Update docs
Showing
doc/.buildinfo
0 → 100644
doc/_images/FullyConnected.jpg
0 → 100644
{kind=link}
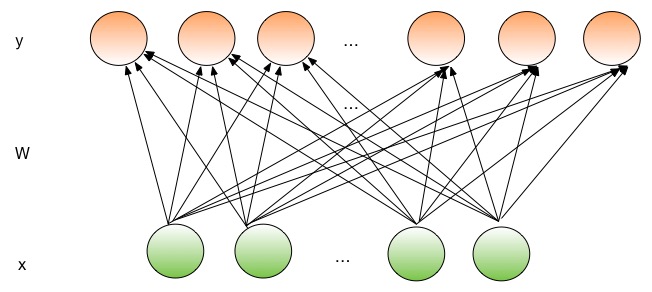
49.7 KB
doc/_images/NetContinuous_en.png
0 → 100644
{kind=link}
59.0 KB
doc/_images/NetConv_en.png
0 → 100644
{kind=link}
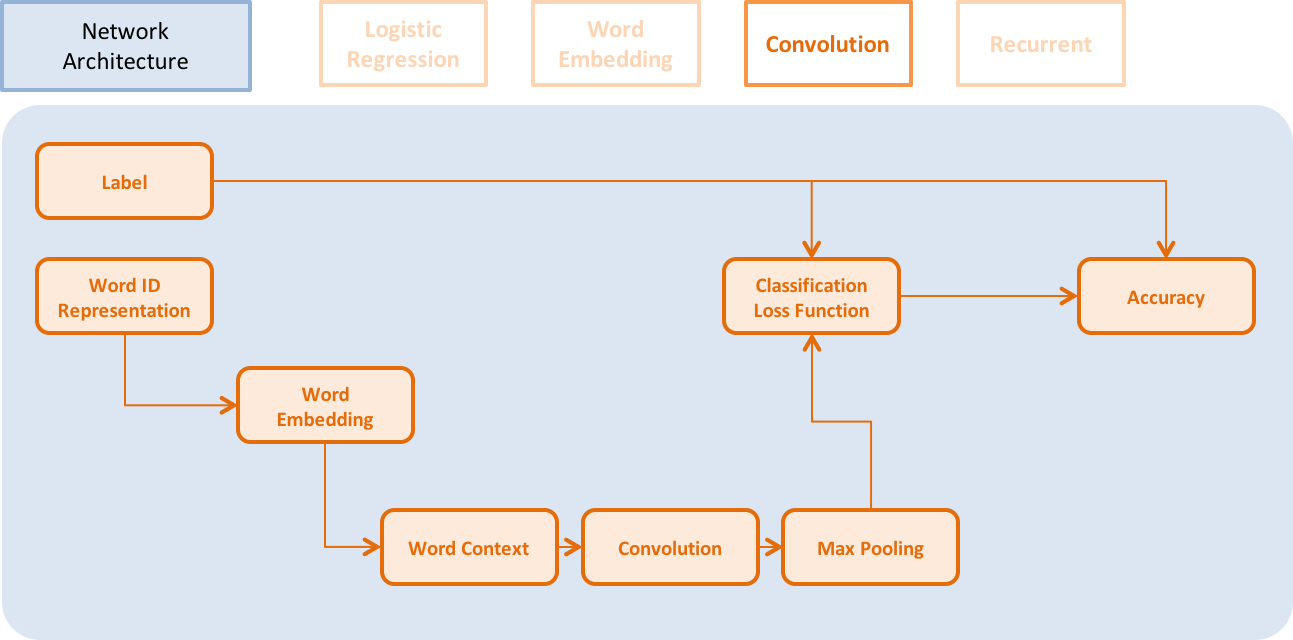
67.3 KB
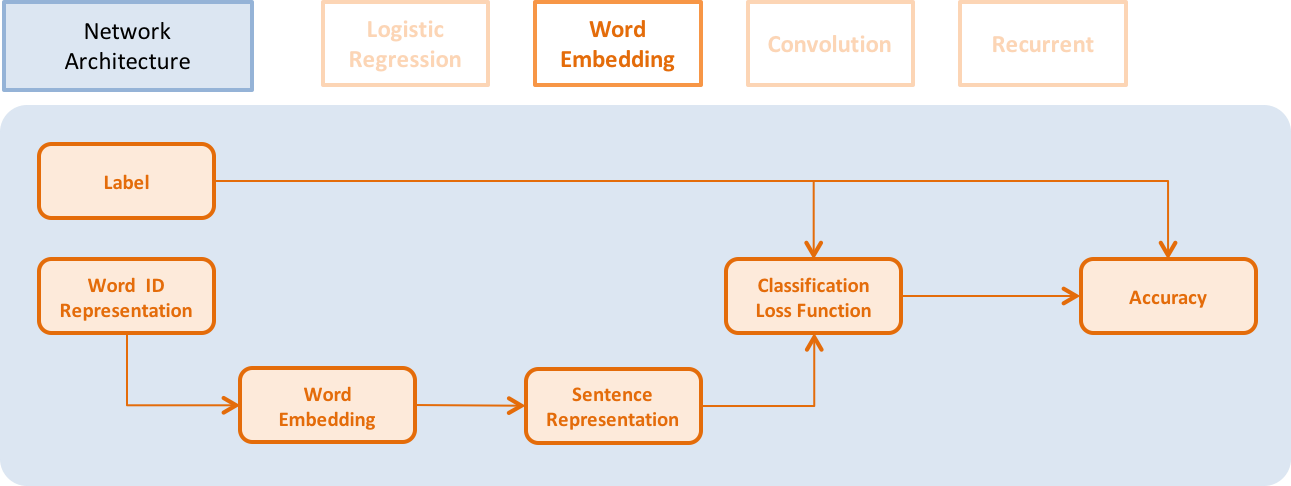
doc/_images/NetLR_en.png
0 → 100644
{kind=link}
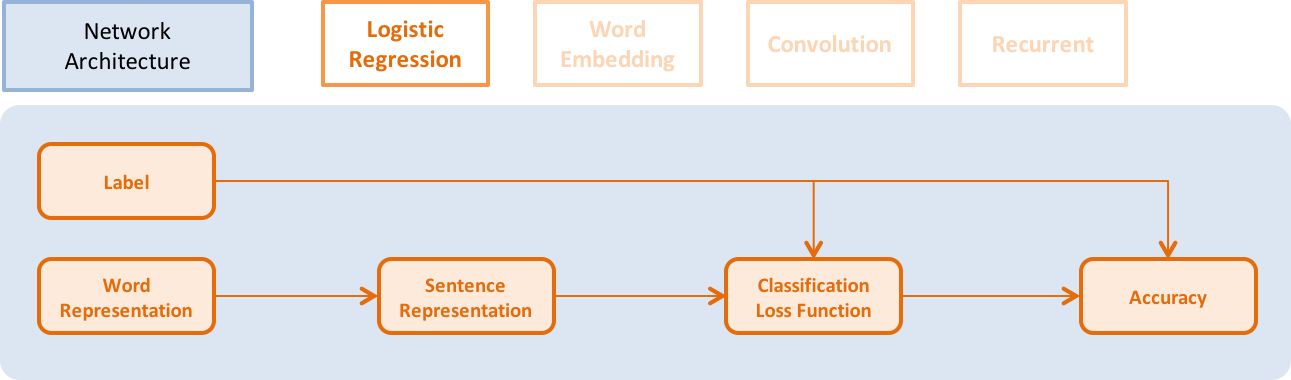
49.8 KB
doc/_images/NetRNN_en.png
0 → 100644
{kind=link}
70.3 KB
{kind=link}

7.3 KB
doc/_images/PipelineTest_en.png
0 → 100644
{kind=link}

13.8 KB
doc/_images/PipelineTrain_en.png
0 → 100644
{kind=link}

13.8 KB
doc/_images/Pipeline_en.jpg
0 → 100644
{kind=link}

11.4 KB
doc/_images/bi_lstm.jpg
0 → 100644
{kind=link}
34.8 KB
doc/_images/cifar.png
0 → 100644
{kind=link}

455.6 KB
{kind=link}
66.5 KB
doc/_images/feature.jpg
0 → 100644
{kind=link}
30.5 KB
{kind=link}
51.4 KB
doc/_images/lenet.png
0 → 100644
{kind=link}
48.7 KB
doc/_images/lstm.png
0 → 100644
{kind=link}
49.5 KB
doc/_images/network_arch.png
0 → 100644
{kind=link}
27.2 KB
{kind=link}
66.9 KB
doc/_images/plot.png
0 → 100644
{kind=link}
30.3 KB
{kind=link}
81.2 KB
doc/_images/resnet_block.jpg
0 → 100644
{kind=link}
21.9 KB
doc/_images/stacked_lstm.jpg
0 → 100644
{kind=link}
30.3 KB
doc/_sources/build/index.txt
0 → 100644
doc/_sources/cluster/index.txt
0 → 100644
doc/_sources/demo/index.txt
0 → 100644
此差异已折叠。
doc/_sources/index.txt
0 → 100644
doc/_sources/source/api/api.txt
0 → 100644
doc/_sources/source/index.txt
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/_sources/ui/index.txt
0 → 100644
此差异已折叠。
doc/_static/ajax-loader.gif
0 → 100644
{kind=link}
此差异已折叠。
doc/_static/basic.css
0 → 100644
此差异已折叠。
doc/_static/classic.css
0 → 100644
此差异已折叠。
doc/_static/comment-bright.png
0 → 100644
{kind=link}
此差异已折叠。
doc/_static/comment-close.png
0 → 100644
{kind=link}
此差异已折叠。
doc/_static/comment.png
0 → 100644
{kind=link}
此差异已折叠。
doc/_static/doctools.js
0 → 100644
此差异已折叠。
doc/_static/down-pressed.png
0 → 100644
{kind=link}
此差异已折叠。
doc/_static/down.png
0 → 100644
{kind=link}
此差异已折叠。
doc/_static/file.png
0 → 100644
{kind=link}
此差异已折叠。
doc/_static/jquery-1.11.1.js
0 → 100644
此差异已折叠。
doc/_static/jquery.js
0 → 100644
此差异已折叠。
doc/_static/minus.png
0 → 100644
{kind=link}
此差异已折叠。
doc/_static/plus.png
0 → 100644
{kind=link}
此差异已折叠。
doc/_static/pygments.css
0 → 100644
此差异已折叠。
doc/_static/searchtools.js
0 → 100644
此差异已折叠。
doc/_static/sidebar.js
0 → 100644
此差异已折叠。
doc/_static/underscore-1.3.1.js
0 → 100644
此差异已折叠。
doc/_static/underscore.js
0 → 100644
此差异已折叠。
doc/_static/up-pressed.png
0 → 100644
{kind=link}
此差异已折叠。
doc/_static/up.png
0 → 100644
{kind=link}
此差异已折叠。
doc/_static/websupport.js
0 → 100644
此差异已折叠。
doc/build/build_from_source.html
0 → 100644
此差异已折叠。
此差异已折叠。
doc/build/index.html
0 → 100644
此差异已折叠。
doc/cluster/index.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/demo/index.html
0 → 100644
此差异已折叠。
doc/demo/new_layer/index.html
0 → 100644
此差异已折叠。
此差异已折叠。
doc/demo/rec/ml_dataset.html
0 → 100644
此差异已折叠。
doc/demo/rec/ml_regression.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/genindex.html
0 → 100644
此差异已折叠。
doc/index.html
0 → 100644
此差异已折叠。
doc/objects.inv
0 → 100644
此差异已折叠。
doc/py-modindex.html
0 → 100644
此差异已折叠。
doc/search.html
0 → 100644
此差异已折叠。
doc/searchindex.js
0 → 100644
此差异已折叠。
doc/source/api/api.html
0 → 100644
此差异已折叠。
doc/source/cuda/cuda/cuda.html
0 → 100644
此差异已折叠。
doc/source/cuda/cuda/index.html
0 → 100644
此差异已折叠。
doc/source/cuda/matrix/index.html
0 → 100644
此差异已折叠。
此差异已折叠。
doc/source/cuda/rnn/index.html
0 → 100644
此差异已折叠。
doc/source/cuda/rnn/rnn.html
0 → 100644
此差异已折叠。
doc/source/cuda/utils/index.html
0 → 100644
此差异已折叠。
doc/source/cuda/utils/utils.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/source/index.html
0 → 100644
此差异已折叠。
doc/source/math/matrix/index.html
0 → 100644
此差异已折叠。
此差异已折叠。
doc/source/math/utils/index.html
0 → 100644
此差异已折叠。
doc/source/math/utils/utils.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/source/trainer/trainer.html
0 → 100644
此差异已折叠。
此差异已折叠。
doc/source/utils/enum.html
0 → 100644
此差异已折叠。
doc/source/utils/lock.html
0 → 100644
此差异已折叠。
doc/source/utils/queue.html
0 → 100644
此差异已折叠。
doc/source/utils/thread.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/ui/cmd_argument/use_case.html
0 → 100644
此差异已折叠。
doc/ui/data_provider/index.html
0 → 100644
此差异已折叠。
此差异已折叠。
doc/ui/index.html
0 → 100644
此差异已折叠。
此差异已折叠。
doc_cn/.buildinfo
0 → 100644
此差异已折叠。
doc_cn/_images/NetContinuous.jpg
0 → 100644
{kind=link}
此差异已折叠。
doc_cn/_images/NetConv.jpg
0 → 100644
{kind=link}
此差异已折叠。
doc_cn/_images/NetLR.jpg
0 → 100644
{kind=link}
此差异已折叠。
doc_cn/_images/NetRNN.jpg
0 → 100644
{kind=link}
此差异已折叠。
doc_cn/_images/Pipeline.jpg
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc_cn/_images/PipelineTest.jpg
0 → 100644
{kind=link}
此差异已折叠。
doc_cn/_images/PipelineTrain.jpg
0 → 100644
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc_cn/_sources/cluster/index.txt
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc_cn/_sources/demo/index.txt
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc_cn/_sources/index.txt
0 → 100644
此差异已折叠。
doc_cn/_sources/ui/cmd/index.txt
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc_cn/_sources/ui/index.txt
0 → 100644
此差异已折叠。
此差异已折叠。
doc_cn/_static/ajax-loader.gif
0 → 100644
{kind=link}
此差异已折叠。
doc_cn/_static/basic.css
0 → 100644
此差异已折叠。
doc_cn/_static/classic.css
0 → 100644
此差异已折叠。
doc_cn/_static/comment-bright.png
0 → 100644
{kind=link}
此差异已折叠。
doc_cn/_static/comment-close.png
0 → 100644
{kind=link}
此差异已折叠。
doc_cn/_static/comment.png
0 → 100644
{kind=link}
此差异已折叠。
doc_cn/_static/doctools.js
0 → 100644
此差异已折叠。
doc_cn/_static/down-pressed.png
0 → 100644
{kind=link}
此差异已折叠。
doc_cn/_static/down.png
0 → 100644
{kind=link}
此差异已折叠。
doc_cn/_static/file.png
0 → 100644
{kind=link}
此差异已折叠。
doc_cn/_static/jquery-1.11.1.js
0 → 100644
此差异已折叠。
doc_cn/_static/jquery.js
0 → 100644
此差异已折叠。
doc_cn/_static/minus.png
0 → 100644
{kind=link}
此差异已折叠。
doc_cn/_static/plus.png
0 → 100644
{kind=link}
此差异已折叠。
doc_cn/_static/pygments.css
0 → 100644
此差异已折叠。
doc_cn/_static/searchtools.js
0 → 100644
此差异已折叠。
doc_cn/_static/sidebar.js
0 → 100644
此差异已折叠。
此差异已折叠。
doc_cn/_static/underscore.js
0 → 100644
此差异已折叠。
doc_cn/_static/up-pressed.png
0 → 100644
{kind=link}
此差异已折叠。
doc_cn/_static/up.png
0 → 100644
{kind=link}
此差异已折叠。
doc_cn/_static/websupport.js
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc_cn/cluster/index.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc_cn/demo/index.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc_cn/genindex.html
0 → 100644
此差异已折叠。
doc_cn/index.html
0 → 100644
此差异已折叠。
doc_cn/objects.inv
0 → 100644
此差异已折叠。
doc_cn/search.html
0 → 100644
此差异已折叠。
doc_cn/searchindex.js
0 → 100644
此差异已折叠。
doc_cn/ui/cmd/dump_config.html
0 → 100644
此差异已折叠。
doc_cn/ui/cmd/index.html
0 → 100644
此差异已折叠。
doc_cn/ui/cmd/make_diagram.html
0 → 100644
此差异已折叠。
doc_cn/ui/cmd/merge_model.html
0 → 100644
此差异已折叠。
doc_cn/ui/cmd/paddle_pserver.html
0 → 100644
此差异已折叠。
doc_cn/ui/cmd/paddle_train.html
0 → 100644
此差异已折叠。
doc_cn/ui/cmd/paddle_version.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc_cn/ui/index.html
0 → 100644
此差异已折叠。
此差异已折叠。