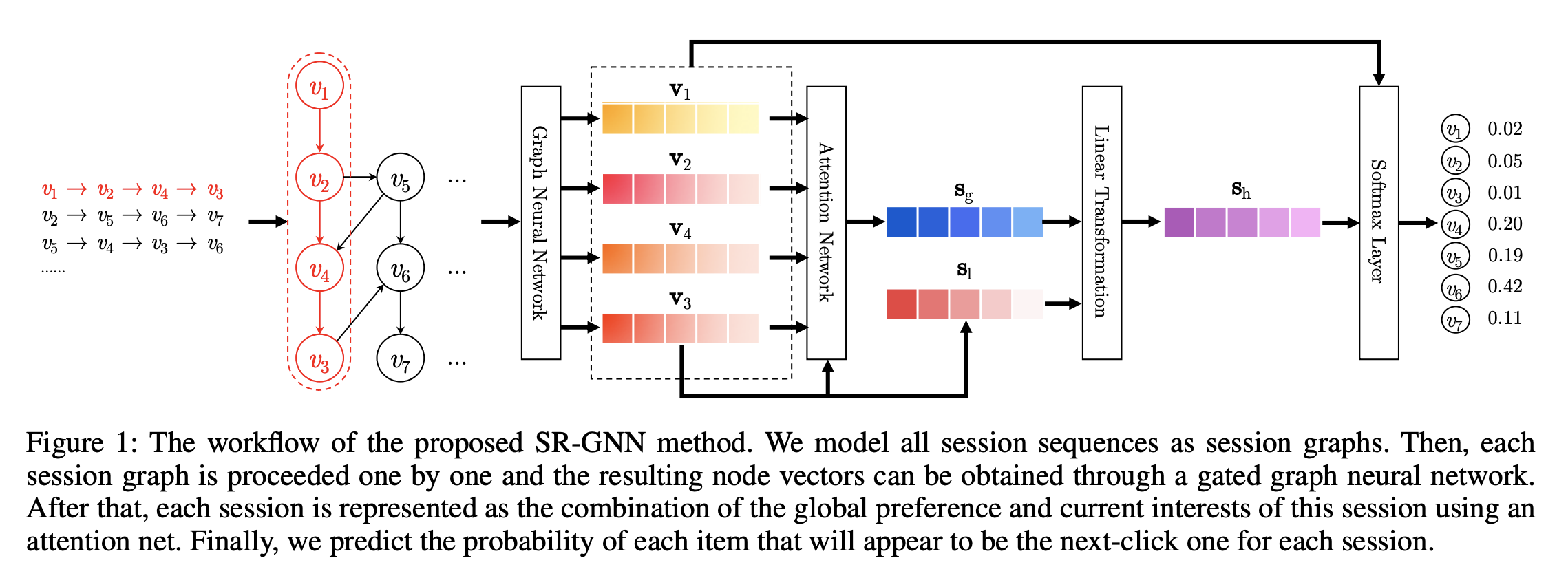
247.5 KB
doc/imgs/gru4rec.png
0 → 100644
{kind=link}
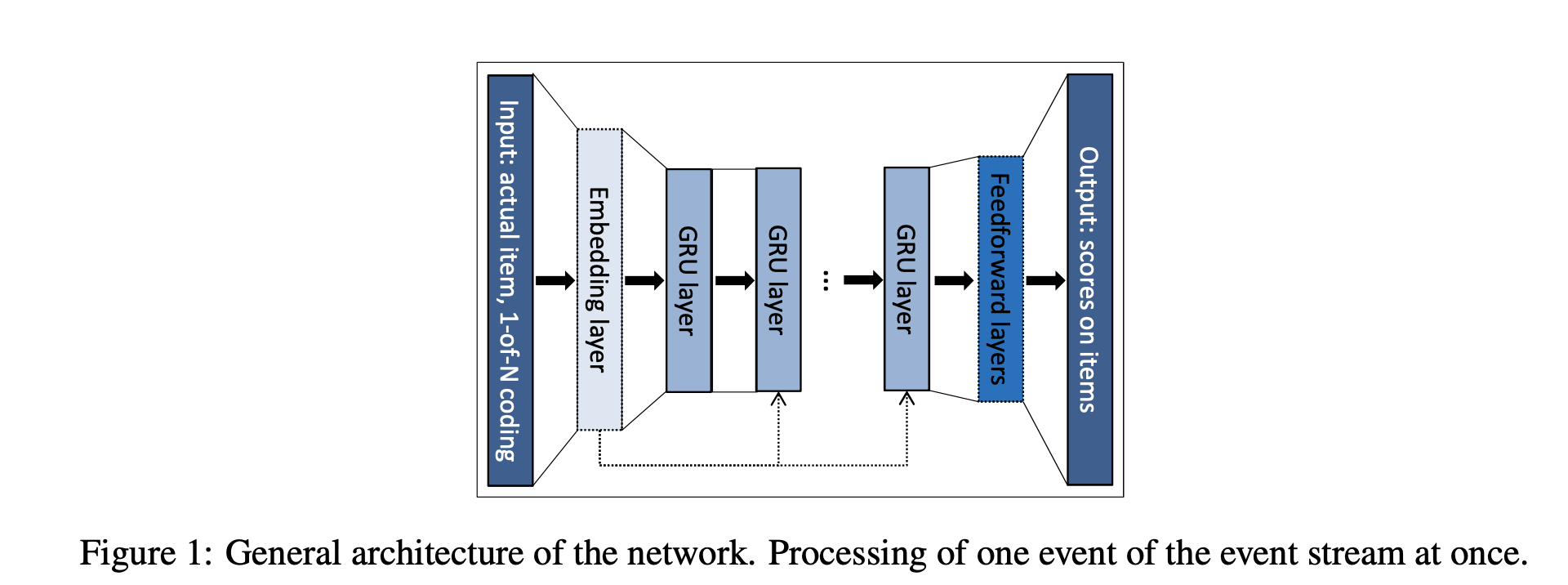
124.1 KB
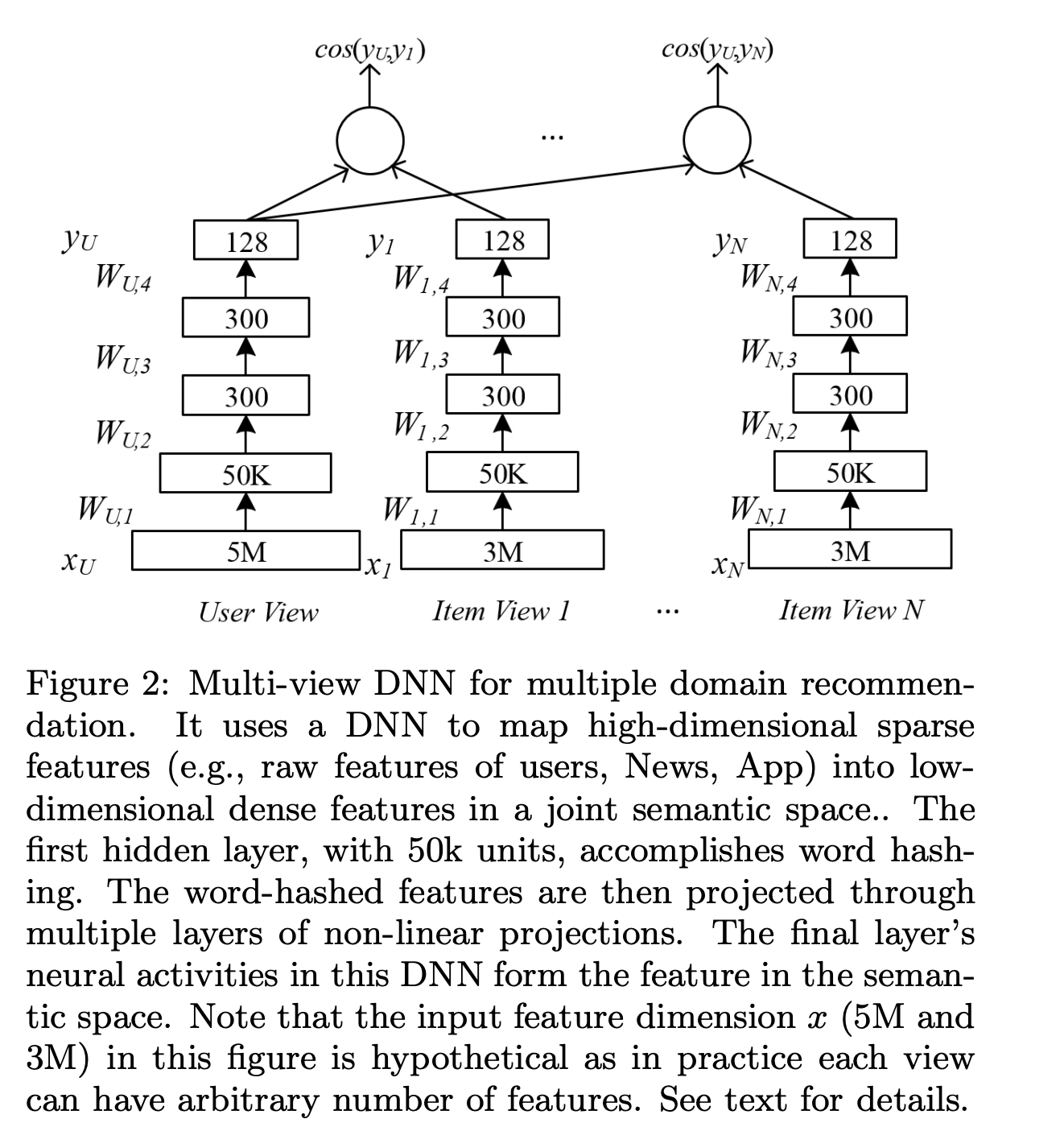
doc/imgs/multiview-simnet.png
0 → 100644
{kind=link}
303.1 KB
{kind=link}
{kind=link}
| W: | H:
| W: | H:
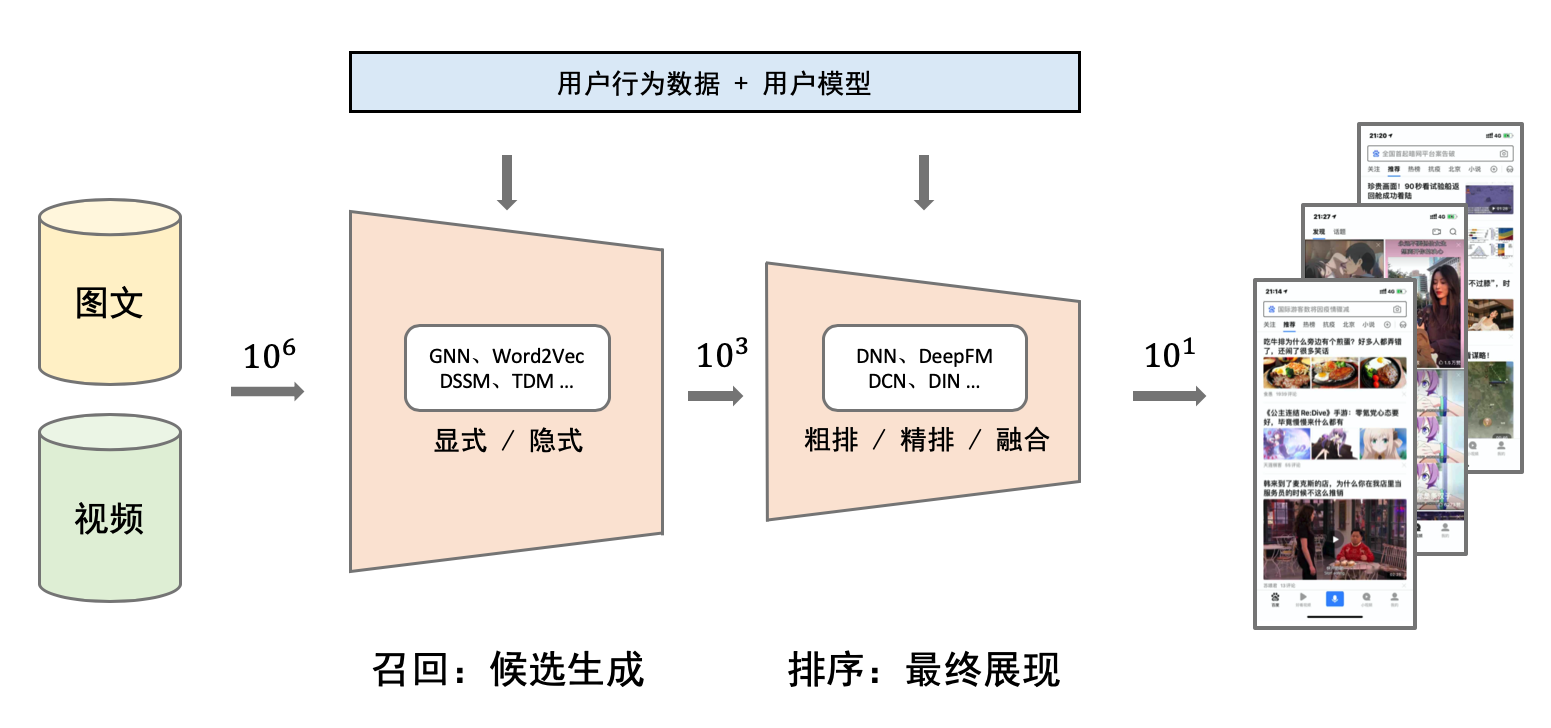
doc/imgs/rec-overview.png
0 → 100644
{kind=link}
267.3 KB
doc/imgs/ssr.png
0 → 100644
{kind=link}
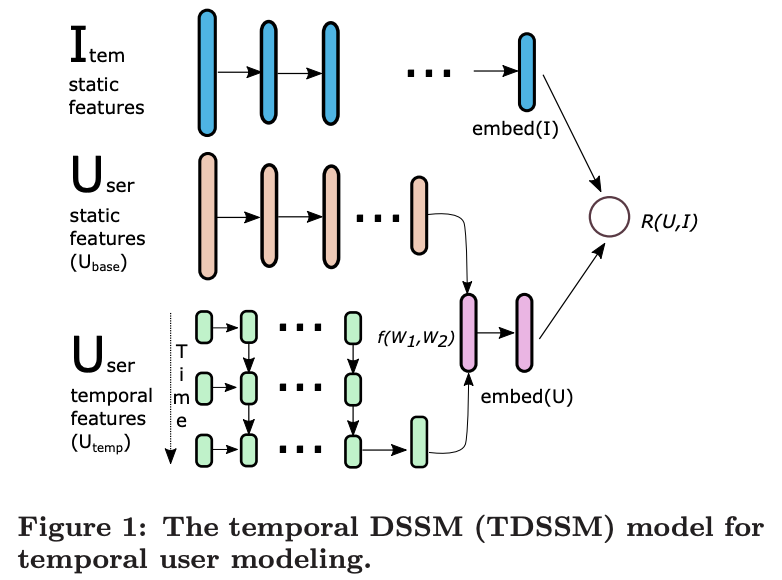
77.4 KB
doc/imgs/word2vec.png
0 → 100644
{kind=link}
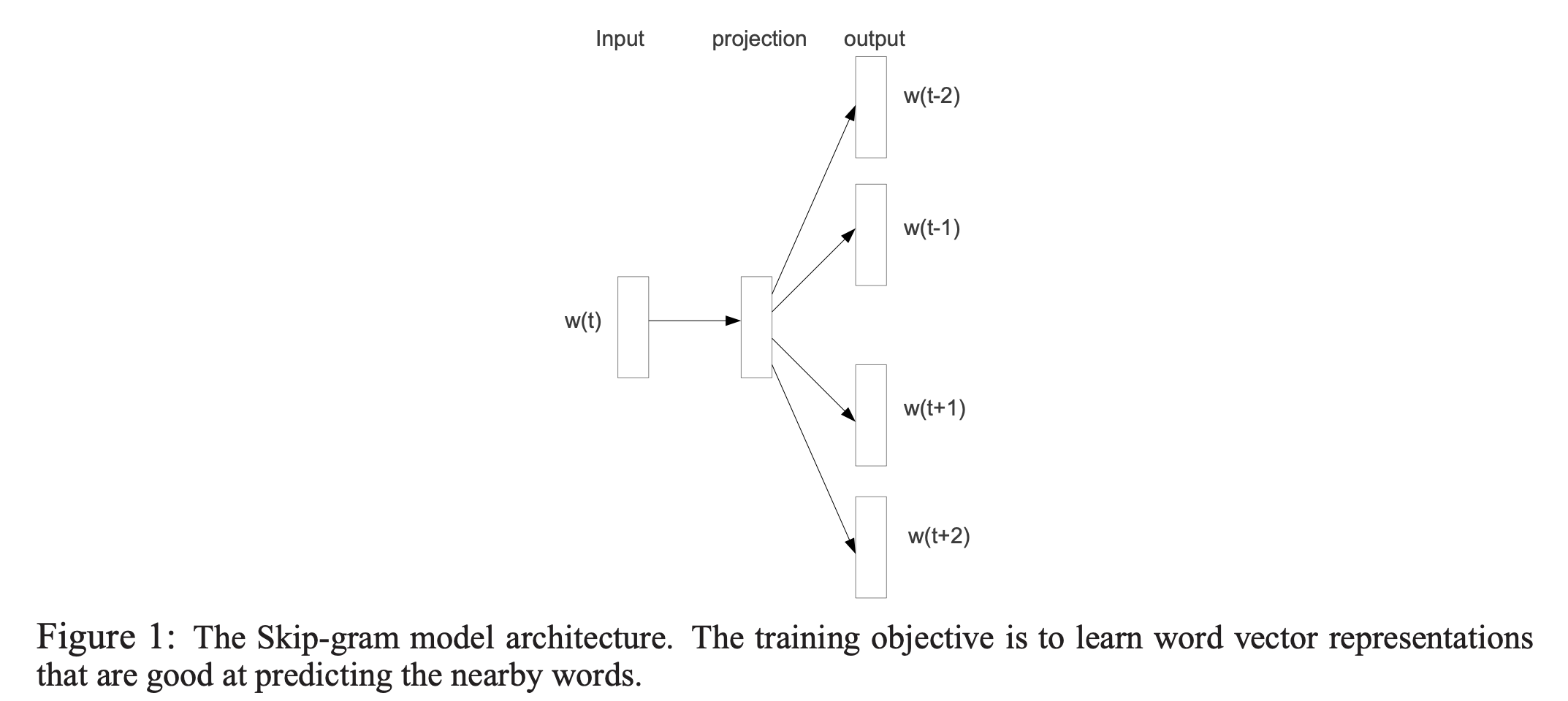
108.7 KB
example/__init__.py
已删除
100644 → 0
example/cloud/backend.yaml
已删除
100755 → 0
example/cloud/before_hook.sh
已删除
100644 → 0
example/cloud/config.ini
已删除
100644 → 0
example/cloud/config.yaml
已删除
100755 → 0
example/cloud/job.sh
已删除
100644 → 0
example/cloud/submit.sh
已删除
100644 → 0
example/mpi/__init__.py
已删除
100644 → 0
example/mpi/backend.yaml
已删除
100755 → 0
example/mpi/job.sh
已删除
100644 → 0
example/mpi/submit.sh
已删除
100644 → 0
models/rank/criteo_reader.py
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。