Merge branch 'develop' of https://github.com/PaddlePaddle/Paddle into add_clip_op
Showing
Dockerfile.android
已删除
100644 → 0
cmake/external/nnpack.cmake
已删除
100644 → 0
cmake/external/swig.cmake
已删除
100644 → 0
doc/CMakeLists.txt
已删除
100644 → 0
doc/about/about_us.rst
已删除
100644 → 0
doc/mobile/CMakeLists.txt
已删除
100644 → 0
doc/mobile/index_cn.rst
已删除
100644 → 0
doc/mobile/index_en.rst
已删除
100644 → 0
doc/survey/dynamic_graph.md
已删除
100644 → 0
doc/templates/conf.py.cn.in
已删除
100644 → 0
doc/templates/conf.py.en.in
已删除
100644 → 0
doc/templates/layout.html
已删除
100644 → 0
doc/v2/CMakeLists.txt
已删除
100644 → 0
doc/v2/api/CMakeLists.txt
已删除
100644 → 0
doc/v2/api/config/attr.rst
已删除
100644 → 0
doc/v2/api/config/layer.rst
已删除
100644 → 0
doc/v2/api/config/pooling.rst
已删除
100644 → 0
doc/v2/api/data.rst
已删除
100644 → 0
doc/v2/api/data/dataset.rst
已删除
100644 → 0
doc/v2/api/data/image.rst
已删除
100644 → 0
doc/v2/api/index_en.rst
已删除
100644 → 0
doc/v2/api/model_configs.rst
已删除
100644 → 0
doc/v2/api/overview.rst
已删除
100644 → 0
doc/v2/api/run_logic.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
39.3 KB
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}

179.1 KB
{kind=link}
33.1 KB
文件已删除
{kind=link}
10.6 KB
文件已删除
{kind=link}
42.4 KB
文件已删除
{kind=link}
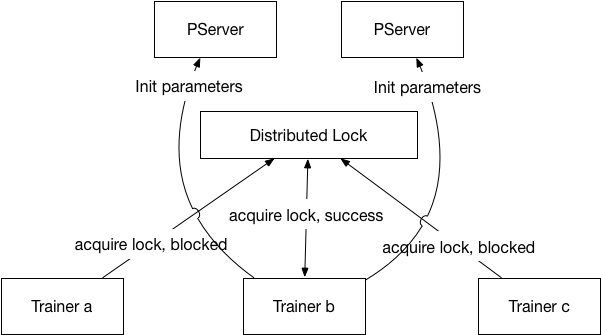
26.1 KB
{kind=link}
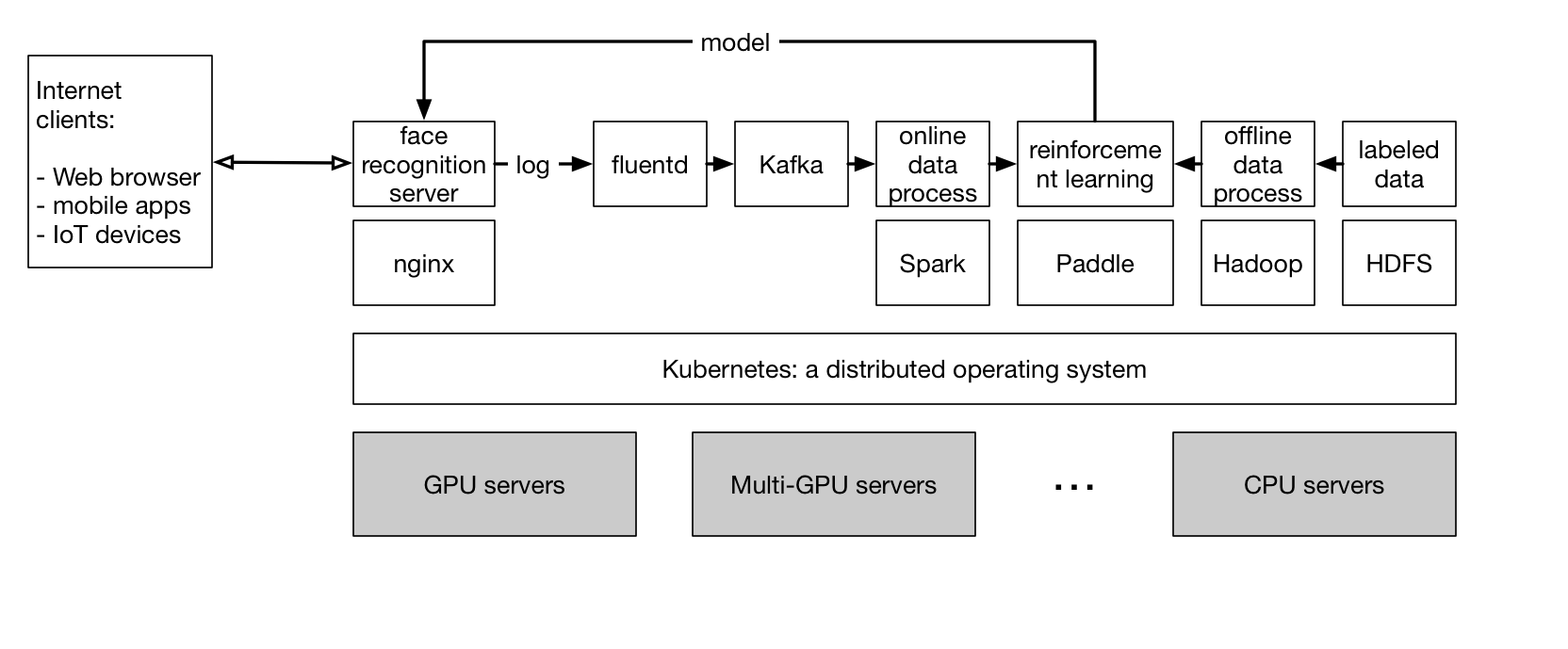
76.7 KB
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
doc/v2/design/mkl/mkldnn.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/v2/dev/index_cn.rst
已删除
100644 → 0
此差异已折叠。
doc/v2/dev/index_en.rst
已删除
100644 → 0
此差异已折叠。
doc/v2/dev/new_layer_cn.rst
已删除
100644 → 0
此差异已折叠。
doc/v2/dev/new_layer_en.rst
已删除
100644 → 0
此差异已折叠。
{kind=link}
此差异已折叠。
doc/v2/dev/src/doc_en.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/v2/dev/write_docs_cn.rst
已删除
100644 → 0
此差异已折叠。
doc/v2/dev/write_docs_en.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/v2/faq/index_cn.rst
已删除
100644 → 0
此差异已折叠。
doc/v2/faq/index_en.rst
已删除
100644 → 0
此差异已折叠。
doc/v2/faq/local/index_cn.rst
已删除
100644 → 0
此差异已折叠。
doc/v2/faq/local/index_en.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/v2/faq/model/index_cn.rst
已删除
100644 → 0
此差异已折叠。
doc/v2/faq/model/index_en.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/v2/howto/index_cn.rst
已删除
100644 → 0
此差异已折叠。
doc/v2/howto/index_en.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/v2/howto/rnn/index_cn.rst
已删除
100644 → 0
此差异已折叠。
doc/v2/howto/rnn/index_en.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc/v2/images/bi_lstm.jpg
已删除
100644 → 0
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc/v2/images/create_efs.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/v2/images/csr.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc/v2/images/dataset.graffle
已删除
100644 → 0
此差异已折叠。
doc/v2/images/dataset.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/v2/images/doc_en.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/v2/images/efs_mount.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc/v2/images/engine.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/v2/images/gradients.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
此差异已折叠。
doc/v2/images/init_lock.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc/v2/images/layers.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc/v2/images/matrix.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/v2/images/nvvp1.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/v2/images/nvvp2.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/v2/images/nvvp3.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/v2/images/nvvp4.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/v2/images/overview.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
doc/v2/images/paddle-etcd.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
doc/v2/images/paddle-ps-0.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/v2/images/paddle-ps-1.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
doc/v2/images/ps_cn.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/v2/images/ps_en.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/v2/images/submit-job.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/v2/images/trainer.graffle
已删除
100644 → 0
此差异已折叠。
doc/v2/images/trainer.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
doc/v2/images/trainer_cn.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc/v2/index_cn.rst
已删除
100644 → 0
此差异已折叠。
doc/v2/index_en.rst
已删除
100644 → 0
此差异已折叠。
go/.gitignore
已删除
100644 → 0
此差异已折叠。
go/CMakeLists.txt
已删除
100644 → 0
此差异已折叠。
go/cmd/master/CMakeLists.txt
已删除
100644 → 0
此差异已折叠。
go/cmd/master/master.go
已删除
100644 → 0
此差异已折叠。
go/cmd/pserver/.gitignore
已删除
100644 → 0
此差异已折叠。
go/cmd/pserver/CMakeLists.txt
已删除
100644 → 0
此差异已折叠。
go/cmd/pserver/pserver.go
已删除
100644 → 0
此差异已折叠。
go/connection/conn.go
已删除
100644 → 0
此差异已折叠。
go/master/c/CMakeLists.txt
已删除
100644 → 0
此差异已折叠。
go/master/c/client.go
已删除
100644 → 0
此差异已折叠。
go/master/client.go
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
go/master/client_test.go
已删除
100644 → 0
此差异已折叠。
go/master/etcd_client.go
已删除
100644 → 0
此差异已折叠。
go/master/inmem_store.go
已删除
100644 → 0
此差异已折叠。
go/master/service.go
已删除
100644 → 0
此差异已折叠。
go/master/service_test.go
已删除
100644 → 0
此差异已折叠。
go/proto/.gitignore
已删除
100644 → 0
此差异已折叠。
go/pserver/CMakeLists.txt
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
go/pserver/client/client.go
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
go/pserver/etcd_client.go
已删除
100644 → 0
此差异已折叠。
go/pserver/optimizer.go
已删除
100644 → 0
此差异已折叠。
go/pserver/optimizer_test.go
已删除
100644 → 0
此差异已折叠。
go/pserver/service.go
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
go/pserver/service_test.go
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/imperative/README.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/legacy/api/Internal.h
已删除
100644 → 0
此差异已折叠。
paddle/legacy/api/Matrix.cpp
已删除
100644 → 0
此差异已折叠。
paddle/legacy/api/Paddle.i
已删除
100644 → 0
此差异已折叠。
paddle/legacy/api/PaddleAPI.h
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/legacy/api/Trainer.cpp
已删除
100644 → 0
此差异已折叠。
paddle/legacy/api/Util.cpp
已删除
100644 → 0
此差异已折叠。
paddle/legacy/api/Vector.cpp
已删除
100644 → 0
此差异已折叠。
paddle/legacy/api/__init__.py
已删除
100644 → 0
此差异已折叠。
paddle/legacy/api/numpy.i
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/legacy/capi/Main.cpp
已删除
100644 → 0
此差异已折叠。
paddle/legacy/capi/Matrix.cpp
已删除
100644 → 0
此差异已折叠。
paddle/legacy/capi/Vector.cpp
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
paddle/legacy/capi/capi.h
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/legacy/capi/error.cpp
已删除
100644 → 0
此差异已折叠。
paddle/legacy/capi/error.h
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/legacy/capi/main.h
已删除
100644 → 0
此差异已折叠。
paddle/legacy/capi/matrix.h
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/legacy/capi/vector.h
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。