Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
BaiXuePrincess
Paddle
提交
f839e91b
P
Paddle
项目概览
BaiXuePrincess
/
Paddle
与 Fork 源项目一致
Fork自
PaddlePaddle / Paddle
通知
1
Star
1
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
Paddle
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
f839e91b
编写于
3月 14, 2018
作者:
Y
Yancey1989
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
update by comment
上级
b3827473
变更
4
隐藏空白更改
内联
并排
Showing
4 changed file
with
28 addition
and
24 deletion
+28
-24
doc/fluid/design/dist_train/large_model.md
doc/fluid/design/dist_train/large_model.md
+28
-24
doc/fluid/design/dist_train/src/prefetch_parameters.graffle
doc/fluid/design/dist_train/src/prefetch_parameters.graffle
+0
-0
doc/fluid/design/dist_train/src/split_parameter.graffle
doc/fluid/design/dist_train/src/split_parameter.graffle
+0
-0
doc/fluid/design/dist_train/src/split_parameter.png
doc/fluid/design/dist_train/src/split_parameter.png
+0
-0
未找到文件。
doc/fluid/design/dist_train/large_model.md
浏览文件 @
f839e91b
# Design Doc:
Large Model
# Design Doc:
Prefecting Parameter From Parameter Server
## Abstract
## Abstract
We propose an approach to support the large parameter.
We propose an approach to prefetch parameter from Parameter
For embedding layer, the parameter may very large and could
Server while distributed training so that Fluid would training
not be stored in one trainer's memory. In this approach, a Trainer would
a model including the large parameter which could not be stored in one
prefetch a sliced parameter from different Parameter Server instances
trainer's memory.
according to the input
`Ids`
, and then run forward, backward and send
the gradient to Parameter Server to execute the optimize program.
## Background
For an embedding layer, the trainable parameter may be very large and could
not be stored in one trainer's memory. In Fluid distributed training,
[
Distributed Transpiler
](
./parameter_server.md#distributed-transpiler
)
would split every parameter into a number of small
parameters and stored in Parameter Server, so we could prefetch the parameter
from the specified Parameter Server according to the input
`Ids`
.
## Design
## Design
**NOTE**
: this approach is a feature of Fluid distributed tria
ning, maybe you want
This is a feature of Fluid distributed trai
ning, maybe you want
to know
[
Distributed Architecture
](
./distributed_architecture.md
)
and
to know
[
Distributed Architecture
](
./distributed_architecture.md
)
and
[
Parameter Server
](
./parameter_server.md
)
before reading the following content.
[
Parameter Server
](
./parameter_server.md
)
before reading the following content.
Fluid large model distributed training use
### Partationed Parameter
[
Distributed Transpiler
](
./parameter_server.md#distributed-transpiler
)
to split
a large parameter into multiple parameters which stored on Parameter Server, and
the Trainer would prefetch them by
`RPC`
interface.
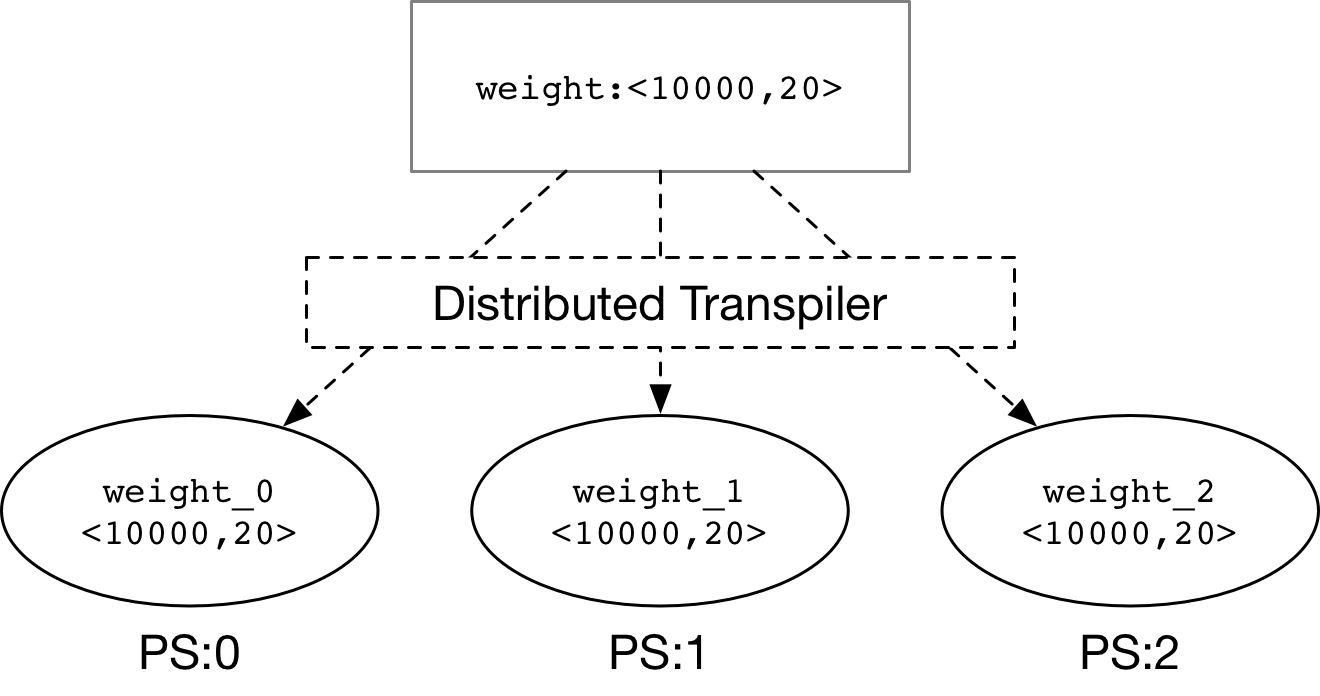
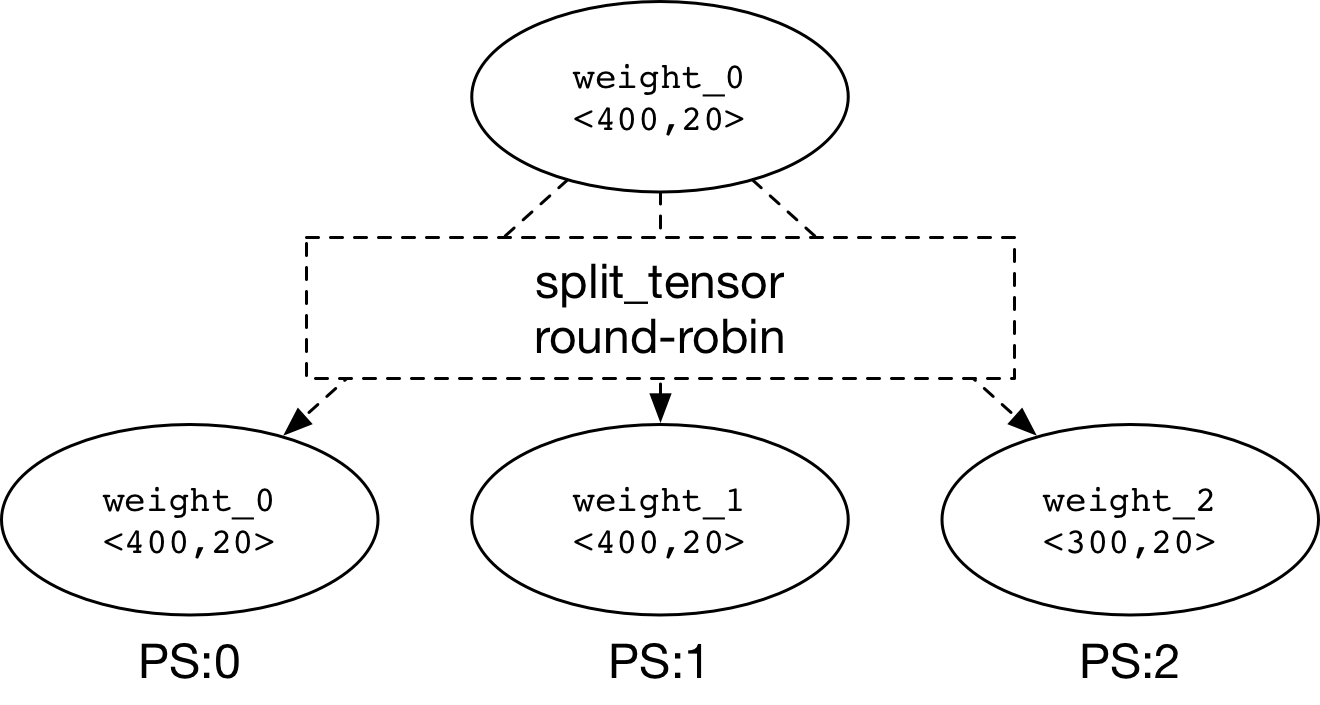
### Split Large Parameter
<img
src=
"src/split_parameter.png"
width=
"400"
/>
<img
src=
"src/split_parameter.png"
width=
"400"
/>
**Distributed Transpiler**
would split the large parameter
-
**Distributed Transpiler**
would split the large parameter
(weight) into some
sliced parameters (weight_0, weight_1, weight_2) as the
(weight) into some
partitioned parameters (weight_0, weight_1, weight_2) as the
figure above.
figure above.
-
We could use
`round-robin`
to distribute the partitioned parameter.
### Prefetch
Parameters from Parameter Servers
### Prefetch
ing Parameter
<img
src=
"src/prefetch_parameters.png"
width=
"400"
/>
<img
src=
"src/prefetch_parameters.png"
width=
"400"
/>
-
`PrefetchRpc`
operator would send the rows index the multiple Parameter Servers,
-
`prefetch_rpc`
operator would prefetch the parameter from different Parameter
and then receive the SelctedRows.
Server according with the input
`Ids`
, we use
[
SelectedRows
](
../../../design/selected_rows.md
)
-
The different with normal Fluid distributed training, we only prefetch the rows
as the received variable type.
-
`merge_selected_rows`
operator would merge the received parameters into one
`SelectedRows`
variable.
## TODO
## TODO
-
Async Update
-
`prefetch_rpc`
operator to send rows index and receive SelectedRows variables.
-
`lookup_table`
need to support
`SelectedRows`
variable type as input
`Weight`
.
To avoid slow-node, Async update is important for distributed training,
-
Async Update,
To avoid slow-node, Async update is important for distributed training,
we need a
n
design doc and implement it in future.
we need a design doc and implement it in future.
doc/fluid/design/dist_train/src/prefetch_parameters.graffle
浏览文件 @
f839e91b
无法预览此类型文件
doc/fluid/design/dist_train/src/split_parameter.graffle
浏览文件 @
f839e91b
无法预览此类型文件
doc/fluid/design/dist_train/src/split_parameter.png
查看替换文件 @
b3827473
浏览文件 @
f839e91b
67.5 KB
|
W:
|
H:
76.9 KB
|
W:
|
H:
2-up
Swipe
Onion skin
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}