When we do distribute multi GPU training, the communication overhead between servers become the major bottleneck, because of the following reasons:
1. Must copy at least once from GPU to CPU memory so that the data can be ready to transfer. And for the pserver side, copy data from CPU to GPU introduce more overhead.
2. GPU->CPU data transfer is 10 times slower than data transfer between GPUs or between PCIe devices.
3. TCP connections can not make full use of RDMA 100Gb devices.
We will use OpenMPI API to PaddlePaddle, which can bring two benefits to PaddlePaddle:
1. Enable RDMA with PaddlePaddle, which bring high-performance low latency networks.
2. Enable GPUDriect with PaddlePaddle, which bring the highest throughput and lowest latency GPU read and write.
# Change list
* Compile args: Need add compile args to enable MPI support.
* Execute args: Need add execute args to assign when and how to use MPI operations.
* New ops: Need new op ```mpi_send_op``` and ```mpi_listenandserve_op``` to support MPI send and receive.
* Transpiler optimized: Which can add ```mpi_send_op``` and ```mpi_listenandserve_op``` to the running graph.
* MPI utils package: Need MPI utils package as the low-level API supported.
## Compile args
Because MPI or CUDA need hardware supported, so we will add compile args to enable MPI support and control compiling.Add ```WITH_MPI``` compile args to control MPI to use or not. If the ```WITH_MPI``` is ```ON```, compile system will find openMPI codes in configuration. We should prepare openMPI environment before compiling.
## Execute args
Launch the script using the ```mpirun``` launcher, For example: ```mpirun -np 3 -hosts node1,node2,node3 python train.py```. By doing this, We can number the actors (trainer/pserver/master) with o .. (n-1). The node's number is the Rank of the calling process in a group of comm (integer), The MPI processes identify each other using a Rank ID. We have to create a mapping between PaddlePaddle's nodes and their Rank ID so that we can communicate with the correct destinations when using MPI operations.
## New ops
We won't replace all the gRPC requests to MPI requests, the standard gRPC library is used for all administrative operations and the MPI API will be used to transfer tensor or selectRows to Pservers. The base of this idea, we create two new operators to handle requests and receives, the two operators are ```mpi_send_op``` and ```mpi_listenandserve_op```. They are a little similar to [send_op](https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/fluid/operators/send_op.cc) and [listen_and_serv_op](https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/fluid/operators/listen_and_serv_op.cc), also, We will build a new module to package MPI send and receive process.
### mpi_send_op
Very similar with ```send_op```, we will replace gRPC code which used to send gradient with ```mpi_module```, at the same time, we will wrap it with ```framework::Async```.
### mpi_listenandserve_op
Very similar with ```listen_and_serv_op```, we will replace gRPC code which used to receive gradient with ```mpi_module```, at the same time, we will wrap it with ```framework::Async```.
## Transpiler optimized
**We can get env ```OMPI_COMM_WORLD_SIZE``` and ```OMPI_COMM_WORLD_RANK``` to distinguish use MPI or not, If we use openMPI, the variable in env must exist.**
if confirm to use MPI, we will modify ```send_op``` to ```mpi_send_op``` in distribute_transpiler, and modify ```listenandserve_op``` to ```mpi_listenandserve_op``` also.
## MPI utils package
In this package, We will write openMPI low-level API to use MPI.
The API included in this package are:
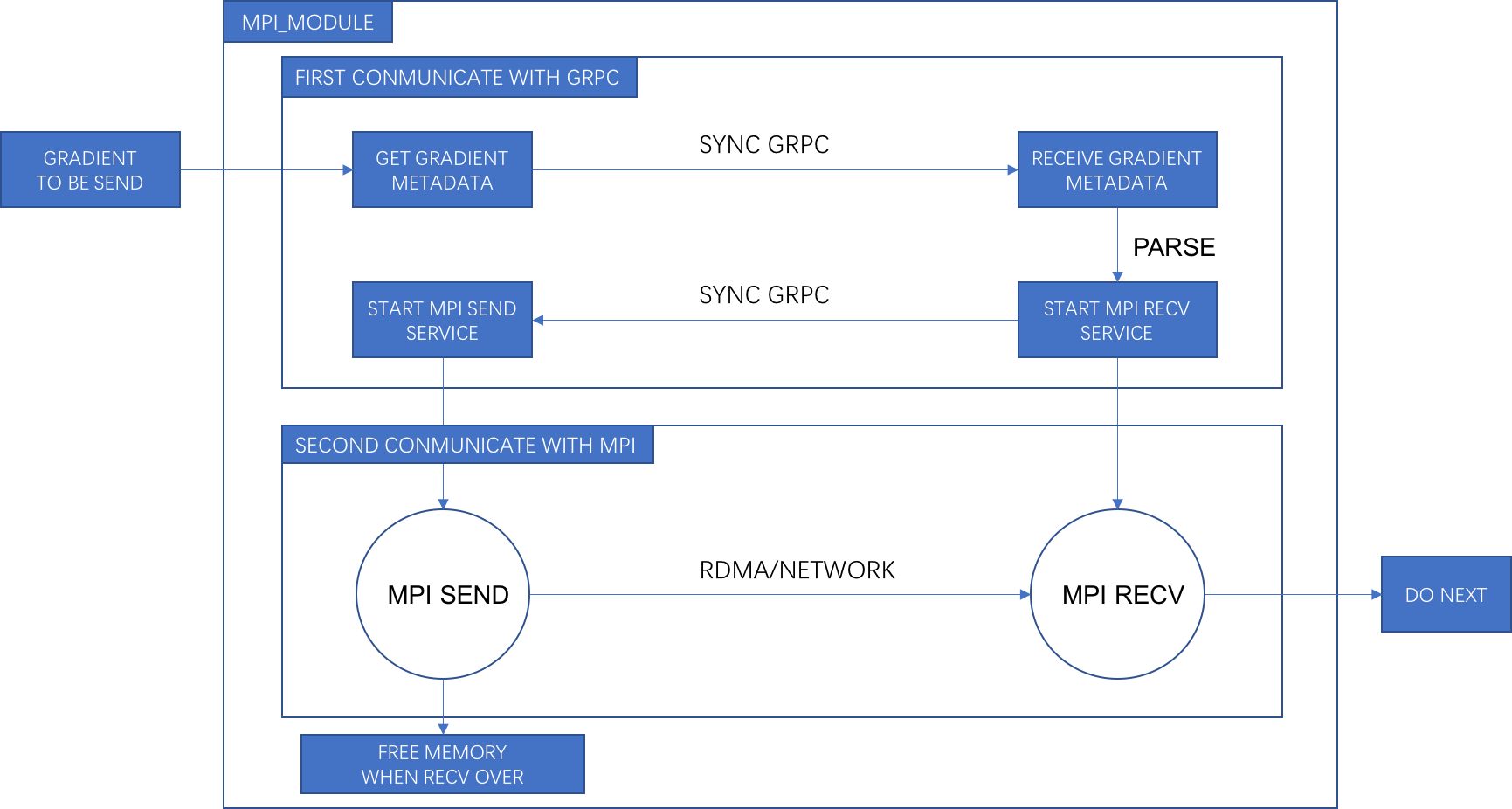
* MPI send and receive module, We will build a new module to package MPI send and receive process. MPI send and receive are different to gRPC, the MPI [recvice](https://www.open-mpi.org/doc/v1.8/man3/MPI_Irecv.3.php) must know receive buffer size and receive buffer element. For this reason, We have to make communications twice, the first one is to send metadata about gradient through gRPC, the second one is the real communication through MPI which send gradient data to mpi_listenandserve_op.
{kind=link}